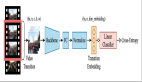
近年来,深度学习在一系列任务中(例如:图像识别、目标识别、语义分割、视频识别等)取得了巨大成功。因此,基于深度学习的智能模型正逐渐广泛地应用于安防监控、无人驾驶等行业中。但最近的研究表明,深度学习本身非常脆弱,容易受到来自对抗样本的攻击。对抗样本指的是由在干净样本上增加对抗扰动而生成可以使模型发生错误分类的样本。对抗样本的存在为深度学习的应用发展带来严重威胁,尤其是最近发现的对抗样本在不同模型间的可迁移性,使得针对智能模型的黑盒攻击成为可能。具体地,攻击者利用可完全访问的模型(又称白盒模型)生成对抗样本,来攻击可能部署于线上的只能获取模型输出结果的模型(又称黑盒模型)。此外,目前的相关研究主要集中在图像模型中,而对于视频模型的研究较少。因此,亟需开展针对视频模型中对抗样本迁移性的研究,以促进视频模型的安全发展。
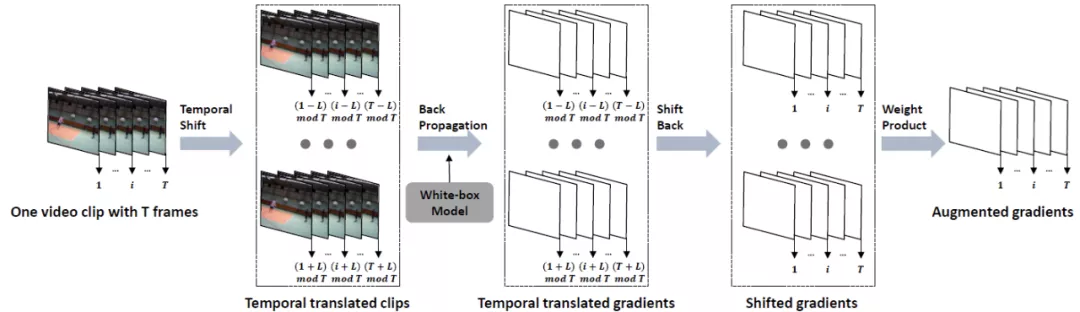
时序平移攻击方法
与图片数据相比,视频数据具有额外的时序信息,该类信息能够描述视频中的动态变化。目前已有多种不同的模型结构(例如:Non-local,SlowFast,TPN)被提出,以捕获丰富的时序信息。然而多样化的模型结构可能会导致不同模型对于同一视频输入的高响应区域不同,也会导致在攻击过程中所生成的对抗样本针对白盒模型产生过拟合而难以迁移攻击其他模型。为了进一步剖析上述观点,来自复旦大学姜育刚团队的研究人员首先针对多个常用视频识别模型(video recognition model)的时序判别模式间的相似性展开研究,发现不同结构的视频识别模型往往具有不同的时序判别模式。基于此,研究人员提出了基于时序平移的高迁移性视频对抗样本生成方法。

- 论文链接:https://arxiv.org/pdf/2110.09075.pdf
- 代码链接:https://github.com/zhipeng-wei/TT
视频模型的时序判别模式分析
在图像模型中,常常利用 CAM(Class activation mapping)来可视化模型对于某张图片的判别区域。然而在视频模型的判别模式由于额外的时序维度而难以可视化,且难以在不同模型间进行比较。为此,研究人员定义视频帧的重要性排序作为视频模型的时序判别模式。如果两个模型共享相似的时序判别模式,那么视频帧重要性的分布会更加相似。
视频帧的重要性计算
研究人员使用了三种途径衡量视频帧对于模型决策的重要性:Grad-CAM,Zero-padding 和 Mean-padding。Grad-CAM 在由 CAM 计算得到的 attention map 中针对每一帧进行均值计算,该均值则为视频各帧的重要性度量。而 Zero-padding 使用 0 来替换第i视频帧中的所有像素值,并计算替换前后的损失值的变化程度。变化程度越高说明第 i 视频帧越重要。类似地,Mean-padding 使用临近帧的均值替换第i视频帧。通过以上三种方式,可计算得到在不同模型下视频帧的重要性程度,并以此作为模型的时序判别模式。
时序判别模式相似度计算
由上述方法计算视频数据x在模型A上的视频帧重要性得分为
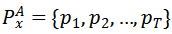
,其中T表示输入视频帧的数目。那么针对模型A和模型B,可得到
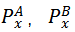
,结合 Spearman’s Rank Correlation,可计算模型间时序判别模式的相似性
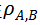
,即
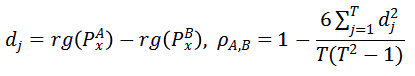
其中,
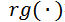
执行基于重要性值的排序操作并返回视频各帧的排序值。
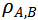
的值在-1和1之间,当其等于0时表示模型A和模型B间的判别模式不存在关系,而-1或者1则表示明确的单调关系。
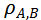
的值越大则模型间的判别模式越相似。基于此,可实现不同视频模型时序判别模式间关系的度量。

