据说,web2.0的魅力在于由静态资源变成交互性资源,web3.0的魅力在于其去中心化的资源,大家都可以参与其中得享时代的福利。但是,无论上层概念玩的再花哨,最下层的通信还是基于web1.0所形成的技术。
我们的终极目标,其实就是打着去中心化的名义,做实际上的中心化。
当流量增加到一定程度,网络编程会发生各种怪异的场景。下面将以十几个实际的案例,来说明xjjdog平常在工作中遇到的与网络相关的高频问题,希望能够助你一臂之力。
1. 大量客户端上线注意躲避
无论你的服务器能力多强,在大批量连接到来,进行业务服务的时候,都会产生瞬时的问题。
举个例子,如果你的MQTT服务器连接了几十万台设备。当你的MQTT服务器宕机重启的时候,就要接受几十万的并发,这几乎没有任何服务能够受得了。
在xjjdog以往的经验中,因为服务端重启问题而造成的阻塞事故,数不胜数。
这个场景,其实和缓存的击穿概念非常的相似。当缓存中的热点数据集中失效的时候,请求就会全部击穿到数据库层面,造成问题。
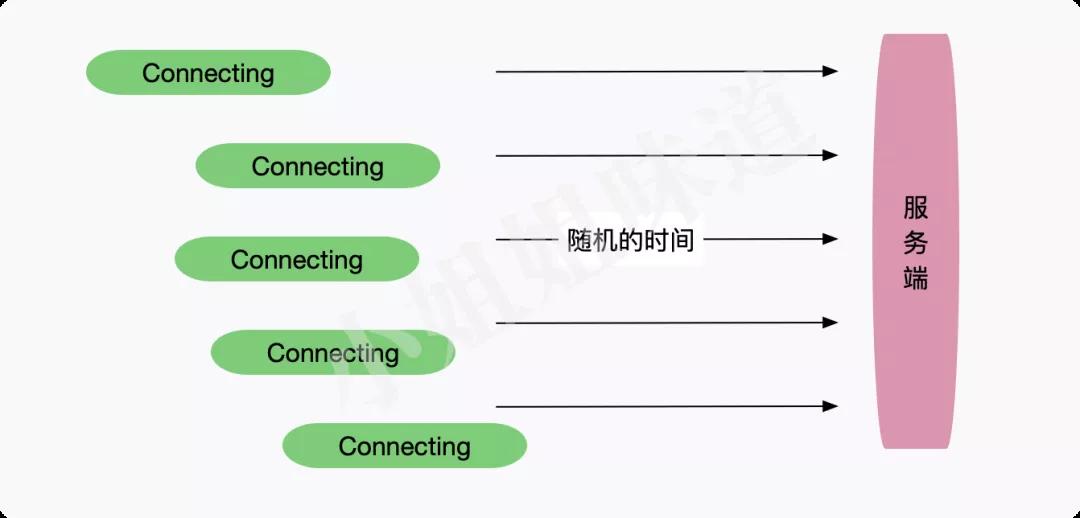
如上图,解决缓存击穿问题就是给每个key加个失效时间的随机值,让它们不要在同一时间失效。类似的,我们可以在客户端重连服务端的时候,加上一个随机的时间。随机数是个好东西,它能让我们的海量连接在随机时间窗口内保持类线性的增长。
2. 多网卡队列
在类似openstack等虚拟平台上假设的虚拟机,往往因为网卡能力不强而造成流量在达到一定程度之后,服务发生卡顿。这是因为单个cpu在处理中断时,产生了瓶颈。通过dstat或者iftop命令,可以看到当前的网络流量。

比如,Kafka新机器上线之后,会进行大规模的数据拷贝,这个时候如果你去ping相关的机器,会发现ping值变的非常大。同时,Recv-Q和Send-Q的值也会增大。
这个时候,就需要开启网卡多队列模式。
使用ethtool可以看到网卡的队列信息。
- ethtool -l eth0 | grep 'Combined'
- Combined: 1
当然,通过下面的命令,可以增加网卡的队列。
- ethtool -L eth0 combined 2
建议同时开启中断平衡服务。
- systemctl start irqbalance
3. 不定时的切断一下长连接
如果客户端和服务端连接上了,并一直保持连接不关闭对方,那么它就是一条长连接。长连接可以避免频繁的连接创建所产生的开销。从HTTP1到HTTP2再到HTTP3,一直在向减少连接,复用连接方面去努力。通常情况下,长连接是第一选择。
但有一些特殊情况,我们希望长连接并不要一直在那里保持着,需要给它增加TTL。这种情况通常发生在负载均衡场景里。
比如LVS、HAProxy等。
如果后端有A、B、C三台机器,经过LVS负载之后,90条连接被分散到三台机器。但某个时刻,A宕机了,它所持有的30个连接就会被重新负载到B、C上,这时候它们都持有45条连接。
当A重启之后,它却再也拿不到新的连接。如果LVS运算一次再平衡的话,产生的影响也比较大。所以我们希望创建的长连接能够有一个生存时长的属性,在某个时间间隔内达到渐进式的再平衡。
4. k8s端口范围
为了k8s和别的程序不起冲突,默认端口的范围是 30000-32767。如果你在使用k8s平台,配置了nodeport但是无法访问到,要注意是不是设置的端口号太小了。
5. TIME_WAIT
TIME_WAIT是主动关闭连接的一方保持的状态,像nginx、爬虫服务器,经常发生大量处于time_wait状态的连接。TCP一般在主动关闭连接后,会等待2MS,然后彻底关闭连接。由于HTTP使用了TCP协议,所以在这些频繁开关连接的服务器上,就积压了非常多的TIME_WAIT状态连接。
