














随着大型数据库的建立和海量数据的不断涌现,人们迫切需要强有力的数据分析工具。但现实情况往往是“数据十分丰富,而信息相当贫乏”。
快速增长的海量数据被收集、存放在大型数据库中,没有强有力的工具,以人类现有的能力很难理解它们。因此,有人说大数据是数据“坟墓”。当采用数据挖掘工具进行数据分析时,可以发现隐藏在大数据之中重要的数据内容、模式,能对商务决策、知识库、科学和医学研究等做出巨大贡献。为解决数据和信息之间的鸿沟,我们应系统地学习数据挖掘知识,开发数据挖掘工具,将数据“坟墓”变成知识“金矿”。
1数据挖掘过程
数据挖掘(data mining)又译为资料探勘、数据采矿,是指从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的但又潜在有用的信息和知识的过程。
数据挖掘的具体过程描述如下:
1)数据:进行数据挖掘首先要有数据,可以根据任务的目的选择数据集,并筛选自己需要的数据,或者根据实际情况构造自己需要的数据。
2)预处理:确定数据集后,就要对数据进行预处理,使数据能够为我们所用。数据预处理可以提高数据质量,包括准确性、完整性和一致性。进行数据预处理的方法有数据清理、数据集成、数据规约和数据变换等。
3)变换:进行数据预处理后,对数据进行变换,将数据转换成一个分析模型,这个分析模型是针对数据挖掘算法建立的。建立一个真正适合数据挖掘算法的分析模型是数据挖掘成功的关键。
4)数据挖掘:对经过转换的数据进行挖掘,除了选择合适的挖掘算法外,其余一切工作都能自动地完成。
5)解释/评估:解释并评估结果,最终得到知识。其使用的分析方法一般视数据挖掘操作而定,通常会用到可视化技术。
数据挖掘的具体过程如图1所示。
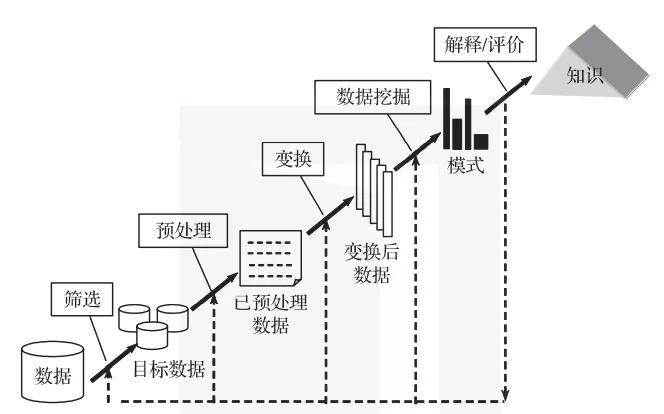
图1 数据挖掘过程
2数据挖掘的内容
2.1 关联规则挖掘
从大规模数据中挖掘对象之间的隐含关系称为关联分析(Associate Analysis)或者关联规则挖掘(Associate Rule Mining),它可以揭示数据中隐藏的关联模式,帮助人们进行市场运作、决策支持等。
考察一些涉及许多物品的事务。事务1中出现了物品甲,事务2中出现了物品乙,事务3中同时出现了物品甲和乙。那么,物品甲和乙在事务中的出现是否有规律可循呢?在数据库的知识发现中,关联规则就是描述这种在一个事务中物品同时出现的规律的知识模式。更确切地说,关联规则通过量化的数字描述物品甲的出现对物品乙的出现有多大的影响。
一般采用可信度、支持度、期望可信度、作用度四个参数来描述一个关联规则的属性。
在关联规则的四个属性中,支持度和可信度能够比较直接地形容关联规则的性质。如果不考虑关联规则的支持度和可信度,那么在事务数据库中可以发现无穷多的关联规则。事实上,人们一般只对满足一定的支持度和可信度的关联规则感兴趣。因此,为了发现有意义的关联规则,需要给定两个阈值:最小支持度和最小可信度,前者规定了关联规则必须满足的最小支持度;后者规定了关联规则必须满足的最小可信度。
经典故事案例:关联规则挖掘经典的案例即为购物篮中的啤酒和尿布的故事。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,在美国有婴儿的家庭中,一般由母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。
比如对于如下购物篮数据:
顾客1:{牛奶、果酱、面包}
顾客2:{牛奶、鸡蛋、面包、糖}
顾客3:{面包、黄油、牛奶}
我们可以推测牛奶→面包为一组关联规则,即顾客购买了牛奶,可以推测该顾客下一步很有可能会购买面包。
2.2 分类
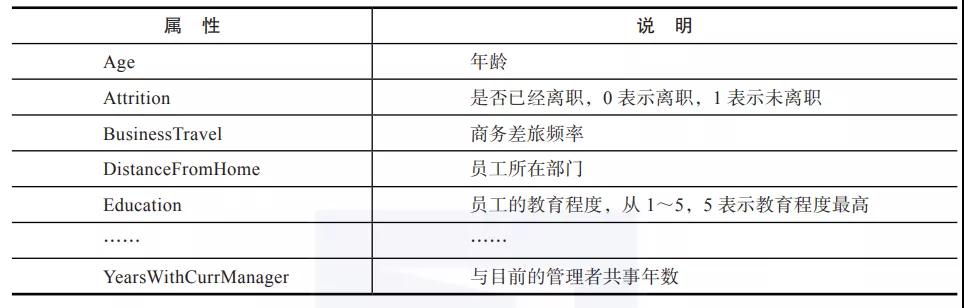
分类算法是数据挖掘中的关键技术,它通过对数据训练集的分析研究,发现分类规则,从而具备预测新数据类型的能力。分类也是监督式机器学习方法,根据训练集学习模型,进一步利用模型对新数据的类别标签进行预测。分类算法主要包括两个阶段:①构建模型阶段,通过分析学习已知的训练数据集,训练并构建一个准确率可以接受的模型,该模型用于描述特定的数据类集;②使用阶段,使用训练后的模型对未知数据对象进行分类。具体过程如下所示。
- 第一步:类别标签学习建模(参见图2)。
- 第二步:类别标签分类测试(参见图3)。
分类标签预测与数值预测的区别如下:数值预测根据训练集学习模型,进一步利用模型对新数据的数值进行预测,区别于分类标签预测,数值预测的输出为连续的数值。

