一周前,计算机视觉领域经典之作、何恺明的 ResNet 论文的被引次数突破了 10 万 +,而这距离他提交这篇论文仅过去六年。这一工作的热度如此之高,既显示出了 ResNet 本身的久经考验,也印证了 AI 领域,特别是计算机视觉如今的火热程度。
然而,ResNet 高被引的背后也让我们看到了一个问题,那就是计算机视觉领域每年产出那么多的新论文,为何研究者往往还是选择它作为引文呢?对高被引经典论文的趋向性究竟会给领域带来进步还是停滞呢?新发表的论文是否还有可能成为下一个经典之作呢?
在近日发表在 SCI 期刊 PNAS 上的一篇论文《Slowed Canonical Progress in Large Fields of Science》中,来自美国西北大学和芝加哥大学的两位研究者对上述问题进行了解答,并深入探讨了科学领域发表论文的数量、质量以及被引情况之间的错综复杂的关联。

论文地址:https://www.pnas.org/content/pnas/118/41/e2021636118.full.pdf
对科学进步有种很直接的观点,那就是多多益善。一个领域发表的论文越多,科学进步的速度就越快;研究者数量越多,覆盖的面就越广。即使并非每篇论文都产生重大的影响,但它们都成为了聚成沙堆的沙粒,增加了出现质变的可能性。在这一过程中,科学景观得到了重新配置,结构性探究中出现了新的范式。
更多论文的发表也增加了「它们之中至少有一篇包含重要创新」的可能性。一个颠覆性的全新想法可以动摇现状,将人们的注意力从以往工作中吸引过来,并获得大量的新引用。
领域内流行的政策很好地反映了这种多多益善的观点。人们会根据学者的生产力对他们进行评估和奖励,一段时间内发表更多的论文是他们获得终身教职和职位晋升的最可靠途径。数量仍是大学和公司展开比较的标杆,其中发表作品、专利、科学家和经费的总量仍是重中之重。
质量也主要通过数量进行判断。被引次数用来衡量一个领域内个人、团队和学术期刊的重要性。在论文层面,人们往往假定最好和最优价值的论文会吸引更多的关注,从而塑造了该领域的研究轨迹。
在文中,他们预测,当每年发表论文的数量非常大时,新论文的快速流动会迫使学界关注那些被广泛引用的论文,由此减少了对不太成熟的论文的关注,即使它们当中有些提出了新颖、有用和具有潜在变革性的想法。大量新发表论文的出现并没有引起领域范式的更快更迭,反而巩固了那些高引用量的论文,阻止新工作成为被引用最多且广为人知的领域经典之作。
研究者通过实验分析验证了这些观点,表明了科研单位对数量的关注可能阻碍基础性进步。随着每个领域每年所发表作品的持续增长,这种不利影响将加剧。并且,考虑到推动「发表数量至上」领域认知的根深蒂固、错综复杂的结构,这种情况将不可避免。重构科学生产力价值链的政策措施需要进行调整,以使大众重新聚焦于那些有潜力的新想法。
这篇文章主要讲了啥?
本文重点研究了领域大小,即给定的一年内某个领域发表论文数量的多少产生的影响。以往的研究发现,很多学科的引用不平等现象正在加剧,至少部分受到了偏好的影响。然而,一篇论文往往无法在过去几年保持它们的引用水平和排名。颠覆性论文能够取代以往的工作,被引次数的自然波动也会影响论文排名。
因而,研究者预测,当领域足够大时,变革动力会出现变化。引用最多的论文将根深蒂固,在未来获得不成比例的引用量。新论文无法通过偏好依附积累引用数,也就不可能成为经典。新发表的论文很少能够对已成型的学术桎梏产生影响。
他们给出了支撑以上预测的两个机制。一方面,当一个领域短时间内发表了很多论文时,学者不得不诉诸于启发式方法来对该领域进行持续性的理解。认知超载的评审人和读者在读新论文时不考虑里面的新想法,只会将它们与现有的范例论文联系起来。不符合现有模式的新想法有极大可能不会被发表、阅读或引用。
面对这种变革动力,论文作者不得不牢牢地将他们的工作与知名论文联系起来。这些知名论文充当起了「知识徽章」,界定了如何理解新工作,不鼓励他们研究太过新颖且不易于与现有经典之作联系起来的想法。这样一来,突破性新想法的产生以及被发表和广泛阅读的概率下降,并且每一篇新论文的发表也将不成比例地增加高被引论文的引用量。
另一方面,如果新想法的到来速度太快,它们之间的竞争可能会阻碍任何新想法在领域内广为人知和广泛接受。至于为什么会这样呢?研究者以某个领域中传播想法的沙堆模型为例进行解读。
当沙子慢慢落在沙堆上时,一次一粒,等到沙堆运动停止时再落下一粒。随着时间推移,沙堆达到了无标度临界状态,其中一粒沙子都能够引起整个沙堆区域的崩塌。但当沙子以极快的速度落下时,相邻的小型崩塌会相互干扰,导致任何一粒沙子都无法触发沙堆范围内的位移。这意味着,沙子掉落的速度越快,每个新沙粒能够影响的区域就越小。论文也一样,如果论文出现的速度太快,则任何一篇新论文都无法通过局部扩散和偏好依附成为经典。
这两方面的论点衍生出了六个预测,其中两个分别是最高引的论文将长期处于主导地位以及新发表论文的徒劳无功和它们自身颠覆性的降低。
总之,相较于一个领域每年发表的论文很少,当该领域每年产出的论文很多时,则将面临以下六种情况:
- 新论文将更有可能引用最高引的论文而不是低引用的论文;
- 每年最高引的论文列表几乎不会出现变化,导致经典论文始终是那些;
- 一篇新论文成为经典之作的概率将下降;
- 进入高引用论文列表的新论文不会通过循序累积的传播方式实现;
- 新发表论文中发展现有科研想法的比例增加,而颠覆现有想法的比例下降;
- 一篇新论文成为颠覆性工作的概率降低。
用到了哪些数据与方法?
