













在大数据时代,机器学习在提升产品销售、辅助人类决策的过程中能够起到很大的作用,但是计算机通常不会解释它们的预测结果。
我们在使用机器学习模型时,常用的模型性能评价指标有精度、查准率、查全率、ROC曲线、代价曲线等。如果一个机器学习模型表现得很好,我们是否就能信任这个模型而忽视决策的理由呢?答案是否定的。
模型的高性能意味着模型足够智能和“聪明”,但这不足以让我们了解它的运作原理,因此我们需要赋予模型“表达能力”,这样我们才能更加理解和信任模型。除了单一的性能评价之外,模型的评价还应该增加一个维度,以表示模型的“表达能力”,可解释性就是其中一个。
一 可解释性的定义
解释指的是用通俗易懂的语言进行分析阐明或呈现。对于模型来说,可解释性指的是模型能用通俗易懂的语言进行表达,是一种能被人类理解的能力,具体地说就是,能够将模型的预测过程转化成具备逻辑关系的规则的能力。
可解释性通常比较主观,对于不同的人,解释的程度也不一样,很难用统一的指标进行度量。我们的目标是希望机器学习模型能“像人类一样表达,像人类一样思考”,如果模型的解释符合我们的认知和思维方式,能够清晰地表达模型从输入到输出的预测过程,那么我们就会认为模型的可解释性是好的。
在《机器学习的挑战:黑盒模型正面临这3个问题》例举的基金营销小场景中,虽然模型能够判断一个客户有很大的可能性购买低风险、低收益的产品,但是模型不能解释客户倾向于购买低风险、低收益产品的更详细的原因,因此也就无法提出对这个客户来说更有针对性的营销策略,从而导致营销的效果不佳。
具备可解释性的模型在做预测时,除了给出推荐的产品之外,还要能给出推荐的理由。例如,模型会推荐一个低收益产品的原因是,该客户刚大学毕业,年纪还比较小,缺乏理财意识,金融知识也比较薄弱,尽管个人账户中金额不少,但是盲目推荐购买高收益产品,可能会由于其风险意识不足而导致更多的损失,因此可以通过一些简单的低风险理财产品,让客户先体验一下金融市场,培养客户的理财兴趣,过一段时间再购买高收益的产品。
模型的可解释性和模型的“表达能力”越强,我们在利用模型结果进行决策时便能达到更好的营销效果。
二 可解释性的分类
可解释机器学习的思想是在选择模型时,同时考虑模型的预测精度和可解释性,并尽量找到二者之间的最佳平衡。根据不同的使用场景和使用人员,我们大致可以将模型的可解释性作以下分类。
1. 内在可解释VS.事后可解释
内在可解释(Intrinsic Interpretability)指的是模型自身结构比较简单,使用者可以清晰地看到模型的内部结构,模型的结果带有解释的效果,模型在设计的时候就已经具备了可解释性。
如图2-1所示,从决策树的输出结果中我们可以清楚地看到,两个特征在不同取值的情况下,预测值存在差异。常见的内在可解释模型有逻辑回归、深度较浅的决策树模型(最多不超过4层)等。
