程序员的死对头就是各种 bug!最近微软在 NeurIPS 2021 上带来了一个好消息,研究人员设计了一个类似 GAN 的网络,通过选择器和检测器来互相写和改 bug,而且还不需要标注数据!
常言道,「一杯茶,一包烟,一个 bug 改一天」。
写代码是软件工程师们每天的工作,但当你辛辛苦苦写了一大堆代码,却发现无法运行的时候,内心一定是崩溃的。
找 bug 不仅费时费力,最关键的是还经常找不着,并且有时候改了一个 bug 又会引入更多 bug,子子孙孙无穷尽也。
简直就是找 bug 找到吐血。
随着 AI 技术的发展,各大公司开发的代码助手如 GitHub Copilot 等也能帮你少写一些有 bug 的代码。
但这还远远不够!
深度学习要是能帮我把代码里的 bug 也给修了,我上班只负责摸鱼,岂不是美滋滋!
微软在 NeurIPS 2021 上还真发了一篇这样的论文,其中提出了一个新的深度学习模型 BugLab,并通过自监督的学习方法,可以在不借助任何标注数据的情况下检测和修复代码中的 bug,堪称程序员的救世主!

修 bug 难在哪?
所谓的 bug,就是代码的实际运行和自己的预期不符。
该运行的没运行,该输出a,结果却输出个b,这种代码故意找茬的行为都属于 bug。
所以想要找到并修复代码中的 bug,不仅需要对代码的结构进行推理,还需要理解软件开发者在代码注释、变量名称等方面留下的模糊的自然语言提示。
例如一段程序的意图是,如果名字的长度超过了 22 个字符,那就只截取前 22 个。但原始代码中错误地把大于号写成了小于号,导致条件判断错误,程序运行结果和预期不符。
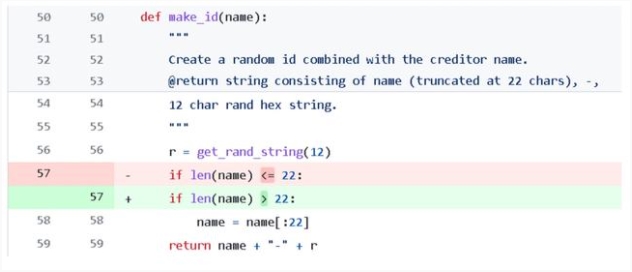
这种小错误在写代码的过程也是太常见了,稍不注意就会把条件弄反。
还有一种 bug 就是使用了错误的变量,例如下面的例子里面 write 和 read 弄错了,就会导致条件判断失败,这种 bug 的修复只有在理解了变量名的意义后才能修复,传统的修复手段对此是无能为力。
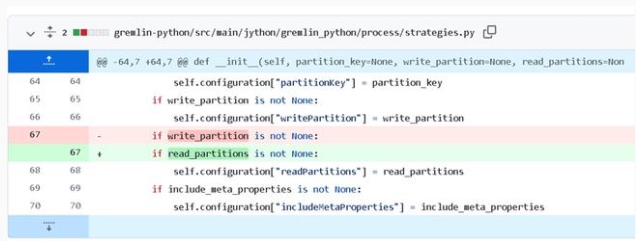
这种错误看起来很简单,但往往盯着看代码的时候却很难发现,属于一改改一天的那种。
并且每个程序员有自己的编程风格,比如不同的命名、缩进、判断以及重构的方式,想让代码来给自己找 bug,一个字,难!
对于微软来说,好在有 GitHub 代码库可以用来训练模型。但问题来了,GitHub 上带 bug 的代码有那么多吗?有 bug 谁还 commit 啊?就算能找到代码,也没人来标注数据啊!
