元宇宙SDN控制器?
小伙伴们对昨天利用BloomFilter过滤找到密接通信对而画出的3D拓扑图很感兴趣。
其实它是基于3D js[1]库实现的,具体如何做渲染可以看昨天分享的zbf的代码。
当然还有一个项目是3d-force-graph-vr[2]。
等渣有空了买个VR眼镜应该随手撸几行代码就可以实现类似于切水果的ACL动态阻断,或者基于拖拽的Ruta的灵活路径规划和流量工程。

华为 Compute-Native Networking
前几天收到一封来自华为的邮件,讲了一下它们新的总线协议,突破内存墙和I/O墙,领导数据时代计算系统创新生态型格局。这是在APNet 2021上的一个主题演讲[3]:
从原理上看,Compute-native networking(后文缩写成HCNN)的提出是很不错的。
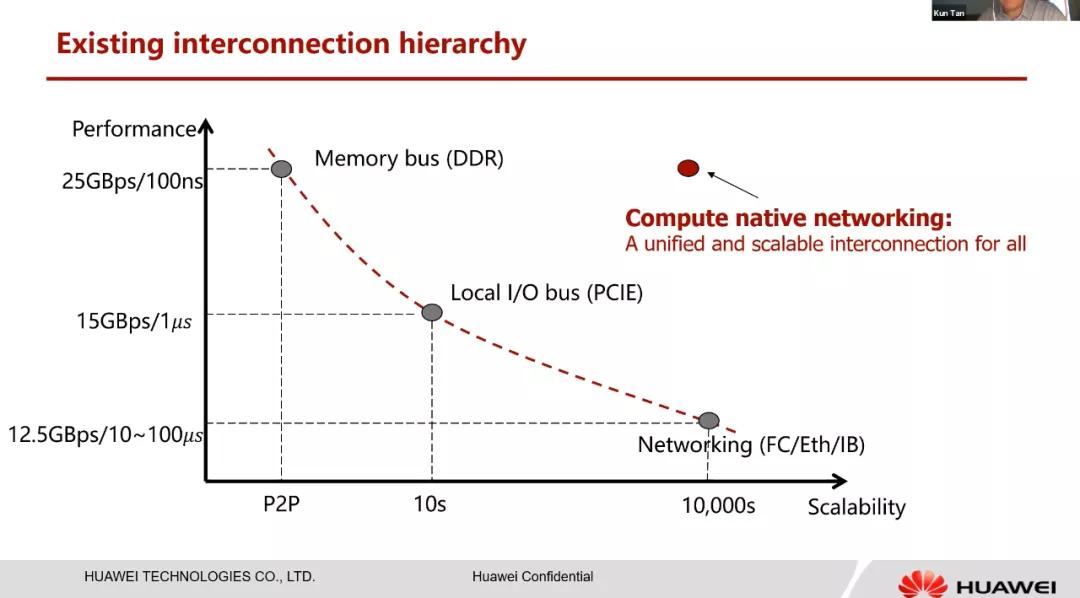