某些系统通过dmesg可以看到以下信息。
- __ratelimit: 2170 callbacks suppressed
- TCP: time wait bucket table overflow
- TCP: time wait bucket table overflow
- TCP: time wait bucket table overflow
- TCP: time wait bucket table overflow
sysctl命令可以设置这些参数,如果想要重启生效的话,加入/etc/sysctl.conf文件中。
- # 修改阈值
- net.ipv4.tcp_max_tw_buckets = 50000
- # 表示开启TCP连接中TIME-WAIT sockets的快速回收
- net.ipv4.tcp_tw_reuse = 1
- #启用timewait 快速回收。这个一定要开启,默认是关闭的。
- net.ipv4.tcp_tw_recycle= 1
- # 修改系統默认的TIMEOUT时间,默认是60s
- net.ipv4.tcp_fin_timeout = 10
测试参数的话,可以使用 sysctl -w net.ipv4.tcp_tw_reuse = 1 这样的命令。如果是写入进文件的,则使用sysctl -p生效。
6. CLOSE_WAIT
CLOSE_WAIT一般是由于对端主动关闭,而我方没有正确处理的原因引起的。说白了,就是程序写的有问题,属于危害比较大的一种。
大家都知道TCP的连接是三次握手四次挥手,这是由于TCP连接允许单向关闭。
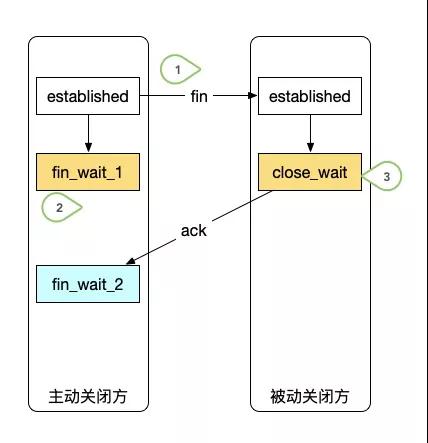
如图,当一个连接发起主动关闭之后,它将进入fin_wait_1状态。同时,收到fin报文的被动关闭方,进入close_wait状态,然后回复ack后,主动关闭方进入fin_wait_2状态。这就是单向的关闭。
此时,如果被动关闭方因为某些原因,没有发送fin报文给主动关闭方,那么它就会一直处于close_wait状态。比如,收到了EOF但没有发起close操作。
显然,这多数是一种编程bug,只能通过代码review来解决。
7. 一个进程能够打开的网络连接

Linux即使放开一个端口,能够接受的连接也是海量的。这些连接的上限,受到单进程文件句柄数量和操作系统文件句柄数量的限制,也就是ulimit和file-max。
为了能够将参数修改持久化,我们倾向于将改动写入到文件里。进程的文件句柄限制,可以放在/etc/security/limits.conf中,它的上限受到fs.nr_open的制约;操作系统的文件句柄限制,可以放到/etc/sysctl.conf文件中。最后,别忘了在/proc/$id/limits文件中,确认修改是否对进程生效了。
/etc/security/limits.conf配置案例:
- root soft nofile 1000000
- root hard nofile 1000000
- * soft nofile 1000000
- * hard nofile 1000000
- es - nofile 65535
8. SO_KEEPALIVE
如果将这个Socket选项打开,客户端Socket每隔段的时间(大约两个小时)就会利用空闲的连接向服务器发送一个数据包。
这个数据包并没有其它的作用,只是为了检测一下服务器是否仍处于活动状态。
