













人工智能的准备过程大部分是组织变革。人工智能的运用可能需要创造一个新的劳动力类别:新领工人(New-collar Worker)。新领工作可以涵盖网络安全、云计算、数字设计和认知商业(Cognitive Business)等工作。
在世界范围内,大多数组织都认同人工智能可以帮助其保持竞争力,但是许多组织通常仍使用不算先进的分析形式。对于那些使用人工智能经历失败或者未能达到最佳效果的组织而言,自然的方法似乎是消除而非增加严谨性。
从人工智能阶梯的角度来看,梯级会匆忙掠过,甚至完全跳过。当组织开始意识到并认可这种范式的时候,他们必须重新审视分析的基础,以便为其达到理想的未来状态和获得从人工智能获益的能力做好准备。他们不一定要从零开始,但他们需要评估自己的能力,以确定可以从哪个梯级开始。他们需要的许多技术部件可能已经到位。
01 重点技术领域
如图1-1所示,组织可访问的分析复杂程度随着梯级而增加。这种复杂性可以带来蓬勃发展的数据管理实践,这得益于机器学习和人工智能的发展。
在某些时候,拥有海量数据的组织将需要探索多云部署(Multicloud Deployment)。在攀登人工智能阶梯的时候,他们需要考虑以下三个基于技术的领域:
- 以机器学习为核心的混合数据管理。
- 在安全的用户配置文件中提供安全性和无缝用户访问的治理和集成。
- 同时为高级分析和传统分析提供自助服务和全服务用户环境的数据科学和人工智能。
这些基础技术必须包含现代云计算和微服务基础设施,以便为组织创造敏捷而快速地前进和向上发展的途径。这些技术必须在各梯级上实现,从而使数据移动成为可能,并从单一环境到多云环境的各类部署的机器学习模型中获得预测能力。
02 一步一个脚印地攀登阶梯
如图1-1所示,人工智能阶梯的梯级分别标记为“收集”“组织”“分析”和“注入”。每个梯级都提供了信息架构所需的要素。
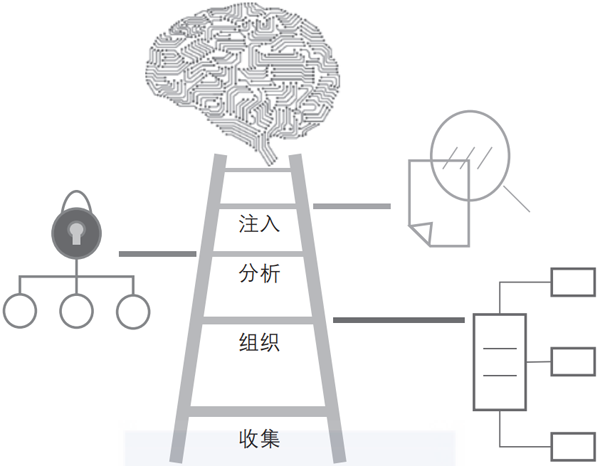
▲图1-1 实现完整数据和分析的人工智能阶梯
第一梯级收集,代表了用于建立基础数据技能的一系列规程。理想情况下,无论数据的形式和驻留位置如何,都应简化数据的访问,并使其具有可用性。
由于用于高级分析和人工智能的数据是动态的且具有流动性,因此并非所有数据都可以在物理数据中心进行管理。随着数据源数量的不断增加,虚拟化数据的收集方式是信息架构中需要考虑的关键活动之一。
以下是收集梯级中包含的关键主题:
- 使用通用SQL引擎收集数据,使用API进行NoSQL访问,以及支持广泛的数据生态系统(数据产业)中的数据虚拟化。
- 部署始终保持弹性和可扩展性的数据仓库、数据湖和其他基于分析的存储库。
- 同时兼顾实时数据摄入和高级分析。
- 存储或提取结构化、半结构化、非结构化等所有类型的业务数据。
- 使用可能包含图形数据库、Python、机器学习SQL和基于置信度查询的人工智能优化集合。
- 挖掘可能包含MongoDB、Cloudera、PostgreSQL、Cloudant或者Parquet等技术的开源数据存储。
组织梯级意味着需要创建一个可信数据基础。可信数据基础必须至少对组织可知内容进行归类。所有形式的分析都高度依赖数字化资产。数字化资产构成了组织可以合理了解的基础:业务语料库是组织论域的基础,即通过数字化资产可获知的信息总量。
拥有可用于分析的业务就绪的数据是用于人工智能的业务就绪的数据的基础,但是仅仅具有访问数据的权限并不意味着该数据已为人工智能用例做好了准备。不良数据可能导致人工智能瘫痪,并误导使用人工智能模型输出结果的任何进程。
为了进行组织,组织必须制定规程来集成、清洗、策管、保护、编目和管理其数据的整个生命周期。
以下是组织梯级的关键主题:
- 清洗、集成、编目不同来源的所有类型数据。
