














在写爬虫的过程中,我们经常需要解析网站的列表页。例如下面这个例子:
- <html>
- <head>
- <meta charset="utf-8">
- <title>测试相对路径</title>
- </head>
- <body>
- <div>
- <h1>书籍列表</h1>
- <ul>
- <li><a href="http://127.0.0.1:8000/book/1.html">第一本书</a></li>
- <li><a href="http://127.0.0.1:8000/book/2.html">第二本书</a></li>
- <li><a href="http://127.0.0.1:8000/book/3.html">第三本书</a></li>
- <li><a href="http://127.0.0.1:8000/book/4.html">第四本书</a></li>
- <li><a href="http://127.0.0.1:8000/book/5.html">第五本书</a></li>
- </ul>
- </div>
- </body>
- </html>
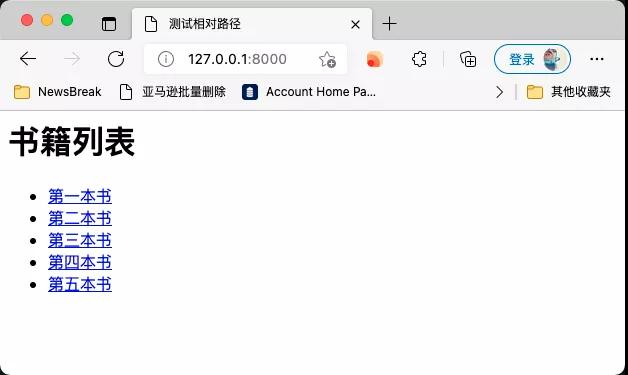
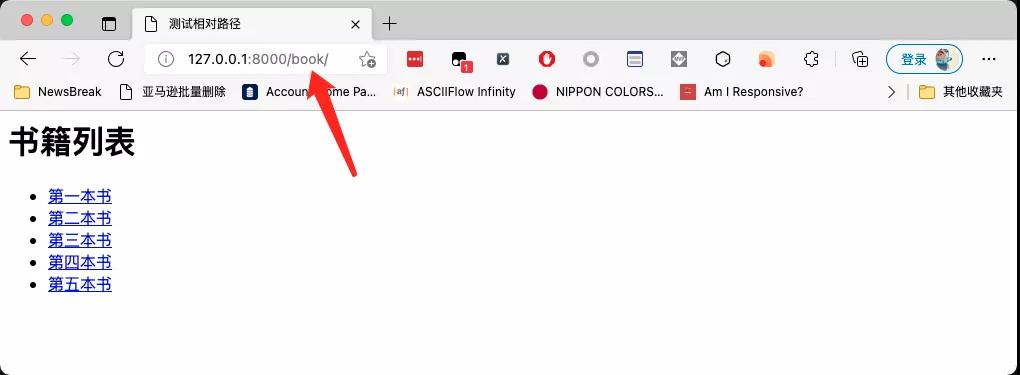
运行效果如下图所示:
这种情况下,我想获取每一项的URL非常简单,直接写一个XPath就可以了,如下图所示:
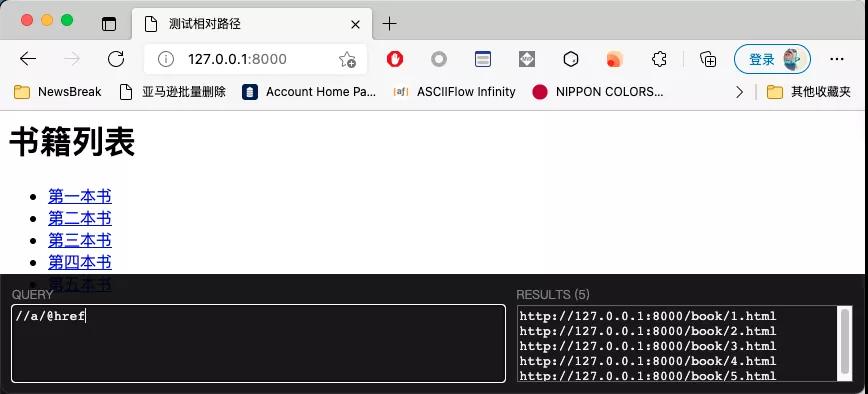
