本文转载自微信公众号「网管叨bi叨」,作者 KevinYan11。转载本文请联系网管叨bi叨公众号。
线上服务的性能分析,一直以来都是比较难的点,主要是难在无法在性能出现异常的当时捕捉到现场信息。有人可能会说,这有什么难的,直接用 Go 工具集里的 pprof 访问一下,进行采样拿下来分析就行了。话虽不假,不过抛开现实场景谈解决方案一般都会非常打脸,真的不行。
举个现实中的例子,比如服务可能由于哪里的代码写的不好,内存占用率一点点涨上来,表现出来的现象就是服务隔一段时间就会重启一次(被集群重新拉起来),如果服务部署在 K8s上,那 K8s 集群更是会发现 Pod 的资源超限后把 Pod 杀掉重新创建一个。即使你能 24 小时 Oncall,在收到告警的那一刻程序可能已经重启了,所以传统的访问 pprof 路由主动采样在这种场景下不可取。
前段时间发表的文章学会这几招让 Go 程序自己监控自己 有读者问到,让Go程序监控自己进程的各项指标有何用处,我的回答是可以做一些服务治理,或者程序内部分析的事情。今天就借此跟大家分享一下,怎么给 Go 程序做自动采样。
下面我带着大家先看一看 Go 程序怎么采样,再剖析一下怎么让 Go 程序进行自动采样。
Go 的采样工具
Go的pprof工具集,提供了Go程序内部多种性能指标的采样能力,我们常会用到的性能采样指标有这些:
- profile:CPU采样
- heap:堆中活跃对象的内存分配情况的采样
- goroutine:当前所有goroutine的堆栈信息
- allocs: 会采样自程序启动所有对象的内存分配信息(包括已经被GC回收的内存)
- threadcreate:采样导致创建新系统线程的堆栈信息
怎么获取采样信息
网上最常见的例子是在服务端开启端口让客户端通过HTTP访问指定的路由进行各种信息的采样
- import (
- "net/http/pprof"
- )
- func main() {
- http.HandleFunc("/debug/pprof/heap", pprof.Index)
- http.HandleFunc("/debug/pprof/profile", pprof.Profile)
- http.HandleFunc("/", index)
- ......
- http.ListenAndServe(":80", nil)
- }
- $ go tool pprof http://localhost/debug/pprof/profile
这种方法的弊端就是
- 需要客户端主动请求特定路由进行采样,没法在资源出现尖刺的第一时间进行采样。
- 会注册多个/debug/pprof类的路由,相当于对 Web 服务有部分侵入。
- 对于非 Web 服务,还需在服务所在的节点上单独开 HTTP 端口,起 Web 服务注册 debug 路由才能进行采集,对原服务侵入性更大。
Runtime pprof
除了上面通过HTTP访问指定路由进行采样外,还有一种主要的方法是使用runtime.pprof 提供的Lookup方法完成各资源维度的信息采样。
- // lookup takes a profile name
- pprof.Lookup("heap").WriteTo(some_file, 0)
- pprof.Lookup("goroutine").WriteTo(some_file, 0)
- pprof.Lookup("threadcreate").WriteTo(some_file, 0)
CPU的采样方式runtime/pprof提供了单独的方法在开关时间段内对 CPU 进行采样
- bf, err := os.OpenFile('tmp/profile.out', os.O_RDWR | os.O_CREATE | os.O_APPEND, 0644)
