服务器和应用程序日志记录是开发人员、运维人员和安全团队了解应用程序在其生产环境中运行状态的重要工具。
日志记录使运维人员能够确定应用程序和所需组件是否运行平稳,并检测是否发生了异常情况,以便他们能够对这种情况做出反应。
对于开发人员,日志记录提供了在开发期间和之后对代码进行故障排除的可见性。在生产环境中,开发人员通常依赖于没有调试工具的日志记录工具。在加上系统的日志记录,开发人员可以与运维人员携手合作,有效地解决问题。

日志记录工具最重要的受益者是安全团队,尤其是在云原生的环境中。能够从应用程序和系统日志中收集信息使得安全团队能够分析来自身份验证、应用程序访问恶意软件活动的数据,并在需要时进行响应。
Kubernetes 是领先的容器平台,越来越多的应用程序通过 Kubernetes 部署到生产环境。我相信了解 Kubernetes 的日志架构是一项非常重要的工作,每个开发、运维和安全团队都需要认真对待。
在本文中,我将讨论 Kubernetes 中不同容器日志记录模式的工作原理。
系统日志记录和应用日志记录
在深入研究 Kubernetes 日志记录架构之前,我想探索不同的日志记录方法以及这两种功能如何成为 Kubernetes 日志记录的关键特性。
有两种类型的系统组件:在容器中运行的组件和不在容器中运行的组件。例如:
- Kubernetes 调度者和 kube-proxy 运行在容器中。
- kubelet 和容器运行时不在容器中运行。
与容器日志类似,系统容器日志存储在 /var/log 目录中,你应该定期轮换它们。
在这里,我研究的是容器日志记录。首先,我看一下集群级别的日志记录以及为什么它对集群运维人员很重要。集群日志提供有关集群如何执行的信息。诸如为什么 吊舱Pod 被下线或节点死亡之类的信息。集群日志记录还可以捕获诸如集群和应用程序访问以及应用程序如何利用计算资源等信息。总体而言,集群日志记录工具为集群运维人员提供操作集群和安全有用的信息。
捕获容器日志的另一种方法是通过应用程序的本机日志记录工具。现代应用程序设计很可能具有日志记录机制,可帮助开发人员通过标准输出 (stdout) 和错误流 (stderr) 解决应用程序性能问题。
为了拥有有效的日志记录工具,Kubernetes 实现需要应用程序和系统日志记录组件。
Kubernetes 容器日志的 3 种类型
如今,在大多数的 Kubernetes 实现中,你可以看到三种主要的集群级日志记录方法。
- 节点级日志代理
- 用于日志记录的挎斗Sidecar容器应用程序
- 将应用程序日志直接暴露给日志后端
节点级日志代理
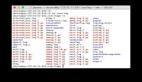
我想考虑节点级日志代理。你通常使用 DaemonSet 作为部署策略来实现这些,以便在所有 Kubernetes 节点中部署一个吊舱(充当日志代理)。然后,该日志代理被配置为从所有 Kubernetes 节点读取日志。你通常将代理配置为读取节点 /var/logs 目录捕获 stdout/stderr 流并将其发送到日志记录后端存储。
下图显示了在所有节点中作为代理运行的节点级日志记录。
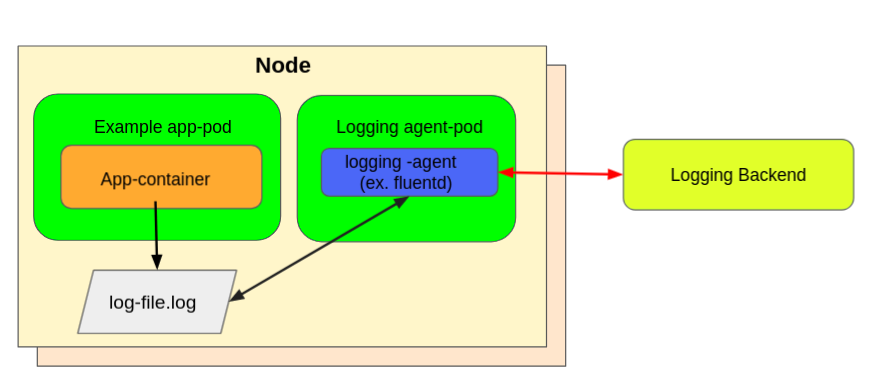
Node-level logging agent
以使用 fluentd 方法为例设置节点级日志记录,你需要执行以下操作:
(1) 首先,你需要创建一个名为 fluentdd 的服务账户。Fluentd 吊舱使用此服务账户来访问 Kubernetes API,你需要在日志命名空间中使用标签 app: fluentd 创建它们:
- #fluentd-SA.yaml
- apiVersion: v1
- kind: ServiceAccount
- metadata:
- name: fluentd
- namespace: logging
- labels:
- app: fluentd
你可以在此 仓库 中查看完整示例。
(2) 接着,你需要创建一个名称为 fluentd-configmap 的 ConfigMap。这为 fluentd daemonset 提供了一个配置文件,其中包含所有必需的属性。
- #fluentd-daemonset.yaml
- apiVersion: extensions/v1beta1
- kind: DaemonSet
- metadata:
- name: fluentd
- namespace: logging
- labels:
- app: fluentd
- kubernetes.io/cluster-service: "true"
- spec:
- selector:
- matchLabels:
- app: fluentd
- kubernetes.io/cluster-service: "true"
- template:
- metadata:
- labels:
- app: fluentd
- kubernetes.io/cluster-service: "true"
- spec:
- serviceAccount: fluentd
