














大家好,我是小风哥。
假定给你一块非常小的内存,这块内存只有8字节,这里也没有高级语言,没有操作系统,你操作的数据单位是单个字节,你该怎样读写这块内存呢?
注意这里的限定,再读一遍,没有高级语言,没有操作系统,在这样的限制之下,你必须直面内存读写的本质。
这个本质是什么呢?
本质是你需要意识到内存就是一个一个装有字节的小盒子,这些小盒子从0到N编好了序号。
这时如果你想计算1+2,那么你必须先把1和2分别放到两个小盒子中,假设我们使用Store指令,把数字1放到第6号小盒子,那么用指令表示就是这样:
- store 1 6
注意看这条指令,这里出现了两个数字:1和6,虽然都是数字,但这两个数字的含义是不同的,一个代表数值,一个代表内存地址。
与写对应的是读,假设我们使用load指令,就像这样:
- load r1 6
现在依然有一个问题,这条指令到底是数字6写入r1寄存器还是把第6号小盒子中装的数字写入r1寄存器?
可以看到,数字在这里是有歧义的,它既可以表示数值也可以表示地址,为加以区分我们需要给数字添加一个标识,比如对于前面加上$符号的就表示数值,否则就是地址:
- store $1 6
- load r1 6
这样就不会有歧义了。
现在第6号内存中装入了数值1:
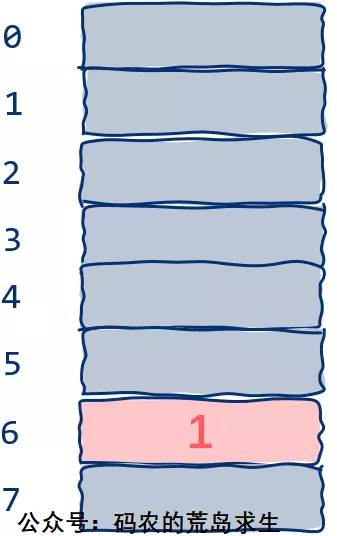
即地址6代表数字1:
- 地址6 -> 数字1
但“地址6”对人类来说太不友好了,人类更喜欢代号,也就是起名字,假设我们给“地址6”换一个名字,叫做a,a代表的就是地址6,a中存储的值就是1,用人类在代数中直观的表示就是:
- a = 1
就这样所谓的变量一词诞生了。
我们可以看到,从表面上看变量a等价于数值1,但背后还隐藏着一个重要的信息,那就是变量a代表的数字1存储在第6号内存地址上,即变量a或者说符号a背后的含义是:
- 表示数值1
- 该数值存储在第6号内存地址
到现在为止第2个信息好像不太重要,先不用管它。
既然有变量a,就会有变量b,如果有这样一个表示:
- b = a
把a的值给到b,这个赋值在内存中该怎么表示呢?
很简单,我们为变量b也找一个小盒子,假设变量b放在第2号小盒子上:
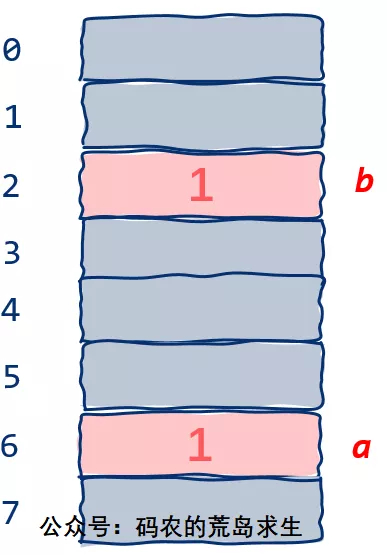
可以看到,我们完全copy了一份变量a的数据。
现在有了变量,接下来让我们升级一下,假设变量a不仅仅可以表示占用1个字节的数据,也可以表示占用任意多内存的数据,就像这样:
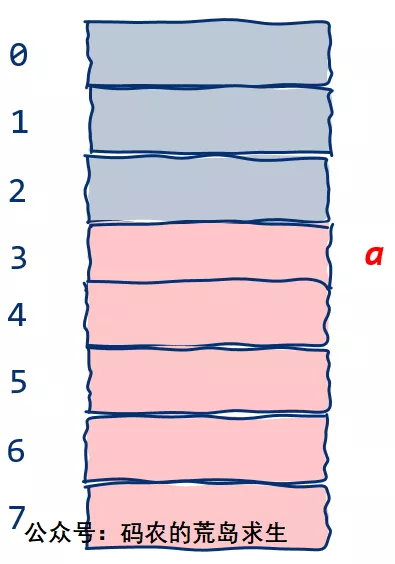
现在变量a占据5个字节,足足占用了整个内存的一大半空间,此时如果我们依然想要表示b = a会怎样呢?
如果你依然采用copy 的方法会发现我们的内存空间已经不够用了,因为整个内存大小就8字节,采用copy的方法仅这两个变量代表的数据就将占据10字节。
怎么办呢?
不要忘了变量a背后可是有两个含义的,再让我们看一下:
- 表示数值1
- 该数值存储在第6号内存地址
重点看一下第2个含义,这个含义告诉我们什么呢?