- 支持并提供自助服务分析的自动化虚拟数据管道。
- 即使在跨越多云的情况下,也能确保数据治理和数据沿袭。
- 部署可提供个性化服务的基于角色体验的自助服务数据湖。
- 通过从多个云数据存储库中梳理业务就绪视角,获得360度全方位视角。
- 简化数据隐私、数据策略和合规性控制。
分析梯级包含了基本的业务和计划分析能力,这些能力是人工智能持续取得成功的关键。分析梯级进一步将构建、部署和管理人工智能模型所需能力封装在一个集成组织技术的产品组合之中。
以下是分析梯级的关键主题:
- 准备用于人工智能模型的数据,在统一体验中构建、运行和管理人工智能模型。
- 通过自动生成人工智能来构建人工智能模型,从而降低所需技能水平。
- 应用预测性、规范性和统计性分析。
- 允许用户选择自己的开源框架来开发人工智能模型。
- 基于准确性分析和质量控制不断地演进模型。
- 检查偏差,确保线性决策解释并坚持合规性。
注入是一门涉及将人工智能集成到有意义的业务功能之中的规程。尽管许多组织能够创建有用的人工智能模型,但它们很快会被迫应对实现持续的、可行的业务价值的运营挑战。
人工智能阶梯中的“注入”梯级突出了在模型推荐的决策中获得信任和透明度、解释决策、避免偏见或确保公平的检测,以及提供审计所需的足量数据线索所须掌握的规程。注入梯级旨在通过解决时间–价值连续统来实现人工智能用例的可操作性。
以下是注入梯级的关键主题:
- 通过预构建适用于诸如客户服务和财务规划等常见用例的人工智能应用程序,或定制适用于物流运输等专门用例的人工智能应用程序,缩短实现价值的时间。
- 优化知识工作和业务流程。
- 利用人工智能辅助的商业智能和数据可视化。
- 自动化规划、预算和预测分析。
- 使用符合行业需求的人工智能驱动框架进行定制。
- 通过使用人工智能支持新业务模型的创新。
一旦对每个梯级的掌握达到一定程度,即新的尝试是重复以往的模式,而且这些新尝试不被视为是定制或需要巨大努力的,组织就可以认真地朝着未来状态采取行动。
人工智能阶梯的顶端是不断实现现代化:从本质上根据其意愿重塑自己。现代化梯级只不过是已达到的未来状态。但是一旦达到,此状态便成为组织的当前状态。达到阶梯的顶端后,充满活力的组织将开始新的阶梯攀登。这个循环如图1-2和图1-3所示。
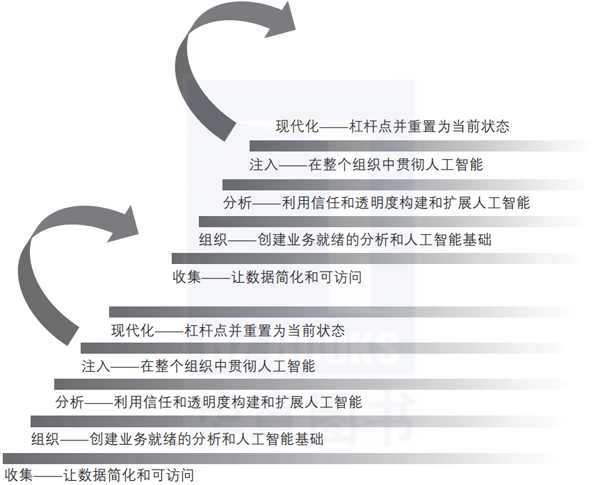
▲图1-2 人工智能阶梯是不断改进和适应的重复攀登的一部分

▲图1-3 当前状态←未来状态←当前状态
以下是现代化梯级的关键主题:
- 为人工智能部署多云信息架构。
- 在任何私有或公有云中利用统一的选择平台。
- 将数据虚拟化作为收集任意来源数据的手段。
- 使用DataOps和MLOps为自助服务建立可信任的虚拟数据管道。
- 使用开放且易于扩展的统一数据和人工智能云服务。
- 动态和实时扩展以适应不断变化的需求。
现代化是指升级或更新的能力,或者更具体地说,包括利用重新构想的业务模式的变革性想法或创新所产生的新业务能力或产品。正在实现现代化的组织的基础设施可能包括采用多云拓扑的弹性环境。鉴于人工智能的动态本质,组织的现代化意味着构建灵活的信息架构,以不断展示相关性。
- 大蓝图
在敏捷开发中,史诗(Epic)用于描述一个被认为因过于庞大而无法在单个迭代或单个冲刺(Sprint)中解决的用户故事。因此,史诗被用来提供大蓝图。这个蓝图为需要完成的工作提供了一个端到端的视角。然后,史诗可以被分解为被处理的可行故事。史诗的作用是确保故事被适当地编排。
在人工智能阶梯中,阶梯就代表“大蓝图”,分解由梯级表示。这个阶梯用于确保每个梯级的概念(收集、组织、分析、注入)都被正确地线程化,以确保获取成功和实现价值的最佳机会。






