- containers:
- - name: fluentd
- image: fluent/fluentd-kubernetes-daemonset:v1.7.3-debian-elasticsearch7-1.0
- env:
- - name: FLUENT_ELASTICSEARCH_HOST
- value: "elasticsearch.logging.svc.cluster.local"
- - name: FLUENT_ELASTICSEARCH_PORT
- value: "9200"
- - name: FLUENT_ELASTICSEARCH_SCHEME
- value: "http"
- - name: FLUENT_ELASTICSEARCH_USER
- value: "elastic"
- - name: FLUENT_ELASTICSEARCH_PASSWORD
- valueFrom:
- secretKeyRef:
- name: efk-pw-elastic
- key: password
- - name: FLUENT_ELASTICSEARCH_SED_DISABLE
- value: "true"
- resources:
- limits:
- memory: 512Mi
- requests:
- cpu: 100m
- memory: 200Mi
- volumeMounts:
- - name: varlog
- mountPath: /var/log
- - name: varlibdockercontainers
- mountPath: /var/lib/docker/containers
- readOnly: true
- - name: fluentconfig
- mountPath: /fluentd/etc/fluent.conf
- subPath: fluent.conf
- terminationGracePeriodSeconds: 30
- volumes:
- - name: varlog
- hostPath:
- path: /var/log
- - name: varlibdockercontainers
- hostPath:
- path: /var/lib/docker/containers
- - name: fluentconfig
- configMap:
- name: fluentdconf
你可以在此 仓库 中查看完整示例。
现在,我们来看看如何将 fluentd daemonset 部署为日志代理的代码。
- #fluentd-daemonset.yaml
- apiVersion: extensions/v1beta1
- kind: DaemonSet
- metadata:
- name: fluentd
- namespace: logging
- labels:
- app: fluentd
- kubernetes.io/cluster-service: "true"
- spec:
- selector:
- matchLabels:
- app: fluentd
- kubernetes.io/cluster-service: "true"
- template:
- metadata:
- labels:
- app: fluentd
- kubernetes.io/cluster-service: "true"
- spec:
- serviceAccount: fluentd
- containers:
- - name: fluentd
- image: fluent/fluentd-kubernetes-daemonset:v1.7.3-debian-elasticsearch7-1.0
- env:
- - name: FLUENT_ELASTICSEARCH_HOST
- value: "elasticsearch.logging.svc.cluster.local"
- - name: FLUENT_ELASTICSEARCH_PORT
- value: "9200"
- - name: FLUENT_ELASTICSEARCH_SCHEME
- value: "http"
- - name: FLUENT_ELASTICSEARCH_USER
- value: "elastic"
- - name: FLUENT_ELASTICSEARCH_PASSWORD
- valueFrom:
- secretKeyRef:
- name: efk-pw-elastic
- key: password
- - name: FLUENT_ELASTICSEARCH_SED_DISABLE
- value: "true"
- resources:
- limits:
- memory: 512Mi
- requests:
- cpu: 100m
- memory: 200Mi
- volumeMounts:
- - name: varlog
- mountPath: /var/log