如果服务器未响应这个数据包,在大约11分钟后,客户端Socket再发送一个数据包,如果在12分钟内,服务器还没响应,那么客户端Socket将关闭。如果将Socket选项关闭,客户端Socket在服务器无效的情况下可能会长时间不会关闭。
9. SO_REUSEADDR是为了解决什么问题
当我们在网络开发时,时常会碰到address already in use的异常,这是由于关闭应用程序时,还有对应端口的网络连接处于TIME_WAIT状态而造成的。
TIME_WAIT状态通常会持续一段时间(2ML),设置SO_REUSEADDR可以支持快速端口复用,支持应用的快速重启。
10. 健康检查采用应用心跳
tcp自身的keepalived机制非常的鸡肋,它静悄悄的在底层运行,无法产生应用层的语义。
在我们的想象里,连接就应该是一条线。但其实,它只是2个点,而且每次走的路径都可能不一样。一个点,需要在发出心跳包然后收到回复之后,才能知道对方是否存活。
tcp自带的心跳机制,仅仅能知道对方是否存活,对于服务是否可用,健康状况这些东西一概不知,而且超时配置常常与超时重传机制相冲突。
所以,有确切含义的应用层心跳是必要的。
11. SO_LINGER
这个Socket选项可以影响close方法的行为。
在默认情况下,当调用close方法后,将立即返回;如果这时仍然有未被送出的数据包,那么这些数据包将被丢弃。
如果将linger参数设为一个正整数n时(n的值最大是65,535),在调用close方法后,将最多被阻塞n秒。
在这n秒内,系统将尽量将未送出的数据包发送出去;如果超过了n秒,如果还有未发送的数据包,这些数据包将全部被丢弃;而close方法会立即返回。
如果将linger设为0,和关闭SO_LINGER选项的作用是一样的。
12. SO_TIMEOUT
可以通过这个选项来设置读取数据超时。
当输入流的read方法被阻塞时,如果设置timeout(timeout的单位是毫秒),那么系统在等待了timeout毫秒后会抛出一个InterruptedIOException例外。
在抛出例外后,输入流并未关闭,你可以继续通过read方法读取数据。
13. SO_SNDBUF,SO_RCVBUF
在默认情况下,输出流的发送缓冲区是8096个字节(8K)。这个值是Java所建议的输出缓冲区的大小。
如果这个默认值不能满足要求,可以用setSendBufferSize方法来重新设置缓冲区的大小。但最好不要将输出缓冲区设得太小,否则会导致传输数据过于频繁,从而降低网络传输的效率。
14. SO_OOBINLINE
如果这个Socket选项打开,可以通过Socket类的sendUrgentData方法向服务器发送一个单字节的数据。
这个单字节数据并不经过输出缓冲区,而是立即发出。
虽然在客户端并不是使用OutputStream向服务器发送数据,但在服务端程序中这个单字节的数据是和其它的普通数据混在一起的。因此,在服务端程序中并不知道由客户端发过来的数据是由OutputStream还是由sendUrgentData发过来的。
End
我非常惊讶的发现,现在有些网络环境,依然还是千兆网卡,包括一些比较专业的测试环境。当在这些环境上进行实际的压测时,当流量突破了网卡的限制,应用响应将会变的异常缓慢。计算机系统是一个整体,CPU、内存、网络、IO,任何一环出现瓶颈,都会造成问题。
在分布式系统中,网络是一个非常重要的因素。但由于它相对来说比较底层,所以大多数开发对其了解较少。加上现在各种云原生组件的流行,接触这些底层设施的机会就越来越少。但如果系统真的发生了问题,在排除掉其他最可能出问题的组件后,千万别忘了--
还有网络这一摊子等着你。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。