研究者使用 Web of Science 数据集,分析了1960 至 2014 年间发表的论文,共计 90,637,277 篇论文和 1,821,810,360 个引用。Web of Science 将学术领域,或者某些情况下大的子领域,划分为不同的学科。因此,研究者的分类中共有 241 个学科,并将它们作为领域级分析的基础。其中,一篇焦点论文每年从同一主题新发表论文中收到的被引次数构成了研究者主要的兴趣变量。
为了计算 10 个最大的非综合学科(non-multidisciplinary)学科的 1-decay rate(λ),对于每个学科,研究者以发表论文数量的 10 log 划分年份,截点分别为 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5 和 5.5,并以 field-year 中被引最多的百分位划分论文年份,截点分别为 1, 2, 3, …, 100。对于每个(发表论文的记录数量)×(引用数百分位),他们将第二年一篇论文的被引次数回归到焦点年份论文的被引次数。这一回归的系数产生 1-λ。
此外,为了计算所有学科的 1-λ(图下图 2D 所示),研究者选取了第 1、2、5、10 和 25 个百分位数中被引最多的前 100 篇论文。他们通过发表论文数量的 base 10 log(截点分别为 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5 和 5.5)对 subject-years 进行分类。对于每个 bin× 选取的百分位,研究者将第二年一篇论文的被引次数回归到焦点年份论文的被引次数。这一回归的系数产生 1–λ。
这些预测得到证实了吗?
研究者的所有预测都在 Web of Science 数据集的引用模式中得到了证实,具体如下图 1 至 4 所示。随着领域变得越来越多,被引次数最多的论文始终成为主导,在引用分布上占据绝对优势。相比之下,新论文成为高引的可能性降低,并且无法随时间推移而逐渐累积关注度。发表论文往往在发展现有想法,而不具备颠覆性,也很少能够产生具有开拓性的新的研究潮流。
具体而言,被引次数最多的论文在更大的领域获得了不成比例的更高的引用份额。最大领域引用份额的基尼系数约为 0.5,如下图 1A 所示。高引论文不成比例的被引次数又导致不平等关注的加剧。
例如,当电气与电子工程领域每年发表 10,000 篇论文左右时,前 0.1% 和前 1% 高被引论文占了总被引次数的 1.5% 和 8.6%。当该领域每年发表 50,000 篇论文时,前 0.1% 和前 1% 高被引论文占了总被引次数的 3.5% 和 11.9%。当该领域规模更大,每年发表 100,000 篇论文时,前 0.1% 和前 1% 高被引论文占了总被引次数的 5.7% 和 16.7%。
相比之下,排名最后 50% 的被引最少论文在总被引次数中所占份额下降,每年发表 10,000 篇论文时的占比为 43.7%,每年发表论文达到 50,000 和 100,000 时,这一比例仅略高于 20%。