微软提出的 BugLab 使用了两个相互竞争的模型,通过玩躲猫猫(hide and seek)游戏来学习,主要的灵感来源就是生成对抗网络(GAN)。
由于有大量的代码实际上都是没有 bug 的,所以需要设计一个 bug selector 来决定是否修改正确的代码来引入一个 bug,以及以何种方式引入 bug(例如把减号改为加号等)。当选择器确定了 bug 的类别后,就通过编辑源代码的方式引入 bug。
另一个用来对抗的是 bug detector,用来判断一段代码是否存在 bug,如果存在的话,它需要定位并修复这个 bug。
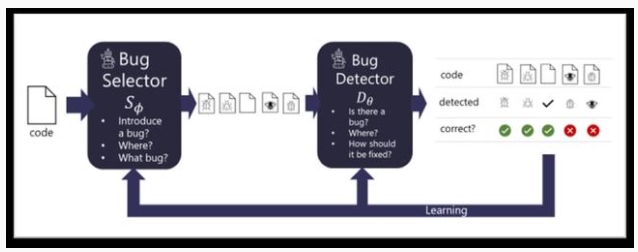
选择器和检测器都能够在没有标记数据的情况下共同训练,也就是说整个训练过程都是以自监督的方式进行,并成功在数百万个代码片段上训练。
selector 负责写 bug,并把它藏(hide)起来,而 detector 负责找 bug,并修复,整个过程就像躲猫猫一样。
随着训练的进行,selector 写 bug 越来越熟练,而 detector 也能够应对更复杂的 bug。
整个过程与 GAN 的训练大体相似,但目的却大不相同。GAN 的目的是获得一个更好的生成器来修改图片,但 BugLab 的目的是找到一个更好的检测器(GAN 中的判别器)。
并且整个训练也可以看作是一个 teacher-student 模型,选择器教会检测器如何定位并修复 bug。
为开源社区修 bug!
虽然从理论上来说,使用这种 hide and seek 的方式可以训练更复杂的 selector 来生成更多样的 bug,从而 detector 的修 bug 能力也会更强。
但以目前的 AI 发展水平来说,还无法教会 selector 写更难的 bug。
所以研究人员表示,我们需要集中精力关注那些更经常犯的错误,包括不正确的比较符,或者不正确的布尔运算符,错误的变量名引用等等其他一些简单的 bug。并且为了简单起见,实验中只针对 python 代码进行研究训练。
虽然这些解释听起来都像是借口。
为了衡量模型的性能,研究人员从 Python 包索引中手动注释了一个小型 bug 数据集,和其他替代方案(例如随机插入 bug 的 selector)相比,使用 hide and seek 方法训练的模型性能最多可以提高 30%
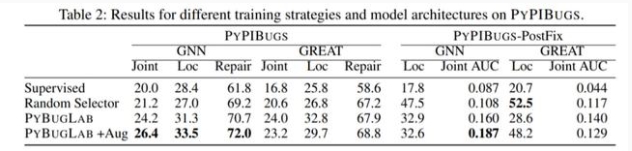
并且实验表明大约 26% 的 bug 都可以被发现并自动修复。在检测器发现的 bug 中,有 19 个在现实生活中的开源 GitHub 代码中都属于是未知的 bug。
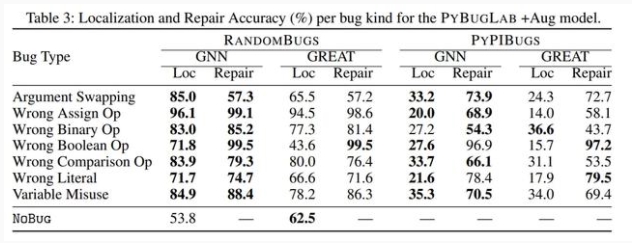
但模型也会对正确的代码报告存在 bug,所以这个模型在离实际部署上线还有一段距离。
如果更深入地研究 selector 和 detector 模型的话,就会引出那个老生常谈的问题:深度学习模型到底有没有,又怎么样去「理解」一段代码的作用?
过去的研究表明,将代码表示为一个 token 序列就能够产生次优的(suboptimal)效果。
但如果想要利用代码中的结构,例如语法、数据、控制流等等,就需要将代码中的语法节点、表达式、标识符、符号等等都表示为一个图上的节点,并用边来表示节点间的关系。
有了图以后就可以使用神经网络来训练 detector 和 selector 了。研究人员使用图神经网络(GNN)和 relational transformer 都进行了实验,结果发现 GNN 总体上优于 relational transformer。
如何让 AI 帮助人类来写代码和改 bug 一直都是人工智能研究中的一项基础任务,任务过程中 AI 模型需要理解人类对程序代码、变量名称和注释提供的上下文线索来理解代码的意图。
虽然 BugLab 离真正解放程序员改 bug 还很遥远,但距离我们消灭 bug 总算又向前走了一步!