本文转载自微信公众号「微观技术」,作者Tom哥 。转载本文请联系微观技术公众号。
大家好,我是Tom哥~
MySQL 数据库大家一定都不陌生,今天跟大家聊聊数据同步的事
关于数据同步,我们常见的策略就是 同步双写、异步消息
1、同步双写:字面意思,同步+双写。比如老库模型重构,数据迁移到新库,迁移过程中,如果有数据变更,既要写到老库,也要写到新库,两边同步更新。
- 优点:同步机制,保证了数据的实效性。
- 缺点:额外增加同步处理逻辑,会有性能损耗
2、异步消息:如果依赖方过多,我们通常是将变更数据异构发送到MQ消息系统,感兴趣的业务可以订阅消息Topic,拉取消息,然后按自己的业务逻辑处理。
- 优点:架构解耦,可以采用异步来做,降低主链路的性能损耗。如果是多个消费方,不会出现指数性能叠加
- 缺点:异步机制,无法满足实时性,有一定延迟。只能达到最终一致性。
上面两种方案,都是采用硬编码,那么有没有通用的技术方案。不关心你是什么业务,写入什么数据,对平台来讲可以抽象成一张张 MySQL 表,直接同步表数据。只有使用方才真正去关心数据内容。
可以参考 MySQL 的主从同步原理,拉取 binlog,只要将里面的数据解析出来即可。
流行的中间件是阿里开源的 Canal,今天我们就来做个技术方案,大概内容如下:
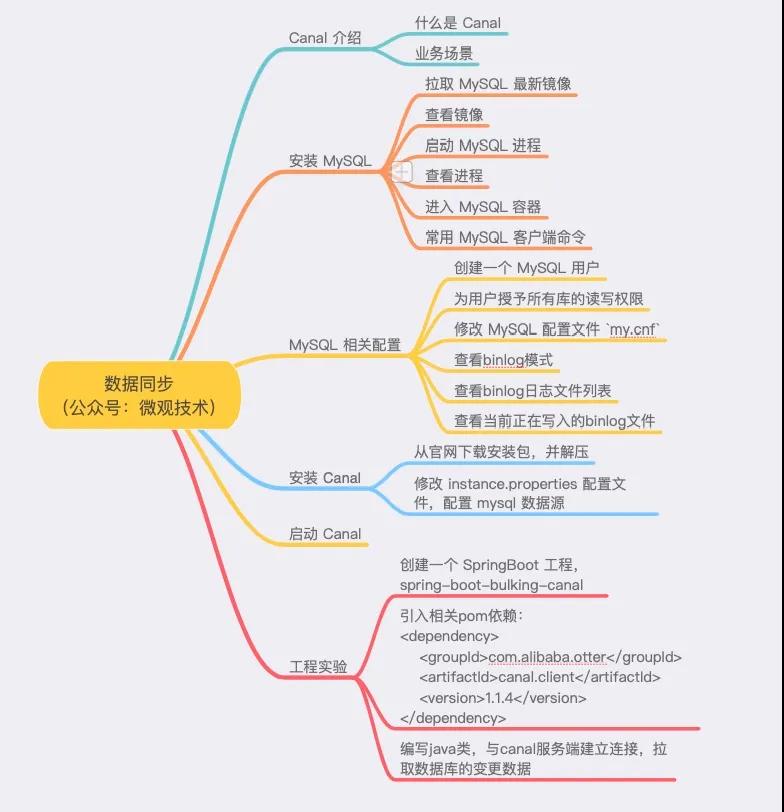
一、Canal 介绍
Canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
Canal 诞生之初是为了解决多个备库与主库间数据同步,对主库造成的压力。
慢慢的,这个管道被发扬光大,应用场景也越来越多
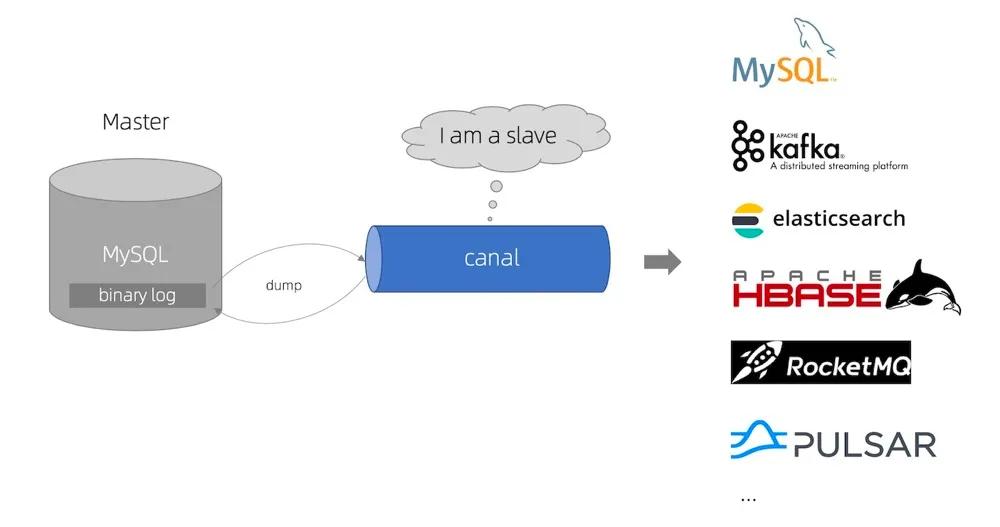
工作原理很简单,把自己伪装成 MySQL 的 slave,模拟 MySQL slave 的交互协议向 MySQL master 发送 dump 请求。
MySQL master 收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binlog 日志,再存储到不同的存储介质中,比如:MySQL、Kafka、Elastic Search、Pulsar 等
业务场景:
- 数据库实时备份
- ES 数据索引的构建和维护
- 分布式缓存(如:Redis)的同步维护
- 数据异构,订阅方可以按自己的业务需求订阅消费,如:Kafka、Pulsar 等
二、安装 MySQL
1、拉取 MySQL 镜像
docker pull mysql:5.7
- 1.
2、查看镜像
docker images
- 1.
3、启动 MySQL 进程
docker run \
--name mysql \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:5.7
- 1.
- 2.
- 3.
- 4.
- 5.
4、查看进程