Compute-Native对于延迟和带宽的追求以及对于通信容量的追求,这图写的非常好。PCIe、CXL都因为其总线原因编址和拉远都存在问题。而超大规模计算的需求在那,这个是大家都要去解决的。整个思路和NetDAM是类似的,但有一点不同的是,整个UB他们是采用的特殊的通信协议:

而NetDAM采用的以太网UDP。
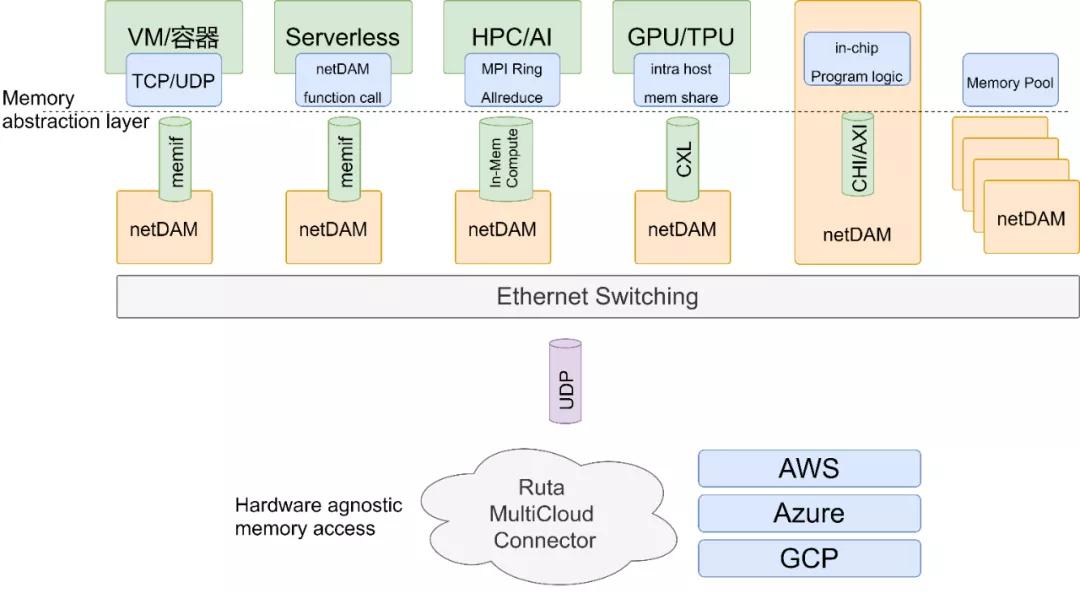
其实很多技术,要推倒重来有各种处理方法都非常容易,但是整个行业又有谁愿意来推倒重来给你做嫁衣? NetDAM项目最早是2020年跟第四范式谈合作的时候研发的,最初的想法也就是直接做PCIe Switch然后扩展成一个更好寻址的总线,后面还有一些讨论直接利用IP Packet预留寄存器区域和指令的方式来实现Cache一致性和多机同步,这些都是片面的追求极致化而不顾生态的行为。
但是保持开放和持续的后向兼容才是王道,同时能够读懂别的架构师在各种约束下的取舍也是十分重要的。例如在HPC这样的多机访问场景中,具有统一地址空间的访问是很不错的选择,RDMA本身的通信方式带来了计算规模的瓶颈,HCNN采用了如下的寻址方式:
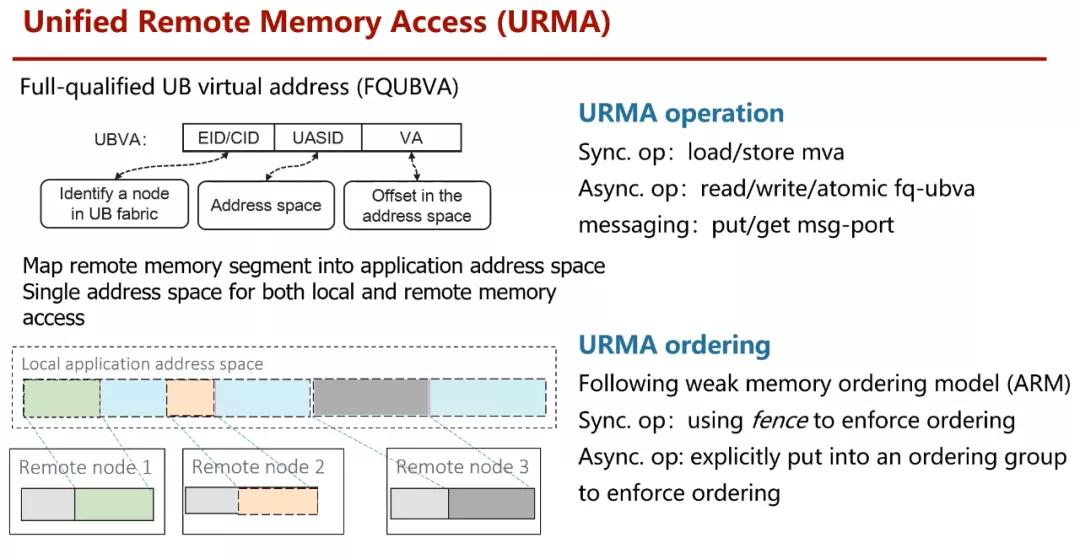
从通信层面上看,的确报文尺寸更小,但是直接寻址对于故障隔离和冗余保护都极为不利,而且整个交换路由网络都要重新设计,并且最终和其它设备访问还需要添加特殊的网卡不便于利旧。而NetDAM直接利用P4交换机构建MMU的方式,并且完全支持以太网,整个生态环境上会好很多,Intel、AMD、BRCM、Cisco等很多厂家都有用以太网替代RDMA的利益冲动,而RDMA本身又因为DMA导致处理器在超过200Gbps的情况下会导致大量的Cache miss,另一方面是利旧的原因,例如Fungible这类的东西要求全网更新是完全不可能的,因此构造一个任何设备都可以UDP访问的接口又给NetDAM这个协议增加了很多平滑迁移的可能性。
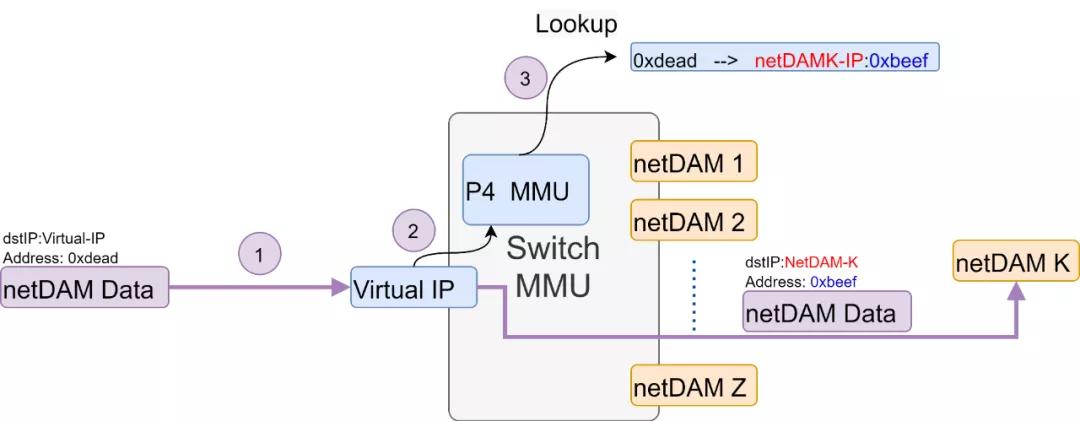
通过IP地址+内存地址,甚至是IPv6地址内嵌内存页地址才是Compute-Native网络的最终路径,IP协议的腰是很难撼动的。
