Python 是数据科学家最流行的编程语言之一,其内部集成了高质量分析库,包括 NumPy、SciPy、自然语言工具包等,这些库中的许多都是用 C 和 C++ 实现的。
然而,C 和 C++ 兼容性差,且本身不提供线程安全。有研究者开始转向 Rust,重写 C++ 扩展。

拥有 CS 与机器学习博士学位的 Carl M. Kadie,通过更新 Python 中生物信息学软件包 Bed-Reader,为研究者带来了在 Rust 中编写 Python 扩展的九个规则。以下是原博客的主要内容。
一年前,我厌倦了我们软件包 Bed-Reader 的 C++ 扩展,我用 Rust 重写了它,令人高兴的是,得到的新扩展和 C/C++ 一样快,但具有更好的兼容性和安全性。一路走来,我学会了这九条规则,可以帮助你创建更好的扩展代码,这九条规则包括:
- 创建一个包含 Rust 和 Python 项目的单独存储库
- 使用 maturin & PyO3 在 Rust 中创建 Python-callable translator 函数
- 让 Rust translator 函数调用 nice Rust 函数
- 在 Python 中预分配内存
- 将 nice Rust 错误处理翻译 nice Python 错误处理
- 多线程与 Rayon 和 ndarray::parallel,返回任何错误
- 允许用户控制并行线程数
- 将 nice 动态类型 Python 函数翻译成 nice Rust 泛型函数
- 创建 Rust 和 Python 测试
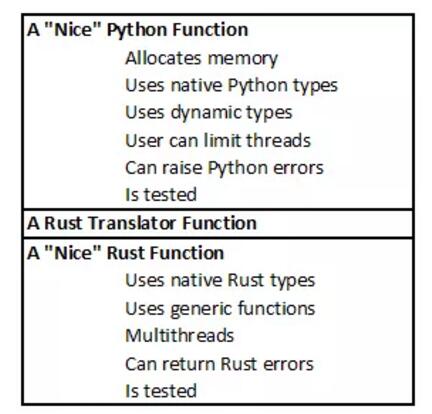
其中,文中提到的 nice 这个词是指使用最佳实践和原生类型创建。换句话说:在代码顶部,编写 nice Python 代码;在中间,用 Rust 编写 translator 代码;在底部,编写 nice Rust 代码。结构如下图所示:
上述策略看似显而易见,但遵循它可能会很棘手。本文提供了有关如何遵循每条规则的实用建议和示例。
我在 Bed-Reader 进行了实验,Bed-Reader 是一个 Python 包,用于读取和写入 PLINK Bed Files,这是一种在生物信息学中用于存储 DNA 数据的二进制格式。Bed 格式的文件可以达到 TB。Bed-Reader 让用户可以快速、随机地访问数据的子集。它在用户选择的 int8、float32 或 float64 中返回一个 NumPy 数组。
我希望 Bed-Reader 扩展代码具有以下特点:
- 比 Python 快;
- 兼容 NumPy;
- 可以进行数据并行多线程处理;
- 与执行数据并行多线程的所有其他包兼容;
- 安全。
我们最初的 C++ 扩展兼具速度快、与 NumPy 兼容,以及使用 OpenMP 进行数据并行多线程等特点。遗憾的是,OpenMP 运行时库 (Runtime library),存在 Python 包兼容版本问题。
Rust 提供了 C++ 扩展带来的优势。除此之外,Rust 通过提供没有运行时库的数据并行多线程解决了运行时兼容性问题。此外,Rust 编译器还能保证线程安全。
在 Rust 中创建 Python 扩展需要许多设计决策。根据我使用 Bed-Reader 的经验,以下是我的使用规则。
规则 1:创建一个包含 Rust 和 Python 项目的单独存储库
下表显示了如何布局文件:
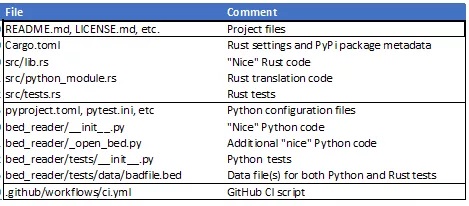
使用 Rust 常用的‘cargo new’命令创建 Cargo.toml 和 src/lib.rs 文件。Python 没有 setup.py 文件。相反,Cargo.toml 包含 PyPi 包信息,例如包的名称、版本号、 README 文件的位置等。要在没有 setup.py 的情况下工作,pyproject.toml 必须包含:
- [build-system]
- requires = ["maturin==0.12.5"]
- build-backend = "maturin"
一般来说,Python 设置在 pyproject.toml 中(如果不是,则在 pytest.ini 等文件中)。Python 代码位于子文件夹 bed_reader 中。
最后,我们使用 GitHub 操作来构建、测试和准备部署。该脚本位于 .github/workflows/ci.yml 中。
规则 2:使用 maturin & PyO3在 Rust 中创建 Python-callable translator 函数