- - name: varlibdockercontainers
- mountPath: /var/lib/docker/containers
- readOnly: true
- - name: fluentconfig
- mountPath: /fluentd/etc/fluent.conf
- subPath: fluent.conf
- terminationGracePeriodSeconds: 30
- volumes:
- - name: varlog
- hostPath:
- path: /var/log
- - name: varlibdockercontainers
- hostPath:
- path: /var/lib/docker/containers
- - name: fluentconfig
- configMap:
- name: fluentdconf
将这些放在一起执行:
- kubectl apply -f fluentd-SA.yaml \
- -f fluentd-configmap.yaml \
- -f fluentd-daemonset.yaml
用于日志记录的挎斗容器应用程序
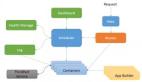
另一种方法是使用带有日志代理的专用挎斗容器。容器最常见的实现是使用 Fluentd 作为日志收集器。在企业部署中(你无需担心一点计算资源开销),使用 fluentd(或类似)实现的挎斗容器提供了集群级日志记录的灵活性。这是因为你可以根据需要捕获的日志类型、频率和其它可能的调整来调整和配置收集器代理。
下图展示了作为日志代理的挎斗容器。
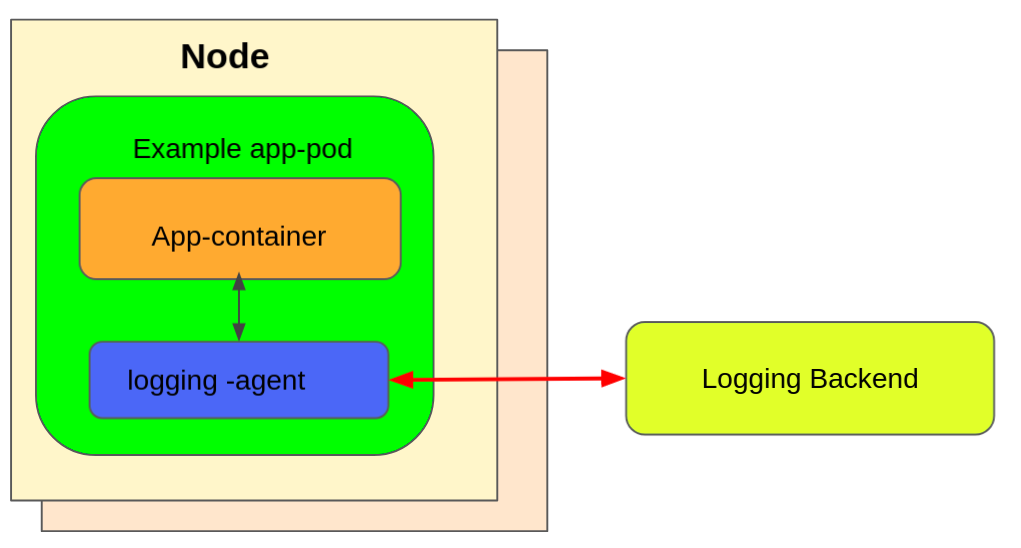
Sidecar container as logging agent例如,一个吊舱运行单个容器,容器使用两种不同的格式写入两个不同的日志文件。吊舱的配置文件如下:
- #log-sidecar.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- name: counter
- spec:
- containers:
- - name: count
- image: busybox
- args:
- - /bin/sh
- - -c
- - >
- i=0;
- while true;
- do
- echo "$i: $(date)" >> /var/log/1.log;
- echo "$(date) INFO $i" >> /var/log/2.log;
- i=$((i+1));
- sleep 1;
- done
- volumeMounts:
- - name: varlog
- mountPath: /var/log
- - name: count-log
- image: busybox
- args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
- volumeMounts:
- - name: varlog
- mountPath: /var/log
- volumes:
- - name: varlog
- emptyDir: {}
把它们放在一起,你可以运行这个吊舱:
- $ kubectl apply -f log-sidecar.yaml
要验证挎斗容器是否用作日志代理,你可以执行以下操作:
- $ kubectl logs counter count-log
预期的输出如下所示:
- $ kubectl logs counter count-log-1
- Thu 04 Nov 2021 09:23:21 NZDT
- Thu 04 Nov 2021 09:23:22 NZDT
- Thu 04 Nov 2021 09:23:23 NZDT
- Thu 04 Nov 2021 09:23:24 NZDT
将应用程序日志直接暴露给日志后端
第三种方法(在我看来)是 Kubernetes 容器和应用程序日志最灵活的日志记录解决方案,是将日志直接推送到日志记录后端解决方案。尽管此模式不依赖于原生 Kubernetes 功能,但它提供了大多数企业需要的灵活性,例如:
- 扩展对网络协议和输出格式的更广泛支持。
- 提供负载均衡能力并提高性能。
- 可配置为通过上游聚合接受复杂的日志记录要求。
因为这第三种方法通过直接从每个应用程序推送日志来依赖非 Kubernetes 功能,所以它超出了 Kubernetes 的范围。
结论
Kubernetes 日志记录工具是企业部署 Kubernetes 集群的一个非常重要的组件。我讨论了三种可能的可用模式。你需要找到适合你需求的模式。
如上所述,使用 daemonset 的节点级日志记录是最容易使用的部署模式,但它也有一些限制,可能不适合你的组织的需要。另一方面,挎斗 模式提供了灵活性和自定义,允许你自定义要捕获的日志类型,但是会提高计算机的资源开销。最后,将应用程序日志直接暴露给后端日志工具是另一种允许进一步定制的诱人方法。
选择在你,你只需要找到适合你组织要求的方法。