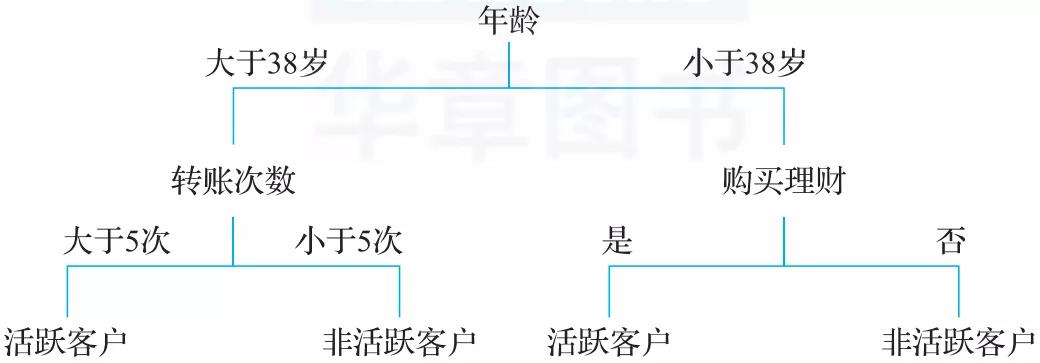
▲图2-1 决策树结果
事后可解释(Post-hoc Interpretability)指的是模型训练完之后,使用一定的方法增强模型的可解释性,挖掘模型学习到的信息。
有的模型自身结构比较复杂,使用者很难从模型内部知道结果的推理过程,模型的结果也不带有解释的语言,通常只是给出预测值,这时候模型是不具备可解释性的。事后可解释是指在模型训练完之后,通过不同的事后解析方法提升模型的可解释性。
如图2-2所示,利用事后解析的方法,可以对不同的模型识别结果给出不同的理由:根据吉他的琴颈识别出电吉他,根据琴箱识别出木吉他,根据头部和腿部识别出拉布拉多。常用的事后解析方法有可视化、扰动测试、代理模型等。
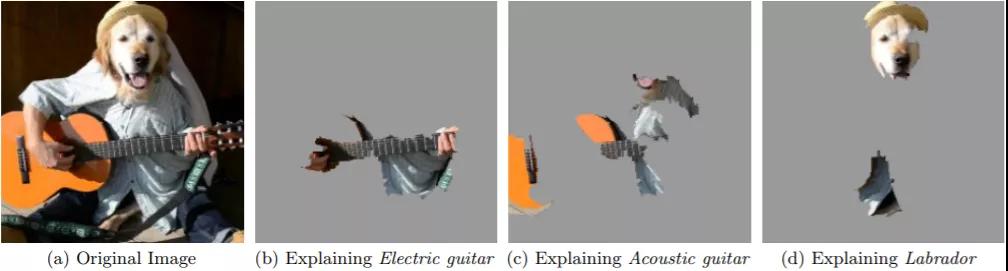
▲图2-2 事后解释:a. 原始图片,b. 解释为电吉他的原因,c. 解释为木吉他的原因,d. 解释为拉布拉多的原因(来源:论文“"Why Should I Trust You?"—Explaining the Predictions of Any Classifier”)
2. 局部解释VS.全局解释
对于模型使用者来说,不同场景对解释的需求也有所不同。对于整个数据集而言,我们需要了解整体的预测情况;对于个体而言,我们需要了解特定个体中预测的差异情况。
局部解释指的是当一个样本或一组样本的输入值发生变化时,解释其预测结果会发生怎样的变化。
例如,在银行风控系统中,我们需要找到违规的客户具备哪个或哪些特征,进而按图索骥,找到潜在的违规客户;当账户金额发生变化时,违规的概率会如何变化;在拒绝了客户的信用卡申请后,我们也可以根据模型的局部解释,向这些客户解释拒绝的理由。
图2-2展示的既是事后解释,也是一个局部解释,是针对输入的一张图片作出的解释。
全局解释指的是整个模型从输入到输出之间的解释,从全局解释中,我们可以得到普遍规律或统计推断,理解每个特征对模型的影响。
例如,吸烟与肺癌相关,抽烟越多的人得肺癌的概率越高。全局解释可以帮助我们理解基于特征的目标分布,但一般很难获得。
人类能刻画的空间不超过三维,一旦超过三维空间就会让人感觉难以理解,我们很难用直观的方式刻画三维以上的联合分布。因此一般的全局解释都停留在三维以下,比如,加性模型(Additive Model)需要在保持其他特征不变的情况下,观察单个特征与目标变量的关系;树模型则是将每个叶节点对应的路径解释为产生叶节点结果的规则。
3. 可解释机器学习的研究方向
可解释机器学习为模型的评价指标提供了新的角度,模型设计者在设计模型或优化模型时,应该从精度和解释性两个角度进行考虑。
图2-3所示的是可解释机器学习中模型精度和模型可解释性的关系,由香港大学张爱军教授提出,在学术界广为流传,图2-3中的横轴代表模型的可解释性,越往正方向,代表模型的可解释性越高;纵轴代表模型的精度,越往正方向,代表模型的精度越高。