Maturin 是一个 PyPi 包,可通过 PyO3 构建和发布 Python 扩展。PyO3 是一个 Rust crate,用于在 Rust 中编写 Python 扩展。
在 Cargo.toml 中,包含这些 Rust 依赖项:
- [dependencies]
- thiserror = "1.0.30"
- ndarray-npy = { version = "0.8.1", default-features = false }
- rayon = "1.5.1"
- numpy = "0.15.0"
- ndarray = { version = "0.15.4", features = ["approx", "rayon"] }
- pyo3 = { version = "0.15.1", features = ["extension-module"] }
- [dev-dependencies]
- temp_testdir = "0.2.3"
在 src/lib.rs 底部,包含这两行:
- mod python_module;
- mod tests;
规则 3:Rust translator 函数调用 nice Rust 函数
在 src/lib.rs 定义了 nice Rust 函数,这些函数将完成包的核心工作。它们能够输入和输出标准 Rust 类型并尝试遵循 Rust 最佳实践。例如,对于 Bed-Reader 包, read_no_alloc 是一个 nice Rust 函数,用于从 PLINK Bed 文件读取和返回值。
然而,Python 不能直接调用这些函数。因此,在文件 src/python_module.rs 中定义 Python 可以调用的 Rust translator 函数,下面为 translator 函数示例:
- #[pyfn(m)]
- #[pyo3(name = "read_f64")]
- fn read_f64_py(
- _py: Python<'_>,
- filename: &str,
- iid_count: usize,
- sid_count: usize,
- count_a1: bool,
- iid_index: &PyArray1<usize>,
- sid_index: &PyArray1<usize>,
- val: &PyArray2<f64>,
- num_threads: usize,
- ) -> Result<(), PyErr> {
- let iid_indexiid_index = iid_index.readonly();
- let sid_indexsid_index = sid_index.readonly();
- let mut val = unsafe { val.as_array_mut() };
- let ii = &iid_index.as_slice()?;
- let si = &sid_index.as_slice()?;
- create_pool(num_threads)?.install(|| {
- read_no_alloc(
- filename,
- iid_count,
- sid_count,
- count_a1,
- ii,
- si,
- f64::NAN,
- &mut val,
- )
- })?;
- Ok(())
- }
该函数将文件名、一些与文件大小相关的整数以及两个一维 NumPy 数组作为输入,这些数组指示要读取数据的哪个子集。该函数从文件中读取值并填充 val,这是一个预先分配的二维 NumPy 数组。
注意
将 Python NumPy 1-D 数组转换为 Rust slices,通过:
- let iid_indexiid_index = iid_index.readonly();
- let ii = &iid_index.as_slice()?;
将 Python NumPy 2d 数组转换为 2-D Rust ndarray 对象,通过:
- let mut val = unsafe { val.as_array_mut() };
调用 read_no_alloc,这是 src/lib.rs 中一个 nice Rust 函数,它将完成核心工作。
规则 4:在 Python 中预分配内存
在 Python 中为结果预分配内存简化了 Rust 代码。在 Python 端,在 bed_reader/_open_bed.py 中,我们可以导入 Rust translator 函数:
- from .bed_reader import [...] read_f64 [...]