仔细观察你会发现,每一个连接的URL都是以http://127.0.0.1:8000开头的。而当前列表页的地址也是http://127.0.0.1:8000。所以为了简单起见,标签里面可以使用相对路径:
- <html>
- <head>
- <meta charset="utf-8">
- <title>测试相对路径</title>
- </head>
- <body>
- <div>
- <h1>书籍列表</h1>
- <ul>
- <li><a href="/book/1.html">第一本书</a></li>
- <li><a href="/book/2.html">第二本书</a></li>
- <li><a href="/book/3.html">第三本书</a></li>
- <li><a href="/book/4.html">第四本书</a></li>
- <li><a href="/book/5.html">第五本书</a></li>
- </ul>
- </div>
- </body>
- </html>
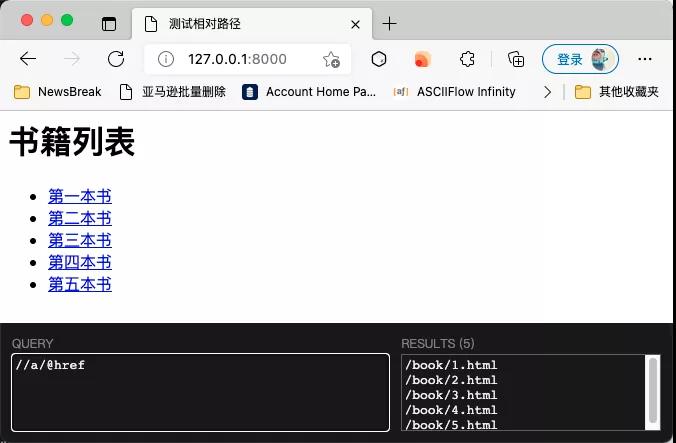
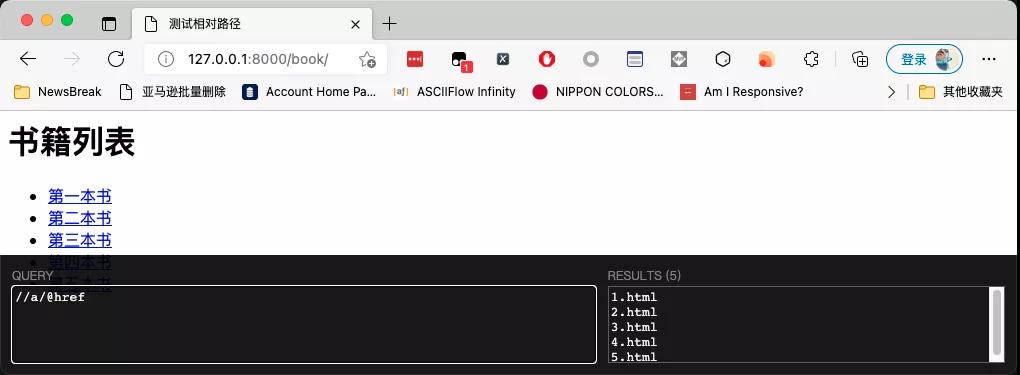
运行效果如下图所示,用XPath只能提取到半截URL:
但是浏览器可以正确识别这样的相对地址,并且当你点击的时候,它能自动跳转到正确的地址:
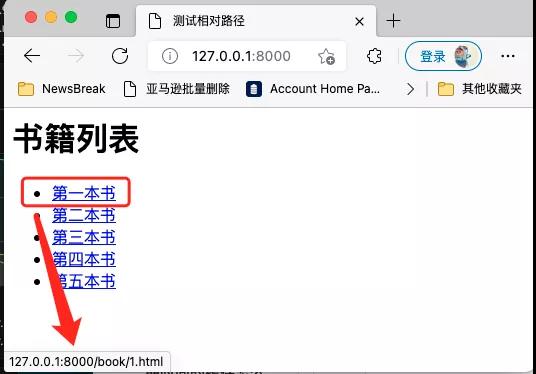
相对路径如果是以/开头,那么就会在相对路径前面拼接上网站的主域名。
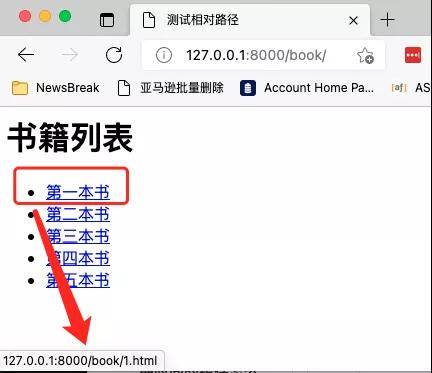
但如果当前列表页的地址跟链接的相对路径有一部分重叠怎么办?如下图所示:
当前页面的地址是http://127.0.0.1:8000/book。而相对地址是/book/1.html。这种情况下,还可以进一步简化,在相对路径的前面不要加斜杠,把HTML改成:
- <html>
- <head>
- <meta charset="utf-8">
- <title>测试相对路径</title>
- </head>
- <body>
- <div>
- <h1>书籍列表</h1>
- <ul>
- <li><a href="1.html">第一本书</a></li>
- <li><a href="2.html">第二本书</a></li>
- <li><a href="3.html">第三本书</a></li>
- <li><a href="4.html">第四本书</a></li>
- <li><a href="5.html">第五本书</a></li>
- </ul>
- </div>
- </body>
- </html>
运行效果如下图所示:
这种情况下,浏览器依然能给正确识别,如下图所示:
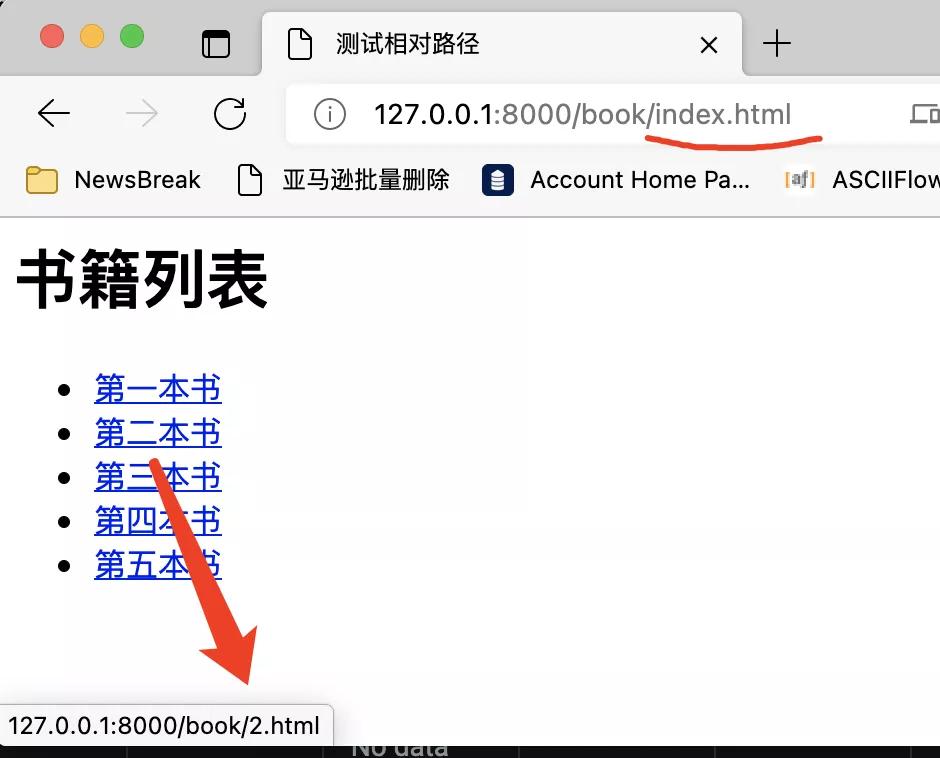
浏览器知道,如果相对路径没有用/开头,那么它就会把当前页面的URL与相对路径拼接起来。但需要注意的是,在拼接的时候,会取最右侧斜杠左边的部分。而右边的部分会丢弃。就相当于拼接文件地址的时候,用这个文件所在的文件夹来拼接新的地址。如下图所示:
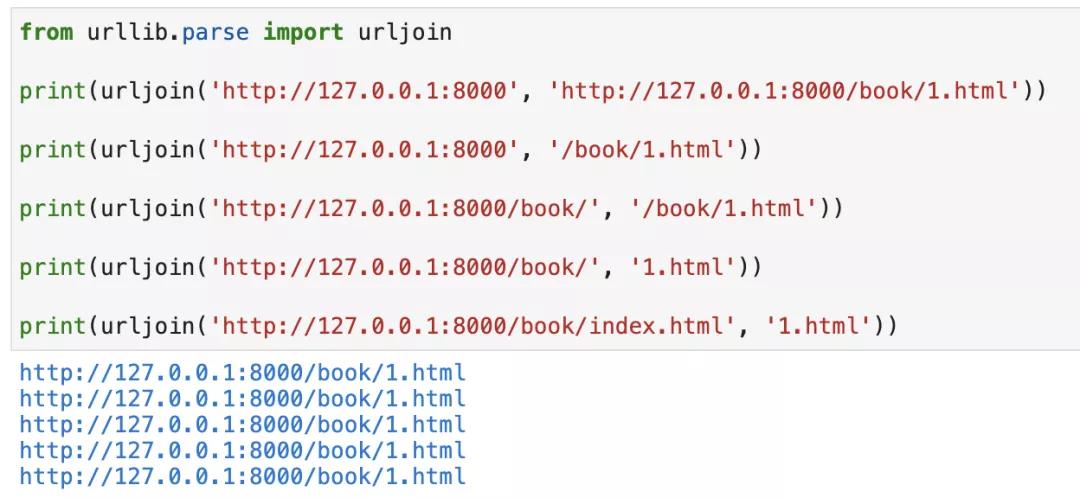
如果你记不住怎么区分的话,你可以使用Python自带的urllib.parse.urljoin来连接,如下图所示:
看到这里,你可能觉得我今天又水了一篇文章。这么简单的东西也值得写一篇文章来讲?