当跨越时间查看领域数据时,我们会发现存在这样的模式:当每年发表的论文数量较多时,被引用最多的 top-50 论文之间的排名相关性增加(图. 1B)。在随后几年斯皮尔曼排名相关性中,在一个领域中被引用最多的 top-50 列表从发表 1,000 篇论文时的 0.25 增加到 100,000 篇论文时的 0.74。
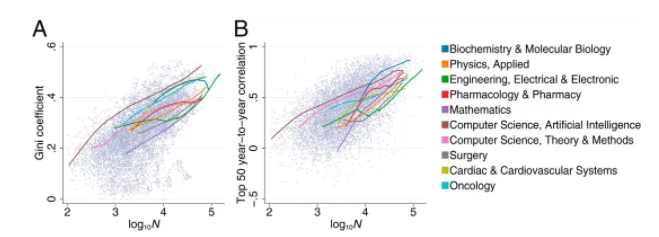
图 1
当领域范围很广时,被引用最多的论文的被引次数保持逐年增长,而所有其他论文的被引次数都会下降。下图 2 为论文当年与上一年被被引次数的预测比率。在论文发表很少的年份,被被引次数最多的论文的比率明显低于 1,与被被引次数较少的论文的比率没有太大区别。然而,在发表论文数量较多的年份,被被引次数最多的论文的比率接近 1,明显高于被被引次数少的论文。
在非常大的领域年中,发表了大约 100,000 篇论文,平均而言,被引用最多的论文的被引次数没有逐年下降。相比之下,排名在 top 1% 之外的论文,平均每年损失约 17% 的被引次数,而处于 top 5% 及以下的论文则趋向于每年损失 25% 的被引次数。
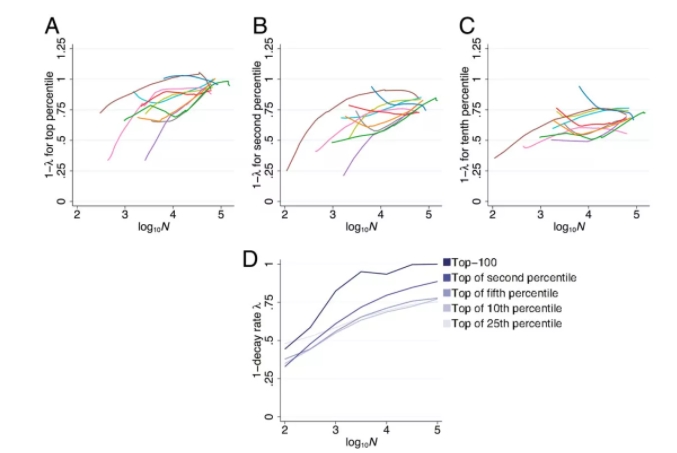
图 2
当同一领域同时发表许多论文时,单篇论文的引用量达到 top 0.1% 的可能性会减少,这种现象在同一年的不同领域或不同年的同一领域都适用,如图 3A 所示。一般来说,较大领域论文被引用最多,很少是通过局部扩散等过程完成。
图 3B 显示了一篇文章进入相关领域的平均时间(以年为单位),条件是该论文成为该领域中被引次数最多的论文之一。当一个领域很小时,论文会随着时间的推移缓慢上升到被被引次数最多的 top 0.1%。我们以 1980 年在小领域(回归预测)发表的论文为例,假如同一领域发表了 1000 篇论文,想要成为被引用最多的论文,平均需要 9 年时间。相比之下,在最大领域经典论文会迅速登上引用榜首,这与学者通过阅读他人著作中引用的参考资料发现新著作的累积过程不一致。同样的回归预测,在每年发表 100,000 篇论文的大领域中,论文达到引用量 top 0.1% 的时间平均不到一年。
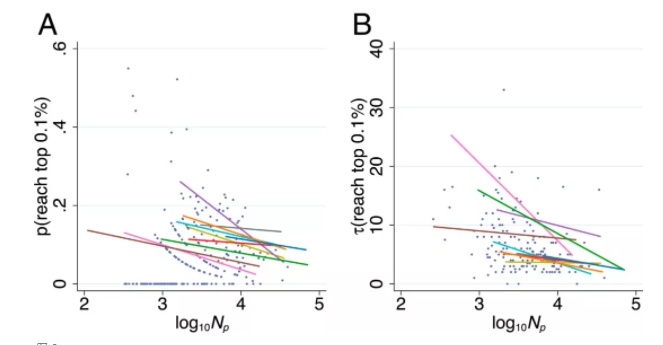
图 3
同一年发表的大多数论文都建立在现有文献的基础上,而不是中断(disrupt)现有文献(图 4A)。逻辑拟合预测显示,当该领域一年发表 1,000 篇论文时,49% 的论文具有中断度量(disruption measure) D > 0(相反,51% D < 0)。当发表 10,000 篇论文时,中断度量比例下降到 27%,发表 100,000 篇论文时下降到 13%。即使当 D > 0 时,新发表论文的中断度量在更大的领域中也会减弱。图 4B 显示了按领域年排列的新论文比例,这些论文在中断度量的 top-5 百分位中排名。Lowess 估计显示,具有 top-5 百分位中断度量的新论文比例从该领域年发表的 1,000 篇论文时的 8.8% 减少到每年 10,000 篇论文时的 3.6% 和 100,000 篇论文时的 0.6%。
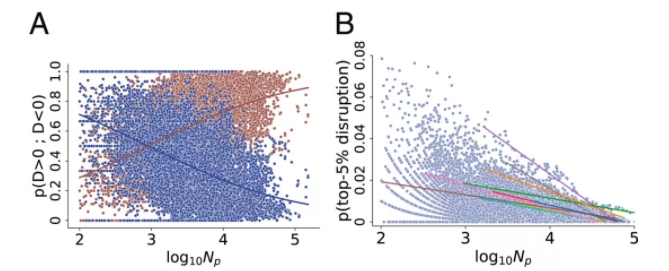
图 4