然后定义一个 nice Python 函数来分配内存、调用 Rust translator 函数并返回结果。
- def read([...]):
- [...]
- val = np.zeros((len(iid_index), len(sid_index)), orderorder=order, dtypedtype=dtype)
- [...]
- reader = read_f64
- [...]
- reader(
- str(self.filepath),
- iid_count=self.iid_count,
- sid_count=self.sid_count,
- count_a1=self.count_A1,
- iid_indexiid_index=iid_index,
- sid_indexsid_index=sid_index,
- valval=val,
- num_threadsnum_threads=num_threads,
- )
- [...]
- return val
规则 5:将 nice Rust 错误处理翻译 nice Python 错误处理
为了了解如何处理错误,让我们在 read_no_alloc( src/lib.rs 中 nice Rust 函数)中跟踪两个可能的错误。
示例错误 1:来自标准函数的错误。如果 Rust 的标准 File::open 函数找不到文件或无法打开文件, 在这种情况下,如下一行中的? 将导致函数返回一些 std::io::Error 值。
- let mut buf_reader = BufReader::new(File::open(filename)?);
为了定义一个可返回这些值的函数,我们可以给函数一个返回类型 Result<(), BedErrorPlus>。我们定义 BedErrorPlus 时要包含所有 std::io::Error,如下所示:
- use thiserror::Error;
- ...
- /// BedErrorPlus enumerates all possible errors
- /// returned by this library.
- /// Based on https://nick.groenen.me/posts/rust-error-handling/#the-library-error-type
- #[derive(Error, Debug)]
- pub enum BedErrorPlus {
- #[error(transparent)]
- IOError(#[from] std::io::Error),
- #[error(transparent)]
- BedError(#[from] BedError),
- #[error(transparent)]
- ThreadPoolError(#[from] ThreadPoolBuildError),
- }
这是 nice Rust 错误处理,但 Python 不理解它。因此,在 src/python_module.rs 中,我们要进行翻译。首先,定义 translator 函数 read_f64_py 来返回 PyErr;其次,实现了一个从 BedErrorPlus 到 PyErr 的转换器。转换器使用正确的错误消息创建正确的 Python 错误类(IOError、ValueError 或 IndexError)。如下所示:
- impl std::convert::From<BedErrorPlus> for PyErr {
- fn from(err: BedErrorPlus) -> PyErr {
- match err {
- BedErrorPlus::IOError(_) => PyIOError::new_err(err.to_string()),
- BedErrorPlus::ThreadPoolError(_) => PyValueError::new_err(err.to_string()),
- BedErrorPlus::BedError(BedError::IidIndexTooBig(_))
- | BedErrorPlus::BedError(BedError::SidIndexTooBig(_))
- | BedErrorPlus::BedError(BedError::IndexMismatch(_, _, _, _))
- | BedErrorPlus::BedError(BedError::IndexesTooBigForFiles(_, _))
- | BedErrorPlus::BedError(BedError::SubsetMismatch(_, _, _, _)) => {
- PyIndexError::new_err(err.to_string())
- }
- _ => PyValueError::new_err(err.to_string()),
- }
- }
- }
示例错误 2:特定于函数的错误。如果 nice 函数 read_no_alloc 可以打开文件,但随后意识到文件格式错误怎么办?它应该引发一个自定义错误,如下所示:
- if (BED_FILE_MAGIC1 != bytes_vector[0]) || (BED_FILE_MAGIC2 != bytes_vector[1]) {
- return Err(BedError::IllFormed(filename.to_string()).into());
- }
BedError::IllFormed 类型的自定义错误在 src/lib.rs 中定义:
- use thiserror::Error;
- [...]
