什么是feed流?什么是读扩散?什么是写扩散?
任何脱离业务的架构设计都是耍流氓,今天和大家聊聊这几个话题。

哪些产品是feed流典型业务?
微博,微信朋友圈,Pinterest是典型的feed流业务,系统中的每一条消息就是一个feed。
这类业务有什么特点?
(1)有好友关系,例如关注,粉丝;
(2)我们的主页由别人发布的feed组成。
这类业务的核心业务动作是什么?
(1)关注,取关;
(2)发布feed;
(3)拉取自己的主页feed流。
这类业务的核心元数据是什么?
(1)关系数据;
(2)feed数据。
feed流的“拉取”与“推送”实现,是个怎么回事?
feed流业务最大的特点是“我们的主页由别人发布的feed组成”,获得朋友圈消息feed流集合,从技术上说,主要有:
(1)拉取(读扩散);
(2)推送(写扩散)。
两种方式。feed流的推与拉主要指的是这里。
什么是拉模式 ,读扩散方案?
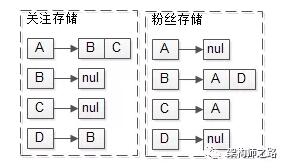
例如,某feed系统里有ABCD四个用户,其中:
(1)A关注了BC,D关注了B;
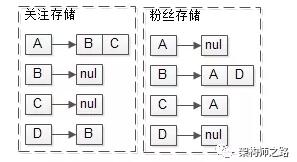
其关系存储又包含关注关系与粉丝关系,“A关注了BC,D关注了B”的潜台词是“B有两个粉丝AD,C有一个粉丝A”。
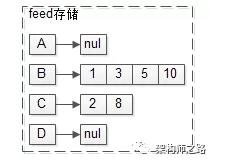
(2)B发布过四条feed:msg1, msg3, msg5, msg10;
(3)C发布过两条feed:msg2, msg8;
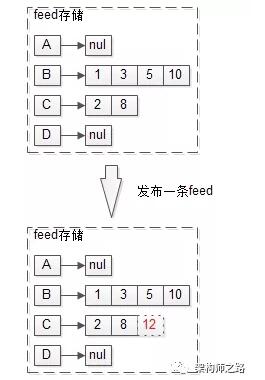
拉模式读扩散如何实现feed发布?
在拉模式中,发布一条feed的流程非常简单,例如C新发布了一条msg12:
拉模式读扩散如何实现关注/取关?
在拉模式中,取消关注的流程也非常简单,例如A取消关注C:
拉模式读扩散如何实现个人主页feed流?
在拉模式中,用户A获取“由别人发布的feed组成的主页”的过程及其复杂,此时需要:
(1)获取A的关注列表;
(2)获取所关注列表中,所有用户发布的feed;
(3)对消息进行rank排序(假设按照发布时间排序),分页取出对应的一页feeds。
拉模式读扩散有什么优点?
(1)存储结构简单,数据存储量较小,关系数据与feed数据都只存一份;
(2)关注,取关,发布feed的业务流程非常简单;
(3)存储结构,业务流程都比较容易理解,适合项目早期用户量、数据量、并发量不大时的快速实现。
拉模式读扩散有什么缺点?
(1)拉取朋友圈feed流列表的业务流程非常复杂;
(2)有多次数据访问,并且要进行大量的内存计算,网络传输,性能较低。
什么是推模式 ,写扩散方案?
推模式(写扩散),关系数据的存储与拉模式(读扩散)完全一样。
feed数据,每个用户也存储自己发布的feed。
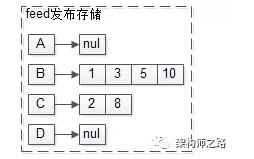
如上图:
(1)B曾经发布过1,3,5,10;
(2)C曾经发布过2,8。
画外音:不妨设,这里的msgid按照feed的发布时间偏序。
feed数据存储,与拉(读扩散)不同的是,每个用户还需要存储自己收到的feed流。
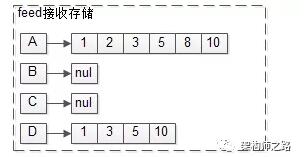
如上图:
(1)A关注了BC,所以A的接收队列是1,2,3,5,8,10;
(2)D关注了B,所以D的接受队列是1,3,5,10。
推模式写扩散如何实现个人主页feed流?
在推模式(写扩散)中,获取“由别人发布的feed组成的主页”会变得异常简单,假设一页消息为3条feed,A如果要看自己朋友圈的第二页消息,直接返回1,2,3即可。
画外音:第一页朋友圈是最新的消息,即5,8,10。
推模式写扩散如何实现feed发布?