它告诉我们不管一个变量占据多少内存空间,我们总可以通过它在内存中地址找到该数据,而内存地址仅仅就是一个数字,这个数字和该数据占用空间的大小无关。
啊哈,现在变量的第2个含义终于排上用场了,如果我们想用变量b也去指代变量a,干嘛非要直接copy一份数据呢?直接使用地址就不好了,就像这样:
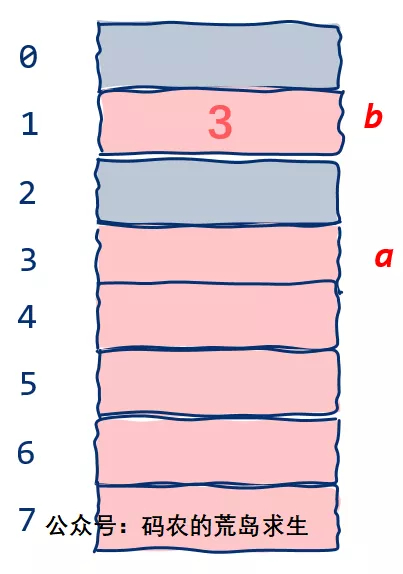
变量a在内存中地址为3,因此变量b中我们可以仅仅存储3这个数字即可。
现在变量b就开始变得非常有趣了。
首先变量b没什么特殊的,只不过变量b存储的东西我们不可以按照数值来解释,而是必须按照地址来解释。
当一个变量不仅仅可以用来保存数值也可以保存内存地址时,指针诞生了。
有很多资料仅仅说指针就是地址,但小风哥认为这是一种偷懒的解释,仅仅停留在汇编层面来理解,有失偏颇,在高级语言中,指针首先是一个变量,只不过这个变量保存的恰好是地址而已,指针是内存地址的更高一级抽象。
如果仅仅把指针理解为内存地址的话你就必须知道所谓的间接寻址。
这是什么意思呢?
如果使用汇编语言来加载变量a的值该怎么写呢?
- load r1 1
想一想,这是不是会有问题,因此这样的话该指令会把数值3加载到r1寄存器中,然而我们想要把内存地址1中保存的数值也解释为内存地址,这时必须为1再次添加一个标识,比如@:
- load r1 @1
这时该指令会首先把内存地址1中保存的值读取出来发现是3,然后再次把3按照内存地址进行解释,3指向的数据就是变了a:
- 地址1 -> 地址3 -> 数据a
这就是所谓的间接寻址,Indirect addressing,在汇编语言下你必须能意识到这一层间接寻址,因为在汇编语言中是没有变量这个概念的。
然而高级语言则不同,这里有变量的概念,此时地址1代表变量b,但使用变量的一个好处就在于很多情况下我们只需要关心其第一个含义,也就是说我们只需要关心变量b中保存了地址3,而不需要关心变量b到底存储在哪里,这样使用变量b时我们就不需在大脑里想一圈间接寻址这一问题了,在程序员的大脑里变量b直接指向数据a:
- b -> 数据a
再来对比一下:
- 地址1 -> 地址3 -> 数据a # 汇编语言层面
- 变量b -> 数据a # 高级语言层面
这就是为什么我说指针其实是内存地址的更高级抽象,这个抽象的目的就在于屏蔽间接寻址。
当变量不仅仅可以存值也可以存放地址时,一个全新的时代到来了:看似松散的内存在内部竟然可以通过指针组织起来,同时这也让程序直接处理复杂的数据结构成为可能,比如就像下图这样:
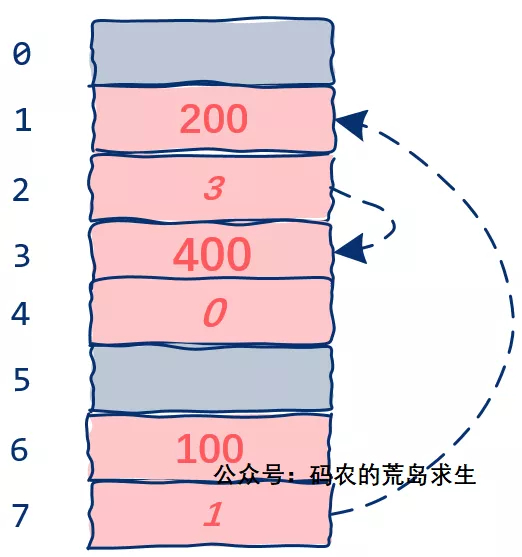
这就是所谓的链表了。

指针这个概念首次出现在 PL/I 语言中,当时是为了增加链表处理能力,大家不要以为链表这种数据结构是非常司空见惯的,这在1964年左右并不是一件容易的事情,关于链表你还可以参考这篇《彻底理解链表》。
值得一提的是,Multics操作系统就是 PL/I 语言实现的,这也是第一个用高级语言实现的操作系统,然而Multics操作系统在商业上并不成功,参与该项目的Ken Thompson, Dennis Ritchie后来决定自己写一个更简单的,Unix以及C语言诞生了,或许是在开发Multic时见识到了PL/I语言中指针的威力,C语言中也有指针的概念。
那么指针在C语言中是一个什么样的概念?为什么说指针威力强大但又破坏性十足?引用和指针又有什么关联?

