- err = pprof.StartCPUProfile(bf)
- time.Sleep(2 * time.Second)
- pprof.StopCPUProfile()
这种方式是操作简单,把采样信息可以直接写到文件里,不需要额外开端口,再手动通过HTTP进行采样,但是弊端也很明显--不停的采样会影响性能。固定时间间隔的采样(比如每隔五分钟执行一次采样)不够有针对性,有可能采样的时候资源并不紧张。
适合采样的时间点
经过了上面的分析,现在看来只要让Go进程在自己占用资源突增或者超过一定的阈值时再用pprof对程序Runtime进行采样,才是最合适的,那么接下来我们就要想一下,到底以什么样的规则,才能判断出当前周期是适合采样的时段呢。
判断采样时间点的规则
CPU 使用,内存占用和 goroutine 数,都可以用数值表示,所以无论是使用率慢慢上升直到超过阈值,还是突增之后迅速回落,都可以用简单的规则来表示,比如:
- cpu/mem/goroutine数 突然比正常情况下的平均值高出了一定的比例,比如说资源占用率突增25%就是出现了资源尖刺。
- cpu/mem/goroutine数 超过了程序正常运行情况下的阈值,比如说80%就定义为服务资源紧张。
这两条规则可以描述大部分情况下的异常,第一个规则可以表示瞬时的,剧烈的抖动,之后可能迅速恢复正常的情况。
规则二可以用来表示那些缓慢上升,但最终超出阈值的情况,例如下图中内存使用率一直在慢慢上升,直到超过了设置的80%的阈值。
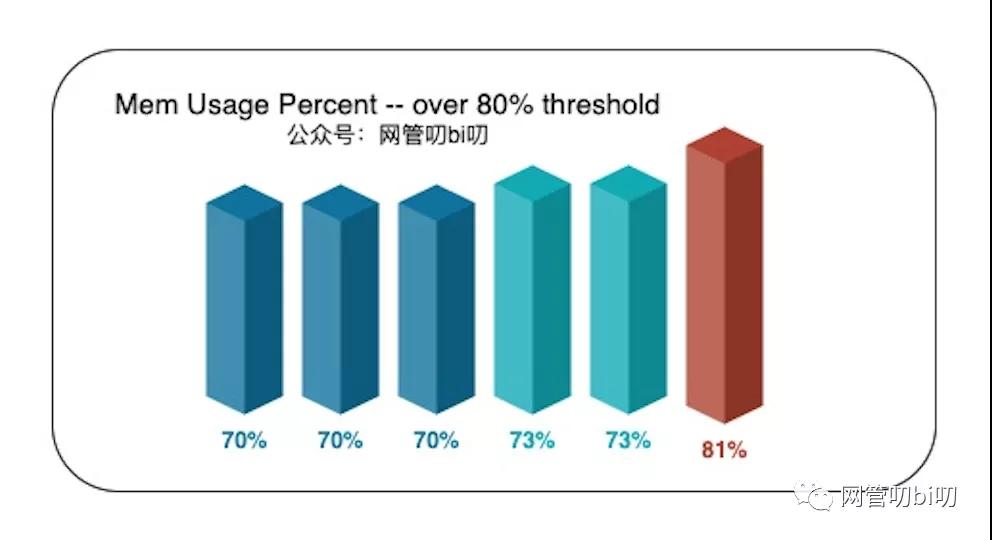
内存使用率超过80%
而规则一判断资源突增,需要与历史均值对比才行。在没有历史数据的情况下,就只能在程序内自行收集了,比如进程的内存使用率,我们可以以每 10 秒为一个周期,运行一次采集,在内存中保留最近 5 ~ 10 个周期的内存使用率,并持续与之前记录的内存使用率均值进行比较:
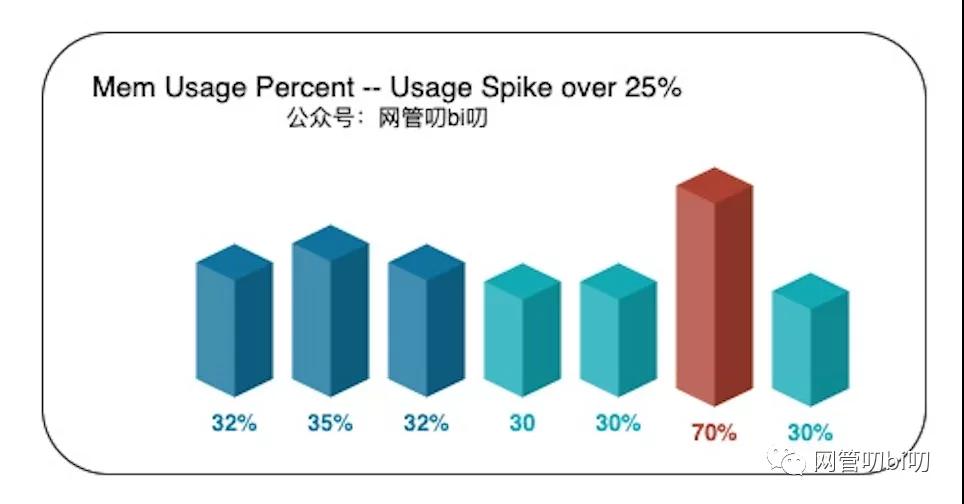
内存使用率突增超过25%
比如像上图里的情况,前五个周期收集到的内存占用率在 35% 左右波动,而最新周期收集到的数据为70%,这显然是瞬时突增导致的异常情况,那么我们就可以在这个时间点,自动让程序调用 pprof 把 mem 信息采样到文件里,后续无论服务是否已重启都能把采样信息拿下来分析。
而关于怎么让Go程序获取本进程的CPU、Mem使用量在系统中的占比,我们在之前的文章 学会这几招让 Go 程序自己监控自己 已经跟大家分享过了,只需要编码实现在上面描述的两个采样时机进行性能采样即可。
开源的自动采样库
社区里其实已经有开源库实现了类似的功能,比如曹大在蚂蚁的时候设计的Holmes ,其实曹大在桃花源公众号里发文章分享过。
使用起来也比较方便,比如下面是一个对内存使用率突增 25% 和超过阈值 80% 这两种情况下让程序自动进行Mem信息采样的例子。如果你公司里的基建还没有到把持续采样做到统一平台里的水平的话,Holmes 是一个比较好的选择,能快速解决问题,比较适合中小型的业务快速发展的团队。
简单的看一个 Web 服务接入 Holmes 分析内存占用率的例子。
- package main
- import (
- "net/http"
- "time"
- "github.com/mosn/holmes"
- )
- func init() {
- http.HandleFunc("/make1gb", make1gbslice)
- go http.ListenAndServe(":10003", nil)
- }
- func main() {
- h, _ := holmes.New(