至于计算指令,有些东西物理的延迟就在那里,通过计算范式去做,例如Rust一类语言对内存所有权的管理或许才是未来,而计算上,HCNN的UB简单的照搬以往的指令。
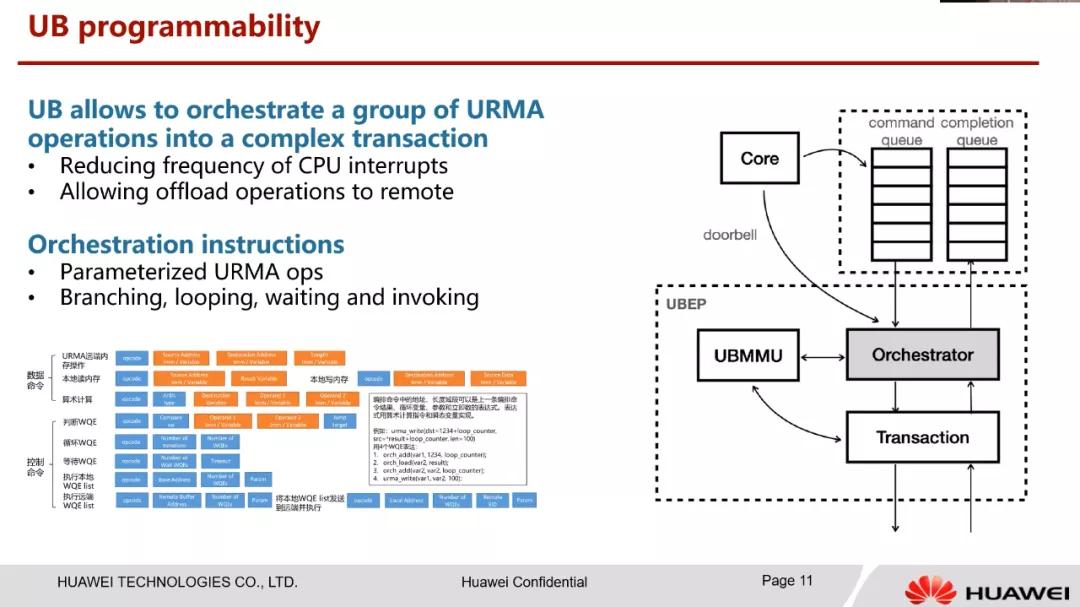
我们做NetDAM也考虑过同样的处理方式,但是很快就放弃了,因为我们更多的只是做一些Vector、Matrix的Offload,Scalar的处理Offload就等于扯淡。这里TensTorrent的一张图堪称经典。
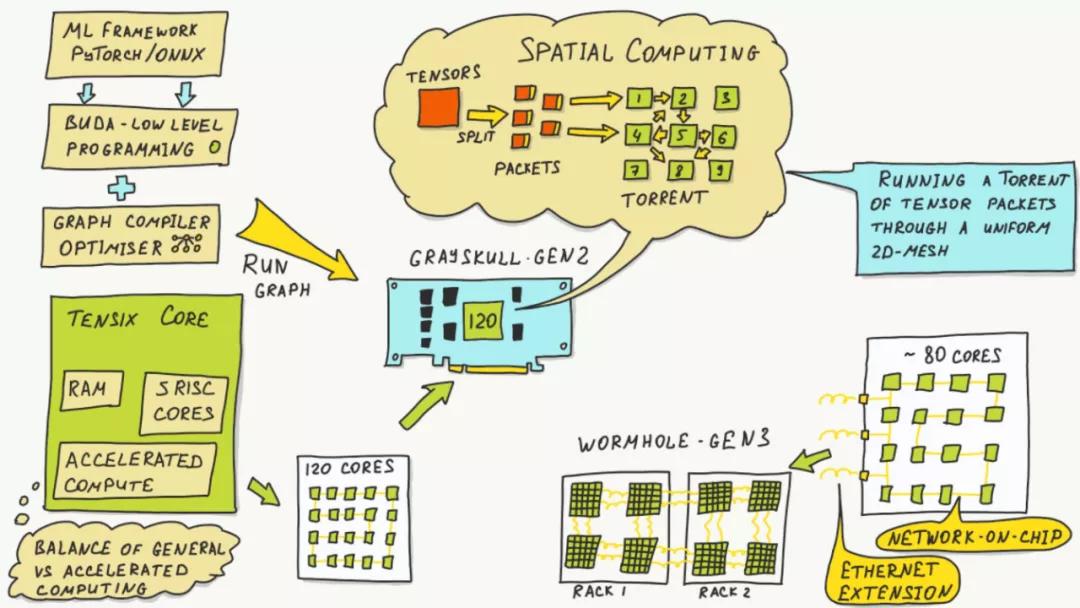
把Tensors拆分成packets,然后利用一个类似于BitTorrent的结构一边转发一边计算,所以我一直说这件事情上Jim Keller和他的小伙伴们是看清楚了的,具体可以看如下的Video:
https://www.youtube.com/watch?v=KOHQQyAKY14
TensTorrent的芯片结构也值得大家去好好学习一下:
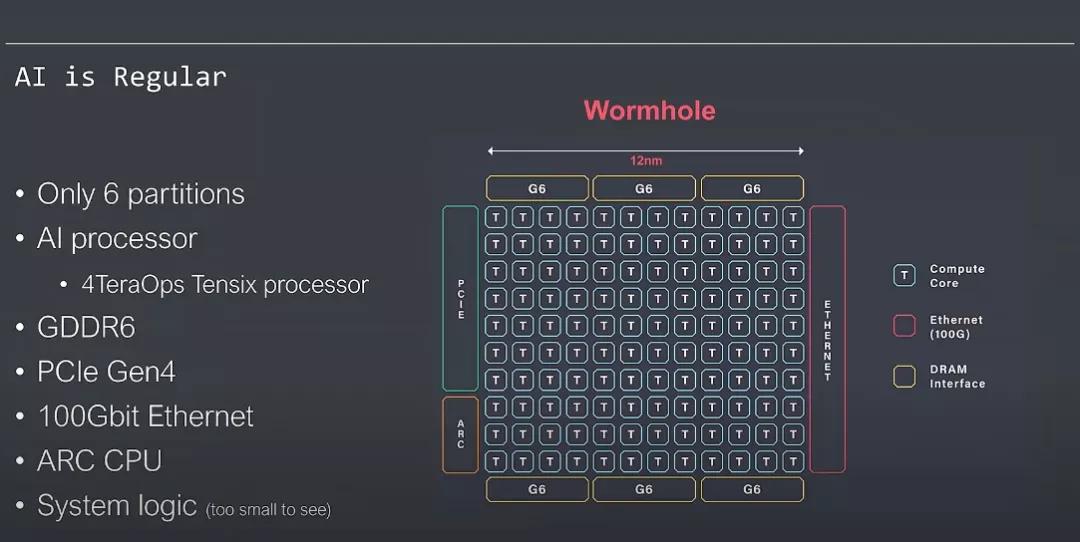
最关键的是利用标准的RISC-V核,非常漂亮,这也是架构师必须要考虑的问题,对上的生态兼容问题和编程灵活性的问题:
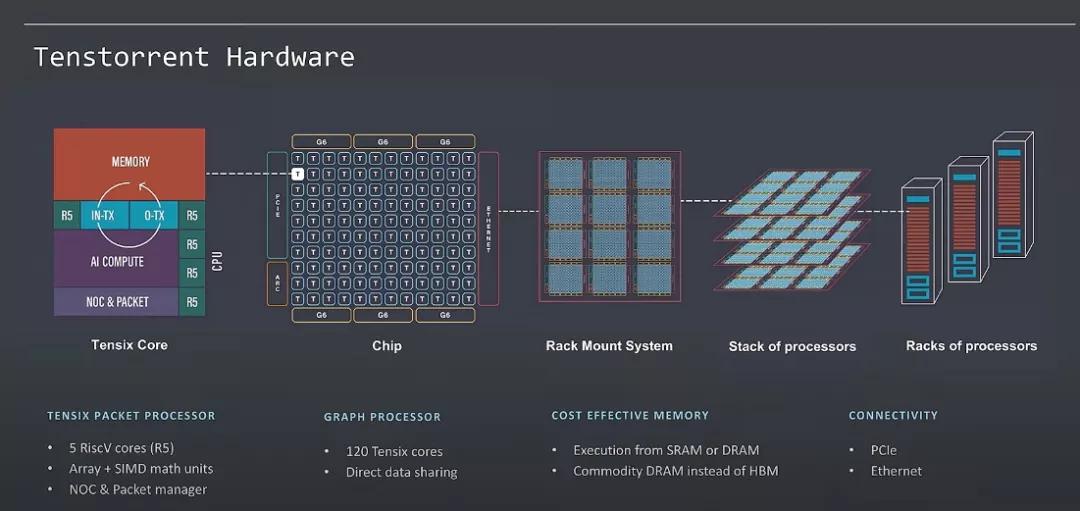
当然思科的QFP在20年前也是采用同样的方法,2D-Mesh的片上网络,然后标准的C编译环境,多芯片互联[4]。
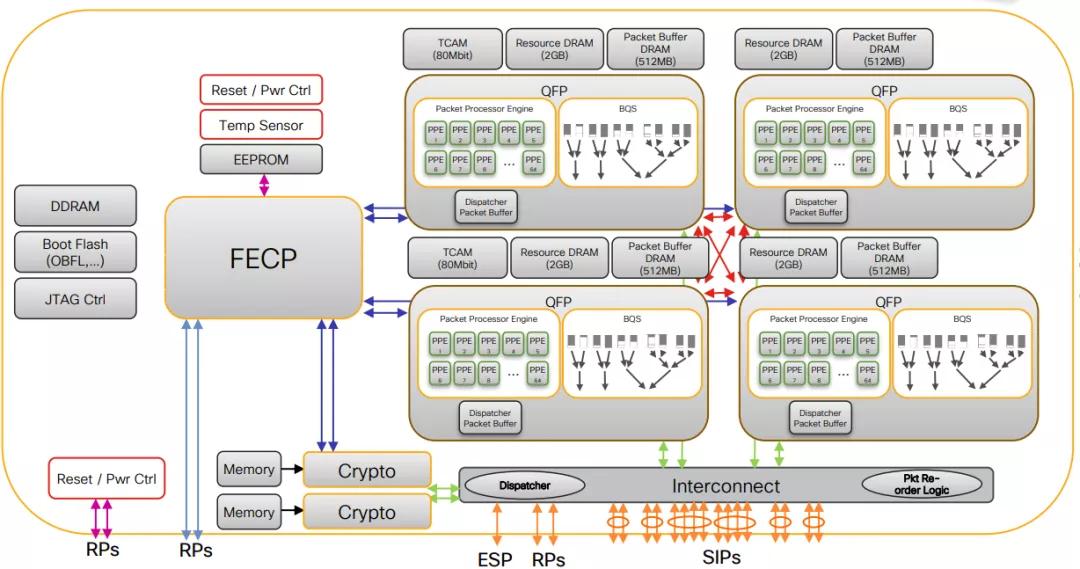
因此我们在NetDAM的设计中也使用UDP使得用户态可以非常灵活的编程产生指令,同时针对内存访问,还可以提供类似于memif的结构给其它编程语言。
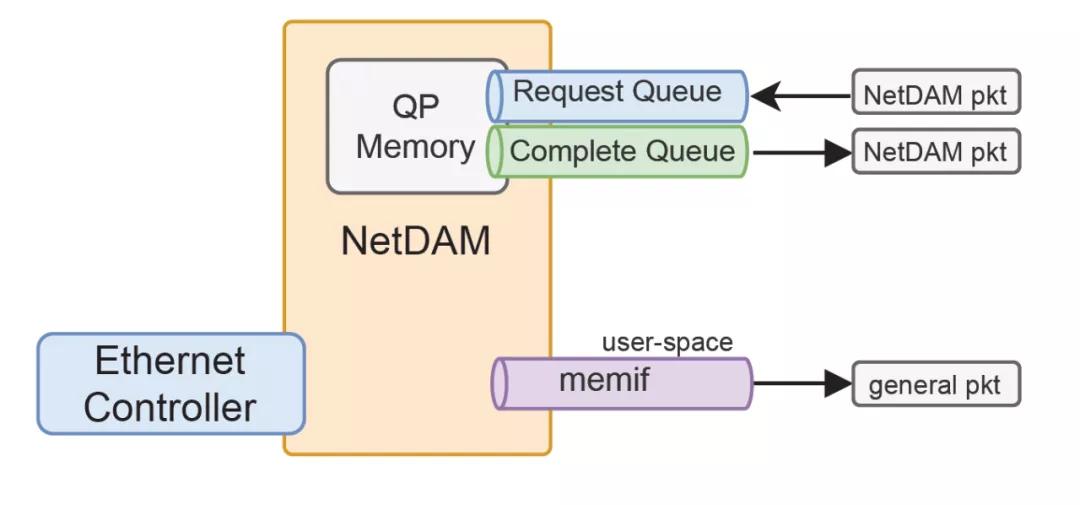
至于某个DPU公司,看过一些当年的文档[5] 有些东西over-engineering了。
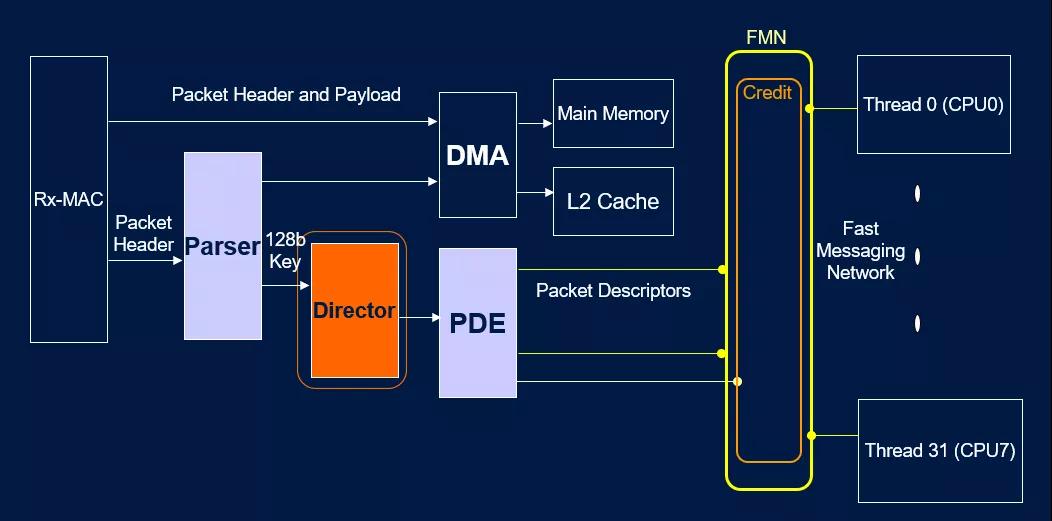
自然而然在灵活性上产生了缺失...其实很多产品都这样,设计时以处理器为中心:
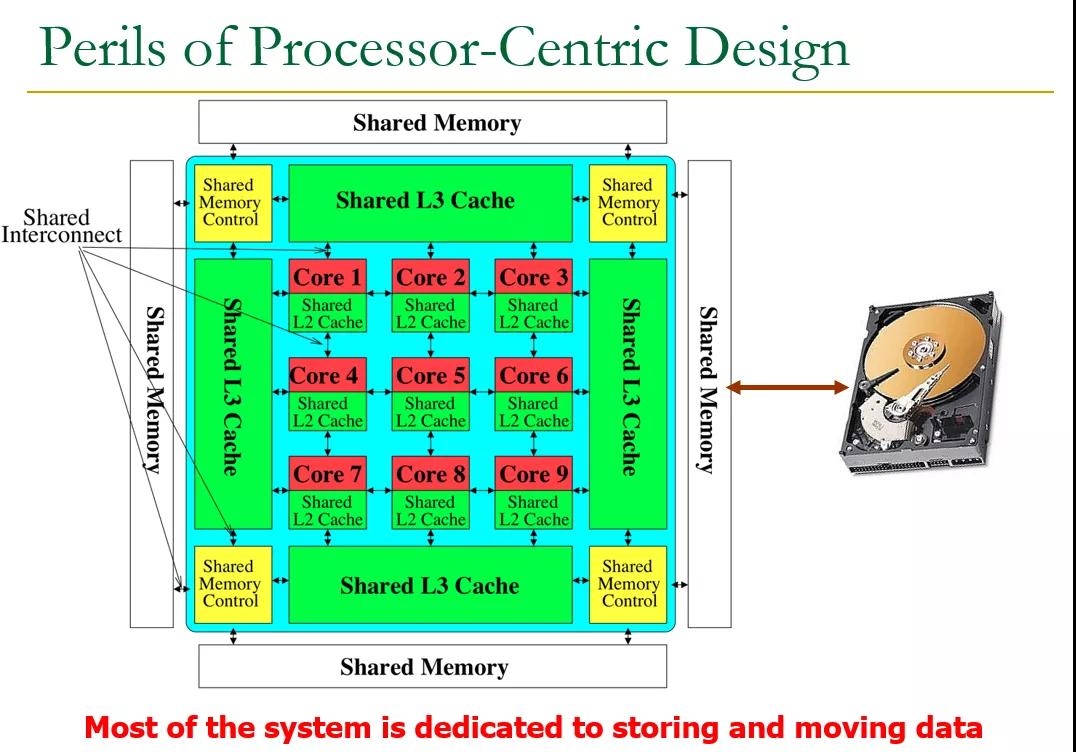
因此从这个结论上来看,Compute-Native networking 只看到了一个很片面的视角,而更多的是以Data-Centric为主,特别是在各个公司都承诺3060碳中和的时候,最应该关注的便是数据的移动。

所以NetDAM会在上面放置一些ALU,实现近存计算(Nearly-In-Memory)或者在转发报文的时候实现随路计算。把一些ALU放置在靠近内存和靠近通信的位置就是NetDAM的价值。
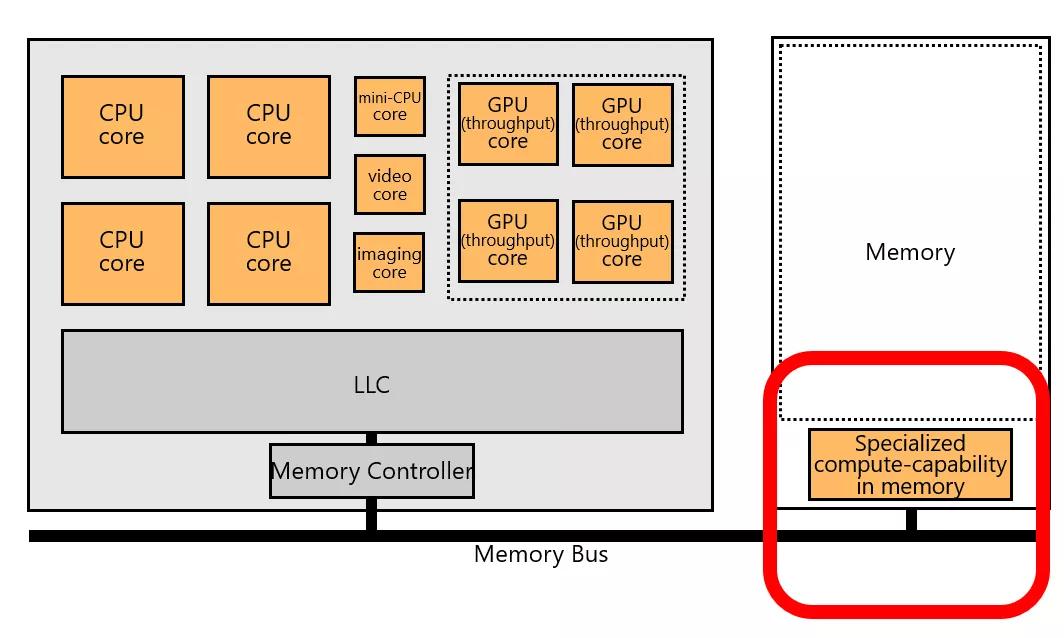
而实现Processing-In-Memory(PIM)还需要很多工作,一方面是微处理器架构,然后软硬件接口,然后到系统软件、编程语言,再到算法。
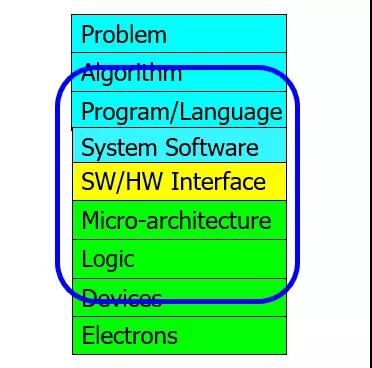