[root@iZbp12gqydkgwid86ftoauZ mysql]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e92827897538 mysql "docker-entrypoint.s…" 4 seconds ago Up 2 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp mysql
- 1.
- 2.
- 3.
5、进入 MySQL 容器
docker exec -it 167bfa3785f1 /bin/bash
- 1.
注意:修改一些配置文件,可能会遇到一些问题,如:
docker容器中使用vi或vim提示bash: vi: command not found的处理方法
因为没有安装vi编辑器,可以执行下面命令
apt-get update
apt-get install vim
- 1.
- 2.
6、常用 MySQL 客户端命令
# 登陆 mysql
mysql -uroot -p111111
# 显示数据库列表
show databases;
# 选择数据库
use mysql;
# 显示所有表
show tables;
# 显示表结构
describe 表名;
其他更多命令:
https://www.cnblogs.com/bluecobra/archive/2012/01/11/2318922.html
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
三、MySQL 相关配置
创建一个 MySQL 用户,用户名:tom ,密码:123456
create user 'tom'@'%' identified by '123456';
- 1.
为用户:tom 授予所有库的读写权限
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'tom'@'%' identified by '123456';
- 1.
修改 MySQL 配置文件 my.cnf,位置:/etc/my.cnf
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 行 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
- 1.
- 2.
- 3.
- 4.
注意:需要重启MySQL容器实例,执行命令 docker restart mysql
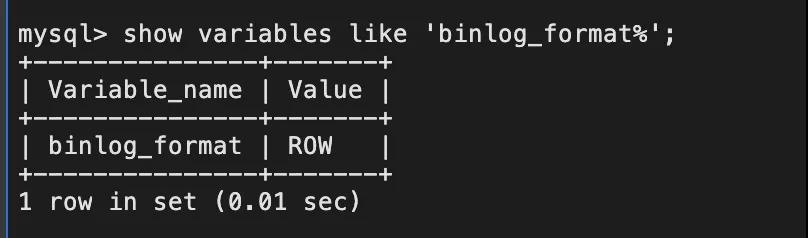
查看binlog模式:
查看binlog日志文件列表:
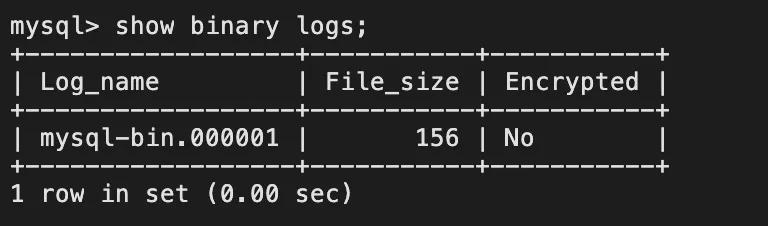
查看当前正在写入的binlog文件:

四、安装 Canal
1、从官网下载安装包
下载地址:
https://github.com/alibaba/canal/releases
本文实验用的是最新版本 v1.1.5,主要是对不同的客户端的个性化支持,属于生态扩展。
其他更多特性,大家可以去官网查看
解压 tar.gz 压缩包
tar -zxvf canal.deployer-1.1.5.tar.gz
- 1.
