近日,在英伟达团队发表的新论文中提到了一个神秘的显卡:GPU-N。
据网友推测,这很可能就是下一代Hopper GH100芯片的内部代号。

https://dl.acm.org/doi/10.1145/3484505
英伟达在这篇「GPU Domain Specialization via Composable On-Package Architecture」(通过可组合式封装架构实现GPU领域的专业化)的论文中,谈到了下一代GPU设计。
研究人员认为,当前要想提升深度学习性能,最实用的解决方案应该是最大限度地提高低精度矩阵计算的吞吐量。
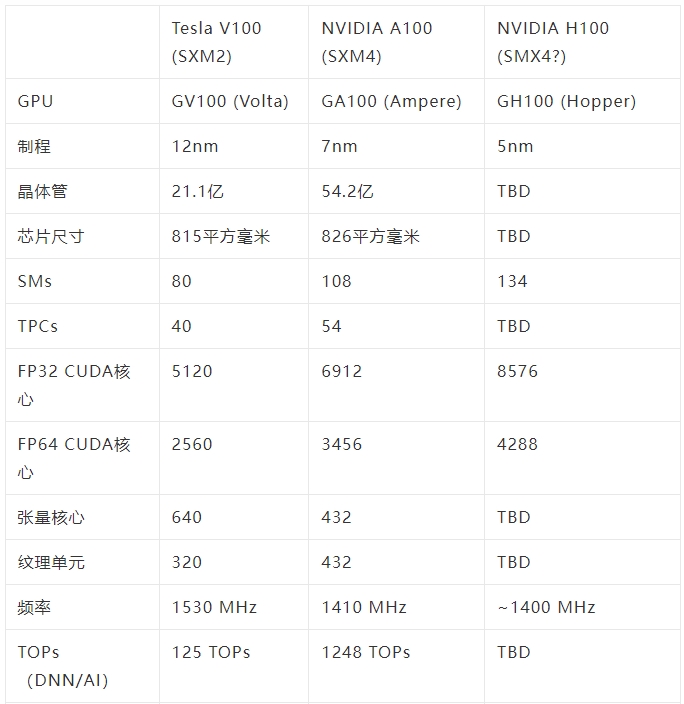
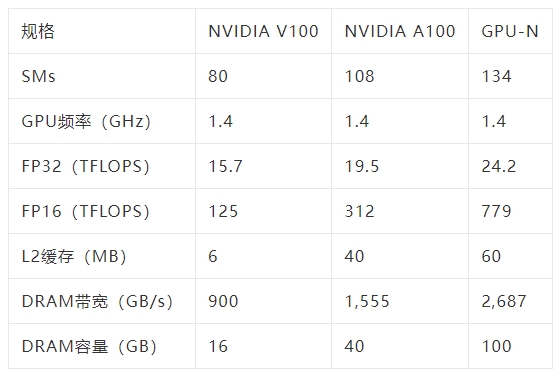
简单来说,GPU-N有134个SM单元(A100中为104个SM);8576个CUDA核心(比A100多24%);60MB的二级缓存(比A100多50%);2.687TB/秒的DRAM带宽(可扩展至6.3TB/秒);高达100GB的HBM2e(通过COPA实现可扩展到233GB),以及6144位内存总线。
全新COPA-GPU架构
「GPU-N」采用了一种叫COPA的设计。
目前,当GPU以扩大其低精度矩阵计算吞吐量的方式来提高深度学习(DL)性能时,吞吐量和存储系统能力之间的平衡会被打破。
英伟达团队最终得出一个结论,基于FP32(或更大)的HPC和基于FP16(或更小)的DL,两者的工作负载是不一样的。那么,运行两种任务的GPU架构也不应该完全一样。