在推模式(写扩散)中,发布一条feed的流程会更复杂一点。
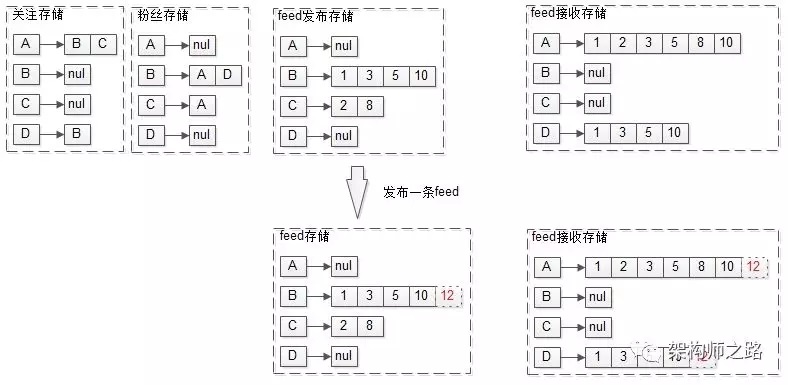
例如B新发布了一条msg12:
(1)在B的发布feed存储里加入消息12;
(2)查询B全部粉丝AD;
(3)在粉丝AD的接收feed存储里也加入消息12。
之所以该方案称为推模式(写扩散),就是因为,用户发布feed的时候:
(1)直接将feed推到了粉丝的接收列表里,故称为“推模式”;
(2)不止写发布feed存储,而且要写多个粉丝的接收feed存储,故称为“写扩散”。
推模式写扩散如何实现关注/取关?
在推模式(写扩散)中,添加关注的流程也会变得复杂。
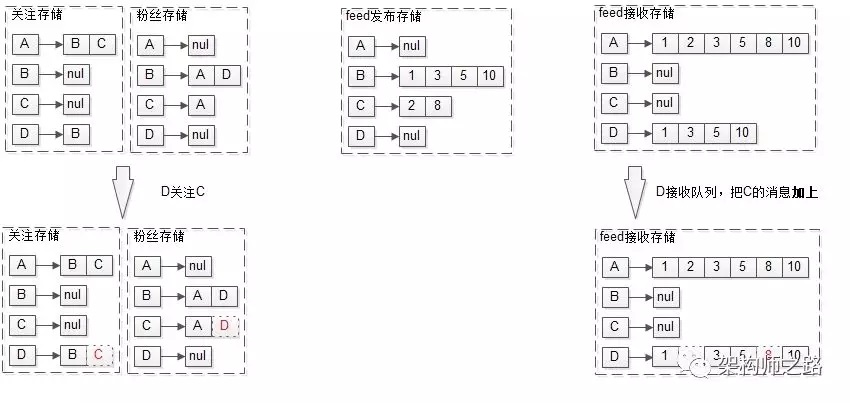
例如D新增关注C:
(1)在D的关注存储里添加C;
(2)在C的粉丝存储里添加D;
(3)在D的接收feed存储里加入C发布的feed。
画外音:有些产品有这样的逻辑,“关注之后才能看到feed”,这样的话就不需要第三步,旧feed无需插入。
在推模式(写扩散)中,取消关注的流程也会变得复杂。
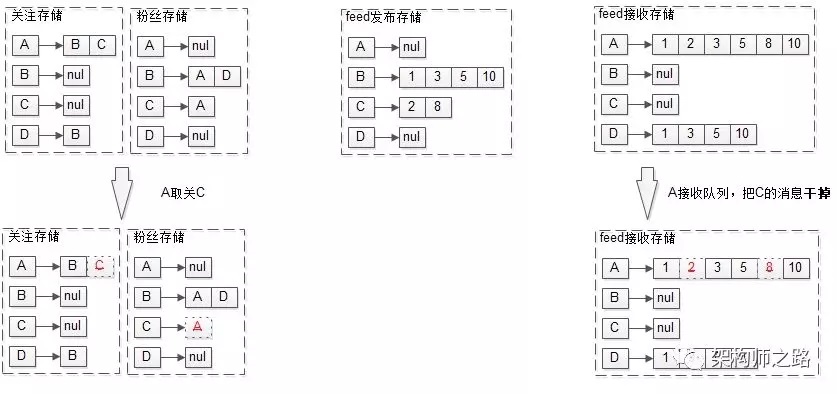
例如A取消关注C:
(1)在A的关注存储里删除C;
(2)在C的粉丝存储里删除A;
(3)在A的接收feed存储里删除C发布的feed。
推模式写扩散有什么优点?
(1)消除了拉模式(读扩散)的IO集中点,每个用户都读自己的数据,高并发下锁竞争少;
画外音:拉模式(读扩散)中,用户发布feed存储容易成为IO瓶颈。
(2)拉取朋友圈feed流列表的业务流程异常简单,速度很快;
(3)拉取朋友圈feed流列表,不需要进行大量的内存计算,网络传输,性能很高。
画外音:feed业务是典型的读多写少业务场景,读写比甚至高于100:1,即平均发布1条消息,有至少100次阅读。
推模式写扩散有什么缺点?
(1)极大极大消耗存储资源,feed数据会存储很多份,例如杨幂5KW粉丝,她每次一发博文,消息会冗余5KW份;
画外音:有朋友提出,可以存储一份消息实体,只冗余msgid,这样的话,拉取feed流列表时,还要再次拉取实体,网络时延会更长,所以很多公司选择直接冗余消息实体,当然,这是一个用户体验与存储量的折衷设计。
(2)新增关注,取消关注,发布feed的业务流会更复杂。
小结
feed流业务的推拉模式:
(1)拉模式,读扩散,feed存一份,存储小,用户集中访问数据,性能差;
(2)推模式,写扩散,feed存多份,用冗余存储换锁冲突,性能高;
推拉结合的方式是否可行?又该如何优化呢?
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】