打开配置文件 conf/example/instance.properties,修改配置如下:
## v1.0.26版本后会自动生成slaveId,所以可以不用配置
# canal.instance.mysql.slaveId=0
# 数据库地址
canal.instance.master.address=127.0.0.1:3306
# binlog日志名称
canal.instance.master.journal.name=mysql-bin.000001
# mysql主库链接时起始的binlog偏移量
canal.instance.master.position=156
# mysql主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
canal.instance.master.gtid=
# username/password
# 在MySQL服务器授权的账号密码
canal.instance.dbUsername=root
canal.instance.dbPassword=111111
# 字符集
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
# table regex .*\\..*表示监听所有表 也可以写具体的表名,用,隔开
canal.instance.filter.regex=.*\\..*
# mysql 数据解析表的黑名单,多个表用,隔开
canal.instance.filter.black.regex=
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
启动命令
./startup.sh
- 1.
由于采用的阿里云的 ECS 服务器,发现没有安装 JAVA 环境。
Oracle 官网下载 JDK 8 的安装包
下载地址:
https://www.oracle.com/java/technologies/downloads/#java8
然后,通过下面的命令将安装包上传到 ECS 服务器
scp jdk-8u311-linux-x64.tar.gz root@118.31.168.234:/root/java //上传文件
- 1.
安装 JDK 8 环境
文档:https://developer.aliyun.com/article/701864
五、启动 Canal
进入 canal.deployer-1.1.5/bin
执行启动脚本:
./startup.sh
- 1.
进入 canal.deployer-1.1.5/logs/example
如果 example.log 日志文件中,出现下面的内容,表示启动成功
2022-01-03 08:23:10.165 [canal-instance-scan-0] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - stop CannalInstance for null-example
2022-01-03 08:23:10.177 [canal-instance-scan-0] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - stop successful....
2022-01-03 08:23:10.298 [canal-instance-scan-0] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2022-01-03 08:23:10.298 [canal-instance-scan-0] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
2022-01-03 08:23:10.298 [canal-instance-scan-0] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$
2022-01-03 08:23:10.299 [canal-instance-scan-0] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
六、工程实验
创建一个 SpringBoot 工程,spring-boot-bulking-canal
引入相关pom依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
编写java类,与 canal 服务端 建立连接,拉取数据库的变更数据
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
//打开连接
connector.connect();
//订阅全部表
connector.subscribe(".*\\..*");
//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(BATCH_SIZE);
long batchId = message.getId();
printEntry(message.getEntries());
// batch id 提交
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
在 ds1 数据库下创建 MySQL 表
CREATE TABLE `person` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`income` bigint(20) NOT NULL COMMENT '收入',
`expend` bigint(20) NOT NULL COMMENT '支出',
PRIMARY KEY (`id`),
KEY `idx_income` (`income`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='个人收支表';
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
插入一条记录:
insert into person values(100,1000,1000);
- 1.
Java类解析binlog,在控制台打印变更日志:
binlog[mysql-bin.000002:1946] , table[ds1,person] , eventType : INSERT
id : 100 update=true
income : 1000 update=true
expend : 1000 update=true
- 1.
- 2.
- 3.
- 4.
对 id=100 记录做修改:
update person set income=2000, expend=2000 where id=100;
- 1.
控制台打印变更日志:
binlog[mysql-bin.000002:2252] , table[ds1,person] , eventType : UPDATE
------->; before
id : 100 update=false
income : 1000 update=false
expend : 1000 update=false
------->; after
id : 100 update=false
income : 2000 update=true
expend : 2000 update=true
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.