而如果非得要求GPU满足不同的架构要求,去做一个融合设计,会导致任何一个应用领域的配置都不是最优的。
因此,可以给每个领域提供专用的GPU产品的可组合的(COPA-GPU)架构是解决这些不同需求的最实用的方案。
COPA-GPU利用多芯片模块分解,可以做到最大限度地支持GPU模块复用,以及每个应用领域的内存系统定制化。
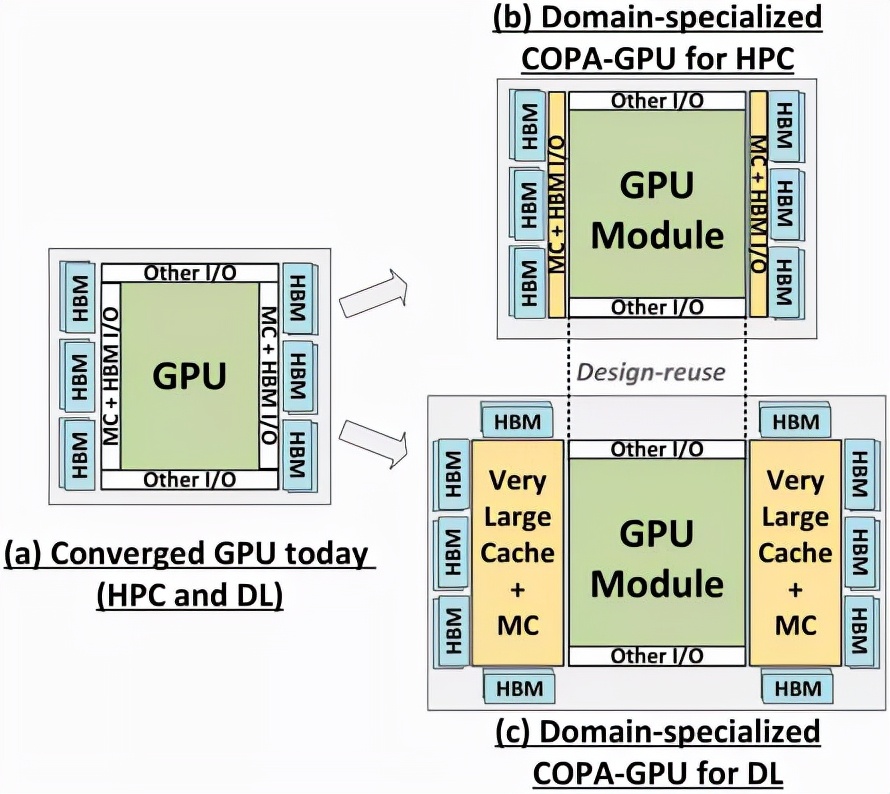
英伟达表示,COPA-GPU可以通过对基线GPU架构进行模块化增强,使其具有高达4倍的片外带宽、32倍的包内缓存和2.3倍的DRAM带宽和容量,同时支持面向HPC的缩减设计和面向DL的专业化产品。
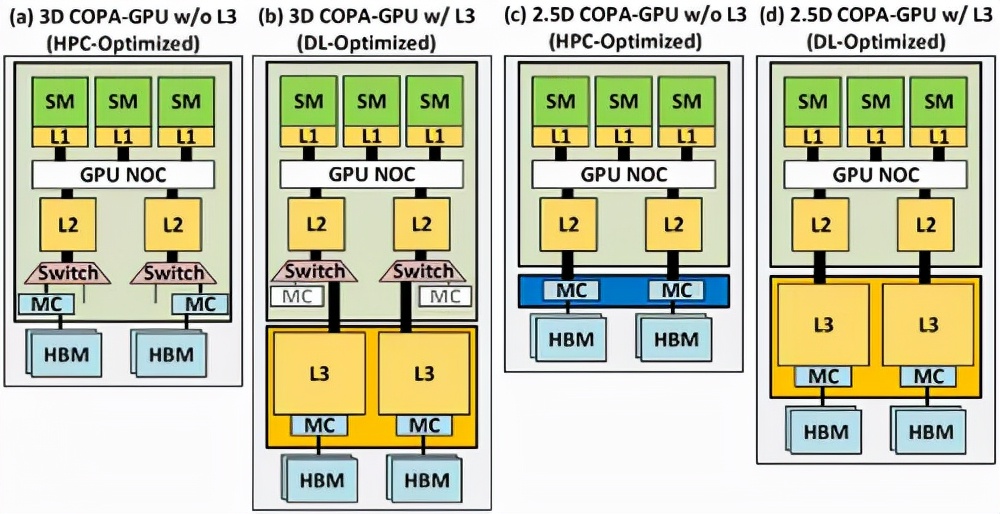
这项工作探索了实现可组合的GPU所必需的微架构设计,并评估了可组合架构为HPC、DL训练和DL推理提供的性能增益。
实验表明,与一个融合的GPU设计相比,一个对DL任务进行过优化的COPA-GPU具有16倍大的缓存容量和1.6倍高的DRAM带宽。
每个GPU的训练和推理性能分别提高了31%和35%,并在扩展的训练场景中减少了50%的GPU使用数量。
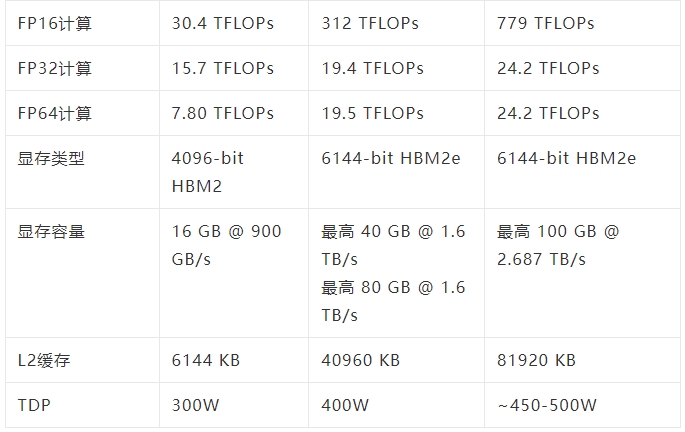
从纸面上的性能来看,「GPU-N」的时钟频率为1.4GHz(与A100的理论值相同),可以达到24.2 TFLOPs的FP32(是A100的1.24倍)和779 TFLOPs的FP16(是A100的2.5倍)。
