神经科学会成为人工智能「超进化」的关键吗?
在深度学习和深度神经网络火遍天下的今天,离不开对大脑的研究。
虽然我们还未探究清楚大脑如何工作,但这样的大脑结构确实可以产生「智能」。
只要模拟它,神经网络就可以获得相似或相同的智能。真正能够学习人类的矩阵或许就在不远处。

近日,神经科学家 Patrick Mineault 就 2021 年无监督学习的大脑模型做了总结回顾。

神经人工智能(neuro-AI)研究中最有说服力的发现之一是,训练人工神经网络执行匹配大脑中单个神经元和集合信号的相关任务。
一个典型的例子就是腹侧流(ventral stream),DNNs 在 ImageNet 上训练进行对象识别。
监督和任务优化网络连接两个重要的解释形式: 生态相关性和神经活动可解释性。
「What can 5.17 billion regression fits tell us about artificial models of the human visual system? 」这篇论文便回答了大脑区域是用来做什么这一问题。
然而,正如 Jess Thompson 指出的那样,这不是唯一的解释形式。
特别是,任务优化网络通常在生物学上被认为是不合理的,因为传统的 ImageNet 训练会使用 1M 图像。
即便是为了让婴儿识别一项任务,他们必须每 5 秒接受一个新的监督标签,例如父母指着一只鸭子对孩子说「鸭子」,每天 3 小时,持续一年以上。
那对于非人类的灵长类动物和老鼠又是怎样的一种情况?因此,寻找与人类大脑相匹配的生物学上相似的神经网络研究仍在继续。
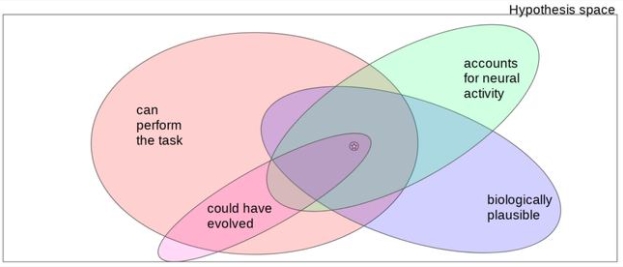
Jess Thompson 的神经人工智能假说空间
自监督训练方法有哪些
今年,我们已经看到无监督训练方面取得很大进展,逐渐替代了自监督训练的一些方法。
自监督训练的一些方法如下:
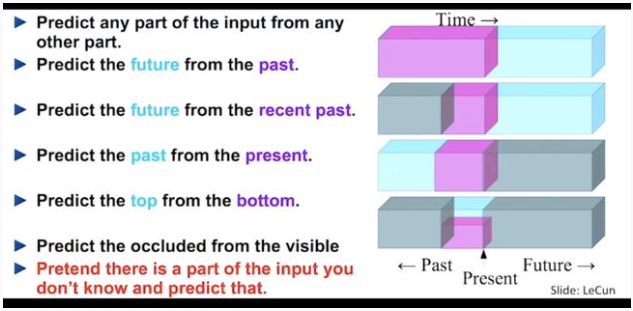
·无监督学习旨在表示数据分布。该领域最常用的技术之一是变分自编码器 (VAE)。
·自监督训练旨在通过解决代理任务来找到良好的数据表示。如今,语言模型几乎普遍使用自监督训练,比如 BERT 和 GPT-3。
·对比学习是自监督学习的一种特殊形式,其代理任务是预测样本是来自正面还是负面(或干扰项)。对比学习有很多不同的风格:MoCo、InfoNCE、SimCLR、CPC 等。也有一些密切相关的非对比方法可以消除负样本,包括 BYOL 和 BarlowTwins。
·多模态学习是自监督训练的另一种特殊形式,其目的是通过预测两种不同的模态(如视觉、文本、音频等)的共同子空间,或者预测一个模态共同的子空间。CLIP 便是一个典型的例子。
所有这些方法都允许我们在不需要监督情况下学习表示。其实,自监督和无监督方法相结合比只使用监督方法在生物学上更合理。
就此,Mineault 回顾了今年 MAIN、NeurIPS、CCN 会议,以及其他预印本,并做出了一份关于无监督学习的大脑模型总结。
Unsupervised neural network models of the ventral visual stream
这篇论文刚刚发表在 PNAS 顶刊上,引用量已超过 60。
论文地址:https://www.pnas.org/content/118/3/e2014196118
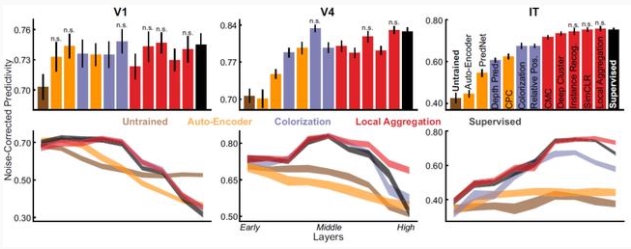
作者发现,无监督和自监督方法学习的表征与腹侧流(V1,V4,IT)神经元实现方式一致。论文摘要指出:
灵长类动物显示出非凡的识别能力。这种能力是通过腹侧视觉流实现的,腹侧流是多个等级相互关联的大脑区域。这些领域最好的定量模型是经过人工标记训练的深层神经网络。
然而,这些模型需要比婴儿接收到更多的标记,使他们无法实现腹侧流发展模式。
最近,在无监督学习取得的进展在很大程度上弥补了这一差距。我们发现,用最新的无监督学习的神经网络在腹侧流中获得的预测精度等于或超过当今最好的模型。
这些结果说明了使用无监督学习来建立大脑系统的模型,并为感官学习计算理论提供了一个强有力的备选方案。
特别是,作者发现 SimCLR 和其他对比学习方法几乎可以像监督学习方法一样解释腹侧神经元。
训练模型时标签不是必要的,这篇论文是一个非常强有力的证明。
Beyond category-supervision:
Computational support for domain-general pressures guiding human visual system representation
论文地址:https://www.biorxiv.org/content/10.1101/2020.06.15.153247v3
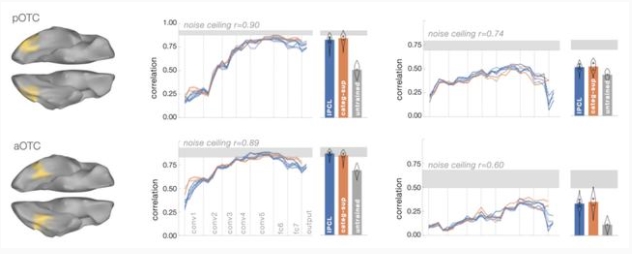
Konkle and Alvarez 在论文提出了一个与 Zhuang 等人论文类似的问题:
腹侧信息流是否可以由一个不经过监督式学习训练的网络来解释?他们使用功能磁共振成像而不是单个神经元的记录来评估这一点。他们发现结果与 Zhuang 的文章大体一致,并且有着自己独特的实例——对比自我监督,以及其他类似的解释 fMRI 数据的结果。
Your head is there to move you around: Goal-driven models of the primate dorsal pathway
这篇论文便是由神经科学家 Patrick Mineault 撰写,已在 2021NeurIPS 发表。
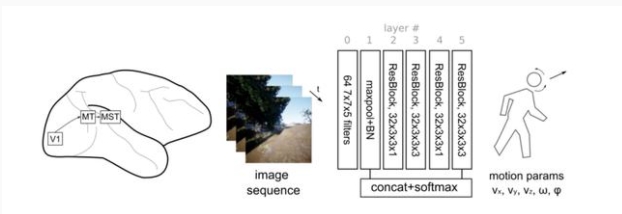
正如作者之前所讨论的,腹侧神经元对形状是有选择性的。然而,视觉皮层输出的讯息会传送到两个渠道,一个是腹侧流,另一个便是背侧流,这是怎么回事?作者通过比较许多自监督的 3D 网络和不同的背侧流区域,发现它们不能解释非人灵长类动物单个神经元的反应。
论文地址:https://your-head-is-there-to-move-you-around.netlify.app/
因此, Mineault 草拟了一个代理任务,世界上有生命的生物必须根据落在它的视网膜上的图像模式来确定它自身运动的参数。
由此产生的网络看起来很像背侧流,这在定性和定量上都是真实的。目前,该模型的训练是有监督的,但从智能体的角度来看,它是自监督的多模态学习: 智能体从另一个模态 (视觉) 中学习预测其自运动的参数 (前庭,传出拷贝),这在生物学上可能是合理的。
视觉皮层的功能
视觉皮层的功能特殊化于通过自我监督的预测学习训练有着异曲同工之妙。
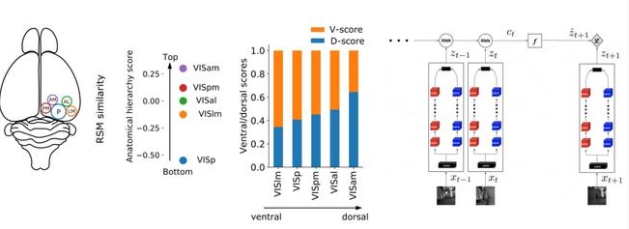
项目主页:https://ventral-dorsal-model.netlify.app/
Bakhtiari 等人 2021 年的两篇论文都获得了 NeurIPS spotlights。
Bakhtiari 认为无论是人类、非人灵长类还是老鼠,哺乳动物的视觉单元都有背侧和腹侧流。
那么,用人工神经网络能解释这两者吗?