- holmes.WithCollectInterval("2s"),
- holmes.WithCoolDown("1m"),
- holmes.WithDumpPath("/tmp"),
- holmes.WithTextDump(),
- holmes.WithMemDump(3, 25, 80),
- )
- h.EnableMemDump().Start()
- time.Sleep(time.Hour)
- }
- func make1gbslice(wr http.ResponseWriter, req *http.Request) {
- var a = make([]byte, 1073741824)
- _ = a
- }
- WithCollectInterval("2s") 指定 2s 为区间监控进程的资源占用率, 线上建议设置大于10s的采样区间。
- WithMemDump(3, 25, 80) 指定进程的mem占用率超过3%后(线上建议设置成30),如果有25%突增,或者总占用率超过80%后进行采样
通过采样能获取到了内存资源突增时的程序调用栈,[1: 1073741824] 表示有一个对象消耗了1GB的内存,通过调用栈分析我们也能快速找到找到造成资源占用的代码位置。
- heap profile: 0: 0 [1: 1073741824] @ heap/1048576
- 0: 0 [1: 1073741824] @ 0x42ba3ef 0x4252254 0x4254095 0x4254fd3 0x425128c 0x40650a1
- # 0x42ba3ee main.make1gbslice+0x3e /Users/xargin/go/src/github.com/mosn/holmes/example/1gbslice.go:24
- # 0x4252253 net/http.HandlerFunc.ServeHTTP+0x43 /Users/xargin/sdk/go1.14.2/src/net/http/server.go:2012
- # 0x4254094 net/http.(*ServeMux).ServeHTTP+0x1a4 /Users/xargin/sdk/go1.14.2/src/net/http/server.go:2387
- # 0x4254fd2 net/http.serverHandler.ServeHTTP+0xa2 /Users/xargin/sdk/go1.14.2/src/net/http/server.go:2807
- # 0x425128b net/http.(*conn).serve+0x86b /Users/xargin/sdk/go1.14.2/src/net/http/server.go:1895
关于这个库更详细的使用介绍可以直接看仓库提供的Get Started 教程 https://github.com/mosn/holmes
另外我还做了个docker 方便进行试验,镜像已经上传到了Docker Hub上,大家感兴趣的可以Down下来自己在电脑上快速试验一下。
通过以下命令即可快速体验。
docker run --name go-profile-demo -v /tmp:/tmp -p 10030:80 --rm -d kevinyan001/go-profiling
容器里Go服务提供的路由如下
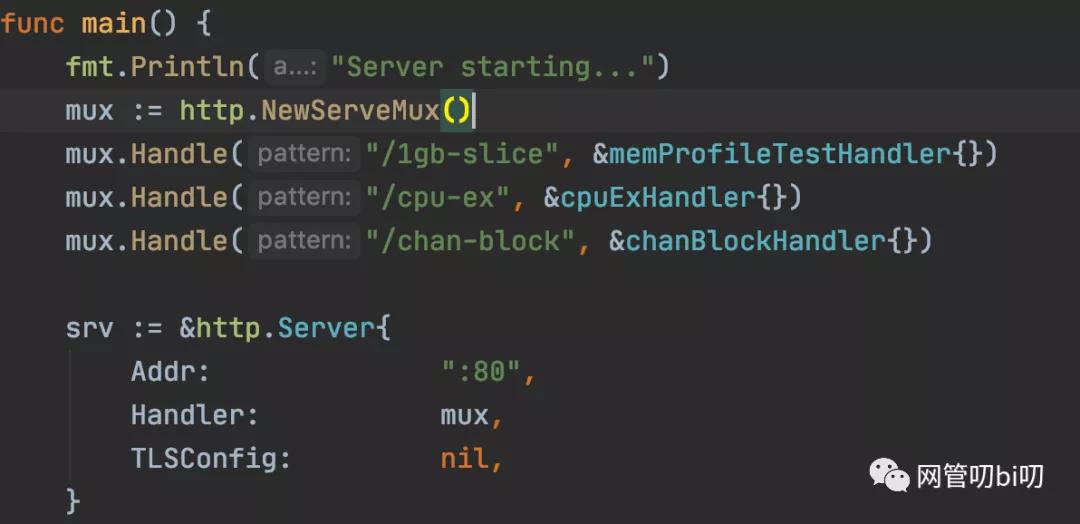
Holmes 试验容器的路由
三个路由分别对应了内存、CPU过载、通道阻塞,可以直接压测访问,观察效果。自动采样的结果除了进到容器里去看外,还可以在本地和容器做映射的 /tmp 目录中找到。