与AMD的MI200相比,GPU-N的FP32的性能还不到一半(95.7 TFLOPs vs 24.2 TFLOPs),但GPU-N的FP16的性能却高出2.15倍(383TFLOPs vs 779TFLOPs)。
根据以往的信息可以推断,NVIDIA的H100加速器将基于MCM解决方案,并且会基于台积电的5nm工艺。
虽然不知道每个SM中的核心数量,但如果依然保持64个的话,那么最终就会有18,432个核心,比GA100多2.25倍。
Hopper还可以利用更多的FP64、FP16和Tensor内核,这将极大地提高性能。
GH100很可能会在每个GPU模块上启用144个SM单元中的134个。但是,如果不使用GPU稀疏性,英伟达不太可能达到与MI200相同的FP32或FP64 Flops。
此外,论文中还谈到了两种基于下一代架构的领域专用COPA-GPU,一种用于HPC,一种用于DL领域。
HPC变体采用的是非常标准的设计方案,包括MCM GPU设计和各自的HBM/MC+HBM(IO)芯片,但DL变体真的是一个很特殊的设计。
DL变体在一个完全独立的芯片上安装了一个巨大的缓存,与GPU模块相互连接。具有高达960/1920 MB的LLC(Last-Level-Cache),HBM2e DRAM容量也高达233GB,带宽高达6.3TB/s。
但是网友表示,英伟达似乎已经决定将重点放在DL性能上,因为FP32和FP64(HPC)性能的增长仅仅是来源于SM数量的增加。
这很可能在最后达不到传闻中的3倍性能。
鉴于英伟达已经发布了相关的信息,Hopper显卡很可能会在2022年GTC的大会上亮相。
规格预测