Shahab 通过在电影片段上训练对比预测编码(CPC)网络,发现如果神经网络包含两条独立的平行路径,神经网络会自发地形成背侧和腹侧流。
背侧流路径与小鼠背侧区域匹配良好,而腹侧流与小鼠腹侧流匹配良好。
另一方面,经过监督训练的网络,或者只有一条通路的网络,就无法与老鼠的大脑相匹配。
浅层无监督模型
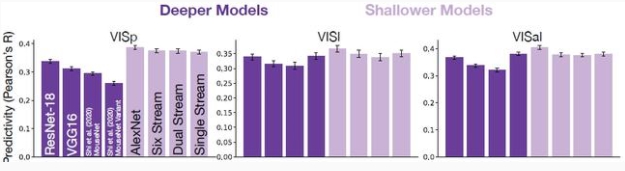
研究人员最近发现浅层无监督模型最能预测小鼠视觉皮层的神经反应。
论文地址:https://www.biorxiv.org/content/10.1101/2021.06.16.448730v2.full.pdf
Nayebi 等人 2021 年的论文表示深层神经网络是受灵长类动物的视觉皮层启发而开发的伟大模型,但对老鼠来说就不那么适用了。
他们使用老鼠的视觉皮层数据(静态图像),并将其与不同架构的监督和自我监督网络进行比较。
一个有趣的发现是,具有平行分支的浅层网络能更好地解释老鼠视觉皮层的数据。这证实了 Shahab 的发现。
Nayebi 团队提出的论点是,老鼠的视觉大脑是一个浅层的「通用」视觉机器,面对各种任务都能胜任,不像人类大脑中的深层神经网络,只对某一个任务特别精通。
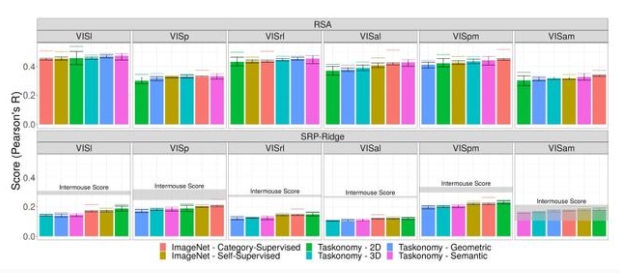
Conwell 团队在 NeurIPS 2021 发表了另一篇关于小鼠视觉皮层自我监督学习的论文,并得出了与前两篇论文一致的结论。
论文地址:https://proceedings.neurips.cc/paper/2021/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
超越人类
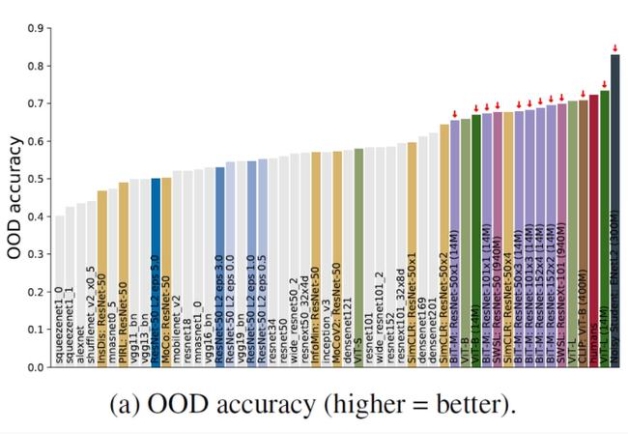
Geirhos 等人在 NeurIPS 2021 的论文表明,人类非常擅长在失真情况(例如噪声、对比度变化、旋转等)下对图像进行分类。
论文地址:https://arxiv.org/pdf/2106.07411.pdf
在这篇论文中,他们发现,新的自我监督和多模态模型在进行图像分类任务时,鲁棒性已经和人类不相上下。
其背后的一个重要因素是训练网络用了多少数据:用更多数据训练的模型更鲁棒。
那是因为新模型对纹理不太敏感,而对形状更敏感,这也就意味着它们似乎走了更少的捷径。当然,新模型仍然会犯明显的错误。
多模态神经网络
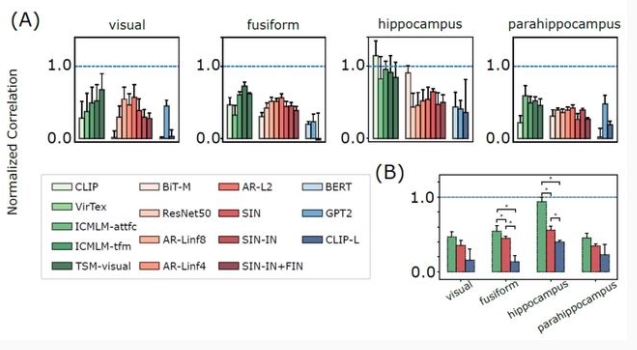
论文地址:https://openreview.net/pdf?id=6dymbuga7nL