DreamBig才能有未来,至于同名的某个DPU公司,一上手就来QUIC优化,从体系结构来看很有可能又是一个和Marvel CN10K或者x豹类似的多核处理器厂家,因为他家在讲QUIC FastPath的时候还提到过嵌入式处理器。
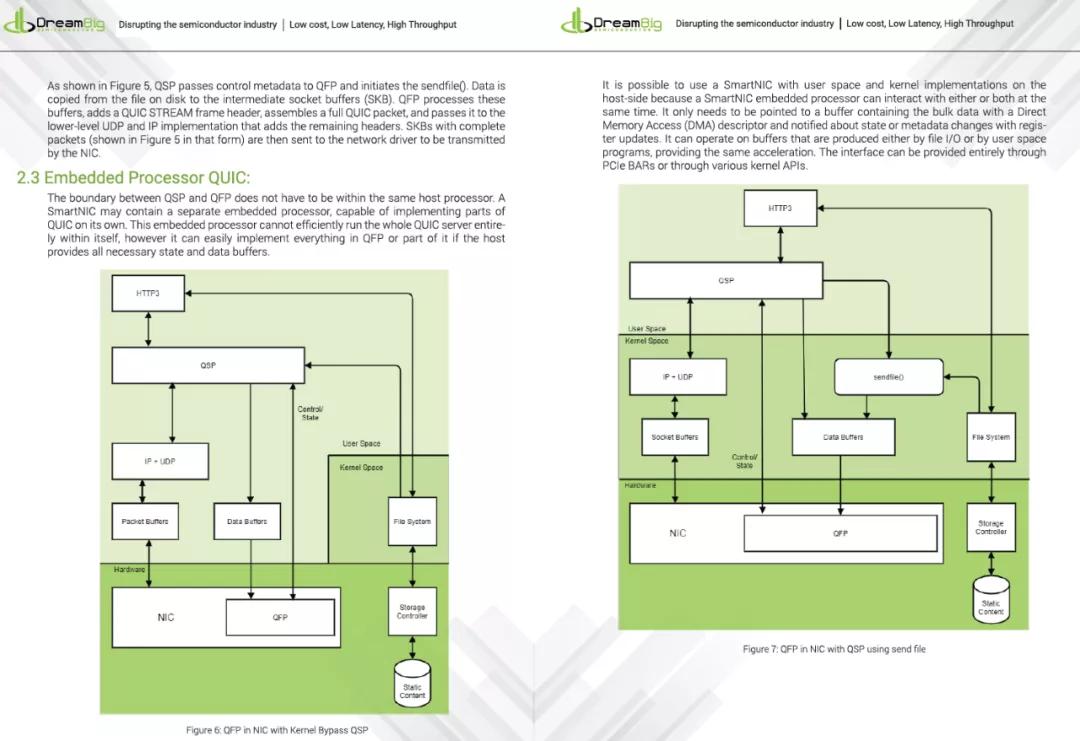
QUIC的Offload是一个非常有趣的话题,但是也可能非常难,因为协议编码的一些问题,利用QUIC的可靠传输和安全性配合SegmentRouting的可编程能力,这也是渣另一个项目Ruta的初衷。
《QUIC-SR:关于NewIP的答案》

云网质量保障计划
渣去年测完公有云的互通质量后:
《国内共有云互通测试》
《公有云互通测试报告(2)》
终于过了一年中国信息通信研究院联合中国通信标准化协会在京召开了2021混合云大会,会上启动了云网质量保障计划,可喜可贺~至于测量方法上,渣表示就不多评价了,留篇文章自己抄作业吧
《Internet 的性能测量》
《Ruta:不用花10个亿也能做千眼》
Reference
[1]3d-force-graph:
https://github.com/vasturiano/3d-force-graph
[2]3d-force-graph-vr:
https://github.com/vasturiano/3d-force-graph-vr,
[3]Compute-native networking:
https://conferences.sigcomm.org/events/apnet2021/records/25/4.Towards%20Compute-Native%20Networking.mp4
[4]Troubleshooting of ASR1K and ISR IOS-XE Made Easy:
https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2020/pdf/BRKARC-3147.pdf
[5]RMI MIPS XLR多核处理器培训.ppt:
https://download.csdn.net/download/zeroqi1706/1486860?utm_source=bbsseo