












回顾先简单回顾一下 《Go工程化(九) 项目重构实践》 如果还没看过之前这篇文章可以先看一下:
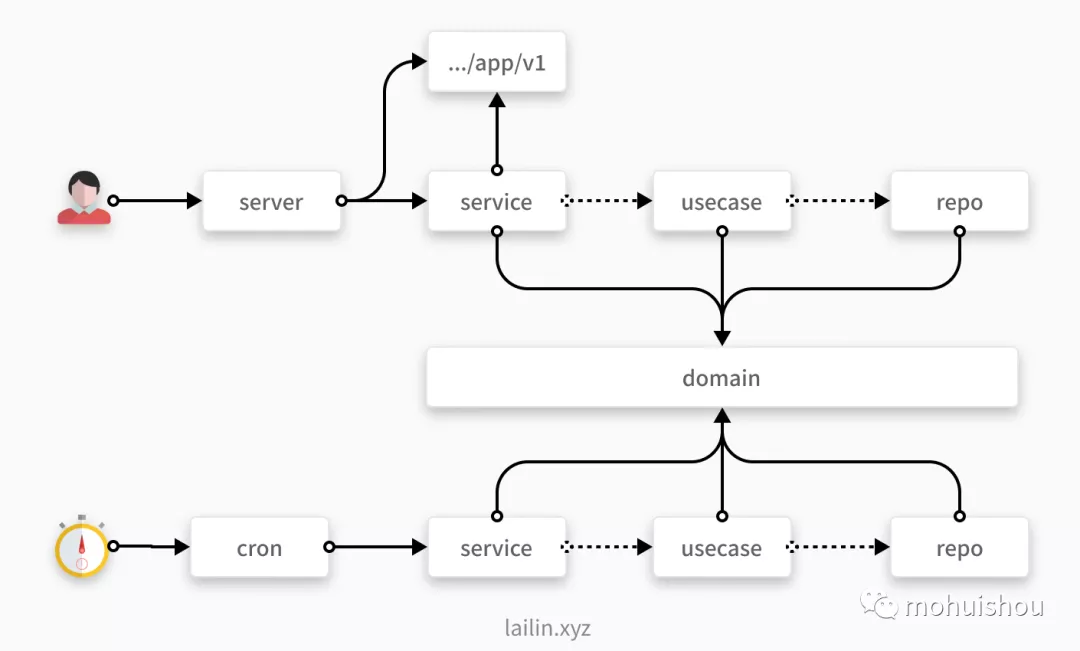
在我们之前的项目目录分层中,我们主要分为了五个块:
- cmd/appname 是我们服务的入口,只负责启动和依赖注入(使用 Wire)
- domain 或者 model 是我们的实体定义 + 接口定义
- server 负责实现我们在 proto 中定义的接口,在这一层中我们只做数据转换,不写业务逻辑
- usecase 负责实现我们的业务逻辑
- repo 负责数据操作, 仅做数据操作,不实现业务逻辑
在之前的文章中仅仅提到了一个非常简单的示例,但是我们实际业务流程往往没有那么简单,就一个非常常见的例子,我们现在需要创建一篇文章,文章上需要关联分类或者是标签信息,这里至少就分两步:
- 创建文章
- 关联文章和标签
这两个创建操作需要保证一致性,我们需要在数据库中使用事务,这时候我们的事务在哪里承载呢?
在 repo 层承载事务
其中最简单也最直接的办法就是在 repo 的 CreateArticle 方法中我们就使用事务去同时创建文章以及标签之间的关联关系。
- 我们不是所有的业务场景都需要关联创建,有的场景下我们只需要一个单纯的方法又怎么办呢?
- 这么写还有一个问题,我们把业务逻辑下沉到了 repo 中,后面我们还有其它关联也这么搞么?
针对第一个问题,最简单的办法就是我们提供一个 CreateArticleWithTags 方法表示同时创建这两者,如果我们需要一个独立的 CreateArticle 再写一个就好了。
但是随着需求越来越多,可能后面还有需要和角色关联的,和商品关联的等等。
难道我们就一种逻辑写一个方法么。想想就可怕。
还是在参数中加上很多可选的 options,然后在一个方法中不断判断。那我们还拿 usecase 做什么直接写一起不更好么?