那么我们来看下面这个例子:
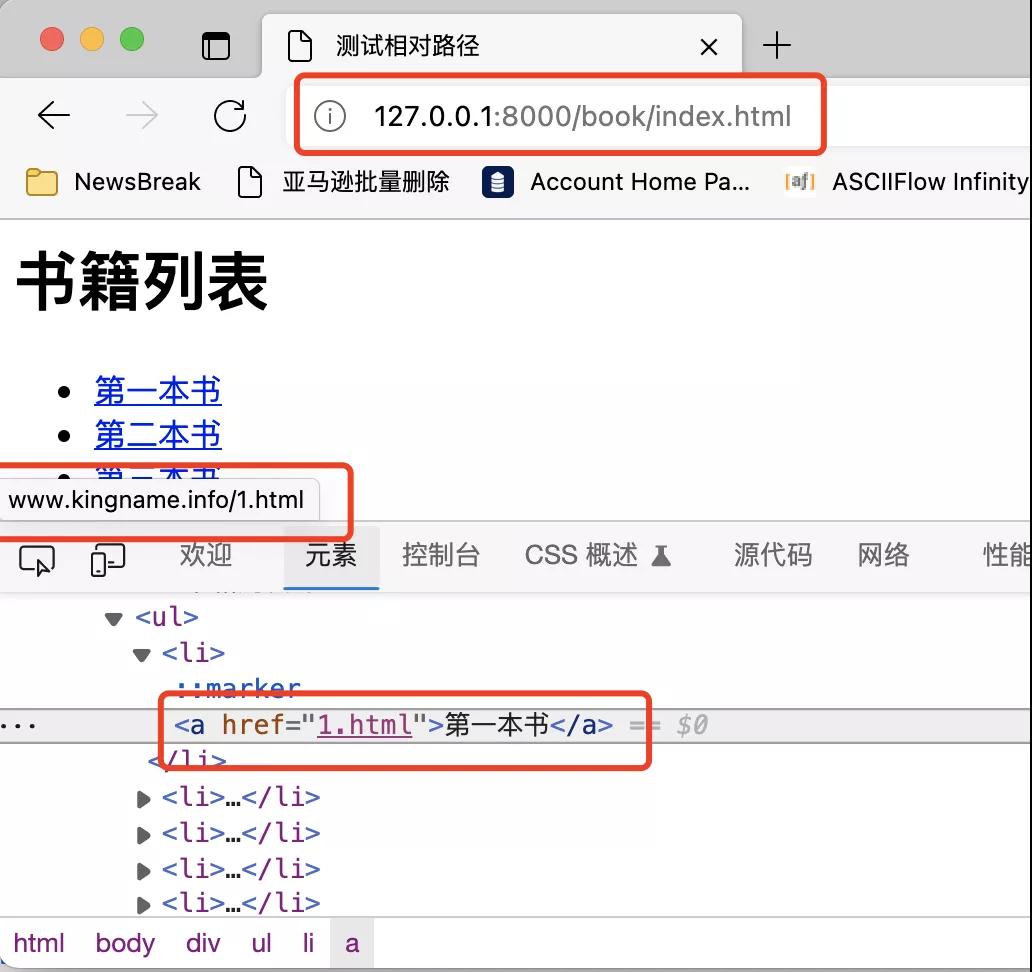
域名是http://127.0.0.1:8000/book/index.html,相对域名是1.html,但为什么浏览器自动识别出来的URL是www.kingname.info/1.html?
这个问题的关键,在于源代码里面的标签:
- <html>
- <head>
- <meta charset="utf-8">
- <title>测试相对路径</title>
- <base href="http://www.kingname.info">
- </head>
- <body>
- <div>
- <h1>书籍列表</h1>
- <ul>
- <li><a href="1.html">第一本书</a></li>
- <li><a href="2.html">第二本书</a></li>
- <li><a href="3.html">第三本书</a></li>
- <li><a href="4.html">第四本书</a></li>
- <li><a href="5.html">第五本书</a></li>
- </ul>
- </div>
- </body>
- </html>
如果HTML代码头部有标签,那么,它的href属性的值,会被用来跟相对路径拼接出一个绝对路径,而不会再用当前页面的URL来拼接。
如果你不知道这一点的话,你的爬虫在拼接子页面URL的时候可能就会出问题。网站也可以使用这个机制构造出一个蜜罐,根据标签拼出来的URL才是真正的子页面地址,而用当前页面URL去拼接的URL是蜜罐地址,爬虫访问进去以后,就会抓到假数据,或者被立即屏蔽。
关于标签的详细说明,大家可以阅读:: The Document Base URL element[1]。
参考文献
[1] The Document Base URL element: https://developer.mozilla.org/en-US/docs/Web/HTML/Element/base




