图2 分类学习建模

图3 分类测试
数值预测学习的流程如下。
第一步:数值预测学习建模(参见图4)。
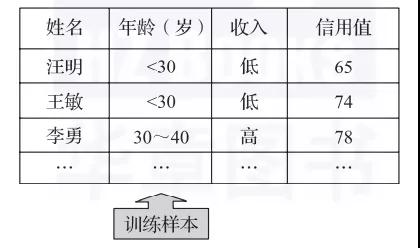
图4 数值预测学习建模
第二步:数值预测测试(参见图5)。
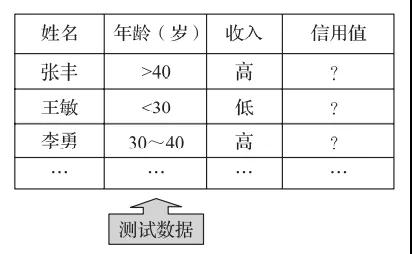
图5 数值预测测试
下面来看一个分类标签预测案例和一个数值预测案例。
(1)分类标签预测案例:员工离职预测
根据给定的影响员工离职的因素和员工是否离职的记录,建立一个模型预测有可能离职的员工,具体数据如表1所示。其中,Attrition表示类别标签,也就是需要预测的离散数据。
表1 员工离职数据
(2)数值预测案例:房价预测
作为一个典型的数值预测案例,房价预测一直备受关注。简言之,房价预测就是综合房屋销售价格以及房屋的基本信息建立模型,从而预测其他房屋的销售价格。
我们以Kaggle平台房价预测的部分数据集(见表2)为例进行说明。如表2所示,房屋的基本信息主要包括建筑等级、区域分类、建筑面积、主路、小巷、房屋外形、平整度、配套设施、房屋位置、地面坡度和销售价格,等等。其中,“销售价格”便是需要预测的连续数值。
表2 Kaggle房价预测数据集示例
2.3 聚类
聚类为非监督式机器学习方法,不需要提供具有标签的训练集,而是直接以某种聚类准则将数据划分到不同类别中。聚类分析的结果通常受聚类准则的影响,图6所示的聚类准则如果设为“花色相同”和“符号相同”,则得到两种不同的聚类结果。
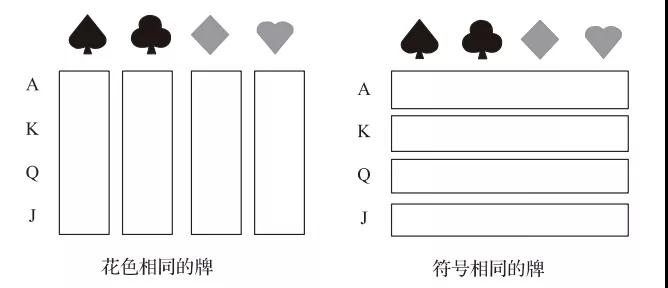
图6 聚类准则影响结果示意
2.4 回归
回归分析(regression analysis)是一个统计预测模型,用于描述和评估应变量与一个或多个自变量之间的关系,包括一元线性回归、多元线性回归、非线性回归、逻辑回归等。具体来说,可以利用回归模型来实现数值预测的任务,比如前面提到的房价预测任务。
当自变量为非随机变量、因变量为随机变量时,分析它们的关系称为回归分析;根据回归分析可以建立变量间的数学表达式,称为回归方程。回归方程反映自变量在固定条件下因变量的平均状态变化情况。相关分析是以某一指标来度量回归方程所描述的各个变量间关系的密切程度。
回归分析方法常用于解释市场占有率、销售额、品牌偏好及市场营销效果。把两个或两个以上定距或定比例的数量关系用函数形式表示出来,就是回归分析要解决的问题。
本文摘编于《数据挖掘:原理与应用》,经出版方授权发布。(书号:9787111696308)转载请保留文章来源。




