在 usecase 层承载事务
ok,所以直接在 repo 层里面来实现看上去好像行不通,那我们就把视线往上移动,我们在 usecase 来解决这个问题。
事务的能力是在 repo 上提供的,所以我们需要在 repo 层提供一个事务接口,然后在 usecase 中进行调用,保证是事务执行的就行。
使用 repo 层提供的事务接口
- // domain/article.go
- // ArticleRepoTxFunc 事务方法
- type ArticleRepoTxFunc = func(ctx context.Context, repo IArticleRepo) error
- // IArticleRepo IArticleRepo
- type IArticleRepo interface {
- Tx(ctx context.Context, f ArticleRepoTxFunc) error
- GetArticle(ctx context.Context, id int) (*Article, error)
- CreateArticle(ctx context.Context, article *Article) error
- }
在 repo 中,我们可以像上面这样定义,提供一个 Tx 方法,这个方法接受一个 ArticleRepoTxFunc 作为参数,这个函数中的 repo 是开启了事务的 repo,通过这个 repo 调用的所有方法都是在事务中执行的。
- // repo/article.go
- func (r *article) Tx(ctx context.Context, f domain.ArticleRepoTxFunc) error {
- // 注意,这里的 r.db 是 *gorm.DB
- // 在 gorm 中提供了 Transaction 的工具方法用于执行事务,这里我们就不自己写了
- return r.db.WithContext(ctx).Transaction(func(tx *gorm.DB) error {
- // 我们使用事务的 tx 重新初始化一个 repo
- // 这个 repo 后续的执行的数据库相关的操作就都是事务的了
- repo := NewArticleRepo(tx)
- return f(ctx, repo)
- })
- }
然后我们在 usecase 调用的时候就可以这样。
- // usecase/article.go
- func (u *article) CreateArticle(ctx context.Context, article *domain.Article, tagIDs []uint) error {
- return u.repo.Tx(ctx, func(ctx context.Context, repo domain.IArticleRepo) error {
- err := repo.CreateArticle(ctx, article)
- if err != nil {
- return err
- }
- var ats []*domain.ArticleTag
- for _, tid := range tagIDs {
- ats = append(ats, &domain.ArticleTag{
- ArticleID: article.ID,
- TagID: tid,
- })
- }
- return repo.CreateArticleTags(ctx, ats)
- })
- }
这样写起来就整洁很多了,业务逻辑和我们最初的设计一样,在 usecase 中实现了,repo 中我们也保持了简单的原则。
这样是不是就万事大吉了呢?如果万事大吉了这篇文章到这儿也就应该结束了,但是还没有,说明我在实践的过程中还碰到了问题。
问题很简单,就是我们在 usecase 中不仅仅需要复用 repo 中的代码,还有可能需要复用 usecase 中的代码,不然我们就可能在 usecase 中出现很多相同的逻辑代码片段,代码的重复率就很高。
我们来看下面一个例子会不会发现有点什么不对。
- // usecase/article.go
- func (u *article) A(ctx contect, args args) error {
- err := u.CreateArticle(ctx, args.Article) // 包含事务
- if err != nil {
- return err
- }
- return u.UpdateXXX(ctx, args.XXX) // 这个方法中也使用了事务
- }
这个方法内其实是开启了两个事务,这两个事务之间互不相关,不符合我们需求。
在 usecase 层提供事务方法
- // usecase/article.go
- type handler func(ctx context.Context, usecase domain.IArticleUsecase) error
- func (u *article) tx(ctx context.Context, f handler) error {
- return u.repo.Tx(ctx, func(ctx context.Context, repo domain.IArticleRepo) error {
- usecase := NewArticleUsecase(repo)
- return f(ctx, usecase)
- })
- }
我们在 usecase 中也创建了一个 tx 方法,和 repo 类似,在调用 tx 之后,handler 中的方法的需要都是用新的参数 usecase 这个新的 usecase 可以保证里面的 repo 调用都是事务的。
所以我们之前的 A 函数可以修改为这样:
- // usecase/article.go
- func (u *article) A(ctx contect, args args) error {
- return u.tx(ctx, func(ctx context.Context, usecase domain.IArticleUsecase) error {
- err := usecase.CreateArticle(ctx, args.Article) // 包含事务
- if err != nil {
- return err
- }
- return usecase.UpdateXXX(ctx, args.XXX) // 这个方法中也使用了事务
- })
- }
这样就没有问题了么?我们 UpdateXXX 方法中也调用 u.tx 方法,这样就会导致反复开启事务,虽然在 gorm 的 Transaction 方法是支持嵌套事务的,但是我们还是不要滥用这个特性。
解决办法很简单,我们只需要在执行的时候判断下就行了。
- // usecase/article.go
- type article struct {
- repo domain.IArticleRepo
- isTx bool // 用于标识是否开启了事务
- }
然后我们在 tx 方法内:
- func (u *article) tx(ctx context.Context, f handler) error {
- // 如果已经开启过事务了我们就直接复用就行了
- if u.isTx {
- return f(ctx, u)
- }
- return u.repo.Tx(ctx, func(ctx context.Context, repo domain.IArticleRepo) error {
- usecase := &article{
- repo: repo,
- isTx: true,
- }
- return f(ctx, usecase)
- })
- }
总结
文章到这里就到尾声了,同样的问题,我们现在这么写就可以了么?
对于我当前所遇到的一些需求来说已经可以解决了,当然这个方案并不完美,比如说我们涉及到多个 repo 的时候,当前的方法就没法直接用了,还得进行一些改造,虽然我们要有远见但是也不要想的太多,进化是优于完美的。




