Choksi 团队在 2021 年 SVHRM 研讨会上提出,人类大脑的海马体包含多模态的「概念细胞」(例如詹妮弗·安妮斯顿细胞),它们会对概念或图像的文本表示做出反应。
有趣的是,CLIP 也是这样做的。
事实上在这篇论文中,作者利用公开的功能磁共振成像数据表明,多模态网络,包括 CLIP,最能解释大脑海马体的数据。
无监督深度学习
Storrs 等人发表在《Nature Human Behaviour》的论文介绍了他们使用无监督学习预测人类对光泽的感知。
他们在一组纹理上训练 pixel-VAE,并寻找 pixel-VAE 与人类感知物体表面的方式的相似之处。他们发现,VAE 很自然地将不同的纹理组成因素进行解耦,这一点非常符合人类的感知方式。
此外,他们发现经过监督学习的网络在这项任务上的表现反而不尽如人意。
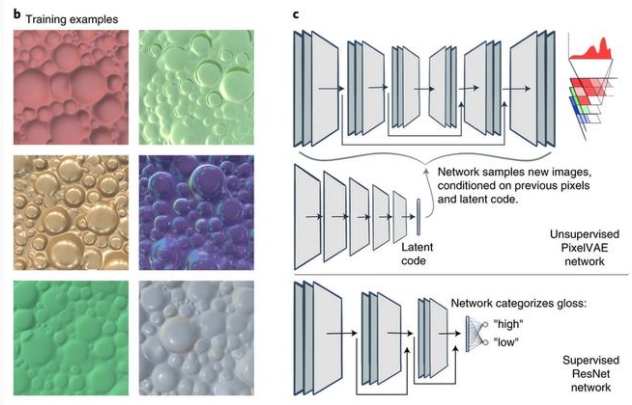
论文地址:https://www.nature.com/articles/s41562-021-01097-6.pdf
今年,研究人员在将无监督和自监督模型与大脑匹配方面取得了巨大进步。它们可以更好地匹配大脑数据,还可以在没有标签的情况下进行训练。
自监督为没有人工标签的学习打开了大门,但最新的模型经常需要大量的数据来进行训练。例如,GPT-3 基本上学习了人类积累的所有文本(大约 5000 亿个 token)。
相比之下,在最健谈的家庭里,孩子五岁时也就会接触到约 3000 万个单词。
所以,即使 GPT-3 是一种看似合理的语言习得和表征机制,但与人类大脑相比,效率仍然相差 4 个数量级。
PS:作者还在更新哦!
作者介绍
Patrick Mineault 是一名独立神经科学家,此前,曾在 Facebook 担任 BCI 工程师,还有谷歌的软件工程师和数据科学家。
个人主页:https://xcorr.net/about/
目前,他联合创办了 Neuromatch Academy 这家公司,并担任 CTO 一职。
Mineault 曾在 McGill 获得了视觉神经科学博士学位,并在 UCLA 完成了博士后。在 Facebook 工作那段时间,他曾构建了一个 BCI,能够通过大脑实现打字。
LeCun 和 Jeff Dean 就 Patrick Mineault 对过去一年无监督大脑模型的研究回顾进行了点评。
「Nice!但是 BYOL、Barlow Twins 和 VICReg 是用于训练联合嵌入架构的「非对比」方法。」
谷歌大牛 Jeff Dean 表示,这是 2021 年关于神经科学无监督学习和自监督学习一些非常棒的工作。