- // https://docs.rs/thiserror/1.0.23/thiserror/
- #[derive(Error, Debug, Clone)]
- pub enum BedError {
- #[error("Ill-formed BED file. BED file header is incorrect or length is wrong.'{0}'")]
- IllFormed(String),
- [...]
- }
其余的错误处理与示例错误 1 中的相同。
最后,对于 Rust 和 Python,标准错误和自定义错误的结果都属于带有信息性错误消息的特定错误类型。
规则 6:多线程与 Rayon 和 ndarray::parallel,返回任何错误
Rust Rayon crate 提供了简单且轻量级的数据并行多线程。ndarray::parallel 模块将 Rayon 应用于数组。通常的模式是跨一个或多个 2D 数组的列(或行)并行化。面对的一个挑战是从并行线程返回任何错误消息。我将重点介绍两种通过错误处理并行化数组操作的方法。以下两个示例都出现在 Bed-Reader 的 src/lib.rs 文件中。
方法 1:par_bridge().try_for_each
Rayon 的 par_bridge 将顺序迭代器变成了并行迭代器。如果遇到错误,使用 try_for_each 方法可以尽快停止所有处理。
这个例子中,我们遍历了压缩(zip)在一起的两个 things:
- DNA 位置的二进制数据;
- 输出数组的列。
然后,按顺序读取二进制数据,但并行处理每一列的数据。我们停止了任何错误。
- [... not shown, read bytes for DNA location's data ...]
- // Zip in the column of the output array
- .zip(out_val.axis_iter_mut(nd::Axis(1)))
- // In parallel, decompress the iid info and put it in its column
- .par_bridge() // This seems faster that parallel zip
- .try_for_each(|(bytes_vector_result, mut col)| {
- match bytes_vector_result {
- Err(e) => Err(e),
- Ok(bytes_vector) => {
- for out_iid_i in 0..out_iid_count {
- let in_iid_i = iid_index[out_iid_i];
- let i_div_4 = in_iid_i / 4;
- let i_mod_4 = in_iid_i % 4;
- let genotype_byte: u8 = (bytes_vector[i_div_4] >> (i_mod_4 * 2)) & 0x03;
- col[out_iid_i] = from_two_bits_to_value[genotype_byte as usize];
- }
- Ok(())
- }
- }
- })?;
方法 2:par_azip!
ndarray 包的 par_azip!宏允许并行地通过一个或多个压缩在一起的数组或数组片段。在我看来,这非常具有可读性。但是,它不直接支持错误处理。因此,我们可以通过将任何错误保存到结果列表来添加错误处理。
下面是一个效用函数的例子。完整的效用函数从三个计数和总和(count and sum)数组计算统计量(均值和方差),并且并行工作。如果在数据中发现错误,则将该错误记录在结果列表中。在完成所有处理之后,检查结果列表是否有错误。
- [...]
- let mut result_list: Vec<Result<(), BedError>> = vec![Ok(()); sid_count];
- nd::par_azip!((mut stats_row in stats.axis_iter_mut(nd::Axis(0)),
- &n_observed in &n_observed_array,
- &sum_s in &sum_s_array,
- &sum2_s in &sum2_s_array,
- result_ptr in &mut result_list)
- {
- [...some code not shown...]
- });
- // Check the result list for errors
- result_list.par_iter().try_for_each(|x| (*x).clone())?;
- [...]