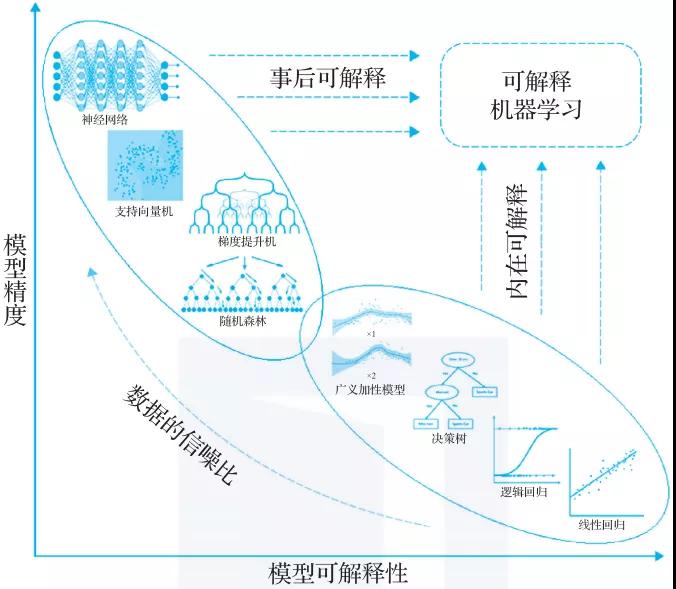
▲图2-3 可解释机器学习:模型精度和模型可解释性的关系(图片来源:?香港大学张爱军博士)
针对模型评价的两个指标,可解释机器学习有两大研究方向,具体说明如下。
第一,对于传统的统计学模型(比如决策树、逻辑回归、线性回归等),模型的可解释性较强,我们在使用模型时可以清楚地看到模型的内部结构,结果具有很高的可解释性。
然而一般情况下,这些模型的精度较低,在一些信噪比较高(信号强烈,噪声较少)的领域,拟合效果没有当下的机器学习模型高。
在保持模型的可解释性前提下,我们可以适当地改良模型的结构,通过增加模型的灵活表征能力,提高其精度,使得模型往纵轴正方向移动,形成内在可解释机器学习模型。比如,保持模型的加性性质,同时从线性拟合拓展到非线性拟合,GAMI-Net、EBM模型均属于内在可解释机器学习模型。
第二,当下的机器学习模型(比如神经网络、深度学习),其内部结构十分复杂,我们难以通过逐层神经网络或逐个神经元观察数据的变化,在一些信噪比较低(信号较弱,噪声强)的领域,我们很容易把噪声也拟合进去,不易发现其中的错误,模型的可解释性较低。
为了提高模型的可解释性,我们可以采用以下两种方法:
- 降低模型结构的复杂度,如减少树模型的深度,以牺牲模型的精度换取可解释性;
- 保持模型原有的精度,在模型训练完之后,利用事后辅助的归因解析方法及可视化工具,来获得模型的可解释性。
无论采用哪一种方法,其目的都是让模型往横轴的正方向移动,获取更多的可解释性。LIME和SHAP等方法均属于事后解析方法。
可解释机器学习的研究在学术界和工业界都引发了热烈的反响,发表的文章和落地应用逐年增长。无论是哪一个研究方向,可解释机器学习研究的最终目的都是:
- 在保证高水平学习表现的同时,实现更具可解释性的模型;
- 让我们更理解、信任并有效地使用模型。
关于作者:邵平,资深数据科学家,索信达控股金融AI实验室总监。在大数据、人工智能领域有十多年技术研发和行业应用经验。技术方向涉及可解释机器学习、深度学习、时间序列预测、智能推荐、自然语言处理等。现主要致力于可解释机器学习、推荐系统、银行智能营销和智能风控等领域的技术研究和项目实践。
杨健颖,云南财经大学统计学硕士,高级数据挖掘工程师,一个对数据科学有坚定信念的追求者,目前重点研究机器学习模型的可解释性。
苏思达,美国天普大学统计学硕士,机器学习算法专家,长期为银行提供大数据与人工智能解决方案和技术服务。主要研究方向为可解释机器学习与人工智能,曾撰写《可解释机器学习研究报告》和多篇可解释机器学习相关文章。
本文摘编自《可解释机器学习:模型、方法与实践》,经出版方授权发布。(ISBN:9787111695714)




