Rayon 和 ndarray::parallel 提供了许多其他不错的数据并行处理方法。
规则 7:允许用户控制并行线程数
为了更好地使用用户的其他代码,用户必须能够控制每个函数可以使用的并行线程数。
在下面这个 nice Python read 函数中,用户可以得到一个可选的 num_threadsargument。如果用户没有设置它,Python 会通过这个函数设置它:
- def get_num_threads(num_threads=None):
- if num_threads is not None:
- return num_threads
- if "PST_NUM_THREADS" in os.environ:
- return int(os.environ["PST_NUM_THREADS"])
- if "NUM_THREADS" in os.environ:
- return int(os.environ["NUM_THREADS"])
- if "MKL_NUM_THREADS" in os.environ:
- return int(os.environ["MKL_NUM_THREADS"])
- return multiprocessing.cpu_count()
接着在 Rust 端,我们可以定义 create_pool。这个辅助函数从 num_threads 构造一个 Rayon ThreadPool 对象。
- pub fn create_pool(num_threads: usize) -> Result<rayon::ThreadPool, BedErrorPlus> {
- match rayon::ThreadPoolBuilder::new()
- .num_threads(num_threads)
- .build()
- {
- Err(e) => Err(e.into()),
- Ok(pool) => Ok(pool),
- }
- }
最后,在 Rust translator 函数 read_f64_py 中,我们从 create_pool(num_threads)?.install(...) 内部调用 read_no_alloc(很好的 Rust 函数)。这将所有 Rayon 函数限制为我们设置的 num_threads。
- [...]
- create_pool(num_threads)?.install(|| {
- read_no_alloc(
- filename,
- [...]
- )
- })?;
- [...]
规则 8:将 nice 动态类型 Python 函数翻译成 nice Rust 泛型函数
nice Python read 函数的用户可以指定返回的 NumPy 数组的 dtype(int8、float32 或 float64)。从这个选择中,该函数查找适当的 Rust translator 函数(read_i8(_py)、read_f32(_py) 或 read_f64(_py)),然后调用该函数。
- def read(
- [...]
- dtype: Optional[Union[type, str]] = "float32",
- [...]
- )
- [...]
- if dtype == np.int8:
- reader = read_i8
- elif dtype == np.float64:
- reader = read_f64
- elif dtype == np.float32:
- reader = read_f32
- else:
- raise ValueError(
- f"dtype'{val.dtype}'not known, only"
- + "'int8', 'float32', and 'float64' are allowed."
- )
- reader(
- str(self.filepath),
- [...]
- )
三个 Rust translator 函数调用相同的 Rust 函数,即在 src/lib.rs 中定义的 read_no_alloc。以下是 translator 函数 read_64 (又称 read_64_py) 的相关部分:
- #[pyfn(m)]
- #[pyo3(name = "read_f64")]
- fn read_f64_py(
- [...]
- val: &PyArray2<f64>,
- num_threads: usize,
- ) -> Result<(), PyErr> {
- [...]
- let mut val = unsafe { val.as_array_mut() };
- [...]
- read_no_alloc(
- [...]
- f64::NAN,
- &mut val,
- )
- [...]
- }
我们在 src/lib.rs 中定义了 niceread_no_alloc 函数。也就是说,该函数适用于具有正确特征的任何类型的 TOut 。其代码的相关部分如下所示:
- fn read_no_alloc<TOut: Copy + Default + From<i8> + Debug + Sync + Send>(
- filename: &str,
- [...]
- missing_value: TOut,
- val: &mut nd::ArrayViewMut2<'_, TOut>,
- ) -> Result<(), BedErrorPlus> {
- [...]
- }
在 nice Python、translator Rust 和 nice Rust 中组织代码,可以让我们为 Python 用户提供动态类型的代码,同时仍能用 Rust 编写出漂亮的通用代码。
规则 9:创建 Rust 和 Python 测试
你可能只想编写会调用 Rust 的 Python 测试。但是,你还应该编写 Rust 测试。添加 Rust 测试使你可以交互地运行测试和交互地调试。Rust 测试还为你以后得到 Rust 版本的包提供了途径。在示例项目中,两组测试都从 bed_reader/tests/data 读取测试文件。
在可行的情况下,我还建议编写函数的纯 Python 版本,然后就可以使用这些慢速 Python 函数来测试快速 Rust 函数的结果。
最后,关于 CI 脚本,例如 bed-reader/ci.yml,应该同时运行 Rust 和 Python 测试。
原文链接:https://towardsdatascience.com/nine-rules-for-writing-python-extensions-in-rust-d35ea3a4ec29
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】