不同视频模型间判别模式的相似程度
上图为 6 个视频模型间的判别模式关系热图。在不同模型设计架构下,Non-Local、SlowFast 和 TPN 间的时序判别模式相似程度较低;而在相同设计架构下,分别使用 3D Resnet-50 和 3D Resnet-101 作为 backbone 的视频模型具有更加相似的时序判别模式。以上趋势在三种视频帧重要性计算方法中都得到了验证。由此,可在实验上证明该论文的假设,即不同视频模型结构会导致不同的时序判别模式。
时序平移攻击方法
基于以上观察,研究人员提出了基于时序平移的迁移攻击方法。通过沿着时序维度移动视频帧,来降低所生成对抗样本与白盒模型特定判别模型之间的拟合程度,提高对抗样本在黑盒模型上的攻击成功率。
使用
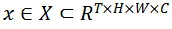
表示输入视频,
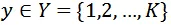
表示其对应真实标签,其中T,H,W,C分别表示帧数,高度,宽度和通道数,K表示类别数目。使用
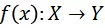
表示视频模型对于视频输入的预测结果。定义
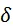
为对抗噪声,那么攻击目标可以定义为
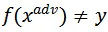
,其中
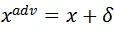
,且限制
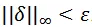
。定义
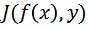
为损失函数。则非目标攻击的目标函数可定义为:
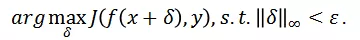
为了降低攻击过程中对于白盒模型的过拟合现象,研究人员对时序移动后视频输入的梯度信息进行聚合:
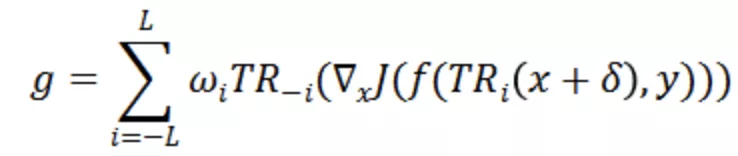
其中L表示最大平移长度,且
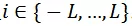
。函数
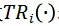
表示将所有的视频输入沿着时序维度平移i帧。当平移后的位置大于T时,设当前帧为第i帧,即t+i>T,则第t帧的位置变为第t+i-T帧,否则为第t+i帧。而在时序平移后的视频输入上计算完梯度后,仍会沿着时序维度平移回原始视频帧序列,并通过w_i来整合来自不同平移长度的梯度信息。w_i可利用均一、线性、高斯三种方式生成(参考 Translation-invariant 攻击方法)。
攻击算法整体流程如下,其中
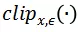
用来限制生成的对抗噪声满足
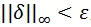
。

结果讨论与分析
为了探究时序平移攻击方法的性能,研究人员在 UCF-101 和 Kinetics-400 两个数据集,Non-local,SlowFast,TPN 三种不同结构的视频模型中进行对比实验,其中视频模型分别使用 3D Resnet-50 和 3D Resnet-101 作为 backbone。当使用某一种结构的视频模型作为白盒模型时,计算所生成对抗样本在其他结构的视频模型上的攻击成功率(Attack success rate,ASR),以此作为评价指标。
研究人员分别在单步攻击和迭代攻击方法下进行了实验对比。可以看出时序平移攻击方法在单步攻击和迭代攻击下都能取得更高的 ASR,表明所生成的对抗样本具有高迁移性。此外,在视频模型上,单步攻击的效果好于迭代攻击。这说明,在图像模型中发展出的迁移攻击方法不适用于更复杂的视频模型。最后,当使用 TPN 模型作为白盒模型时,时序平移攻击方法的性能提升较为有限,研究人员通过分析后认为 TPN 模型对于时序移动更加不敏感。
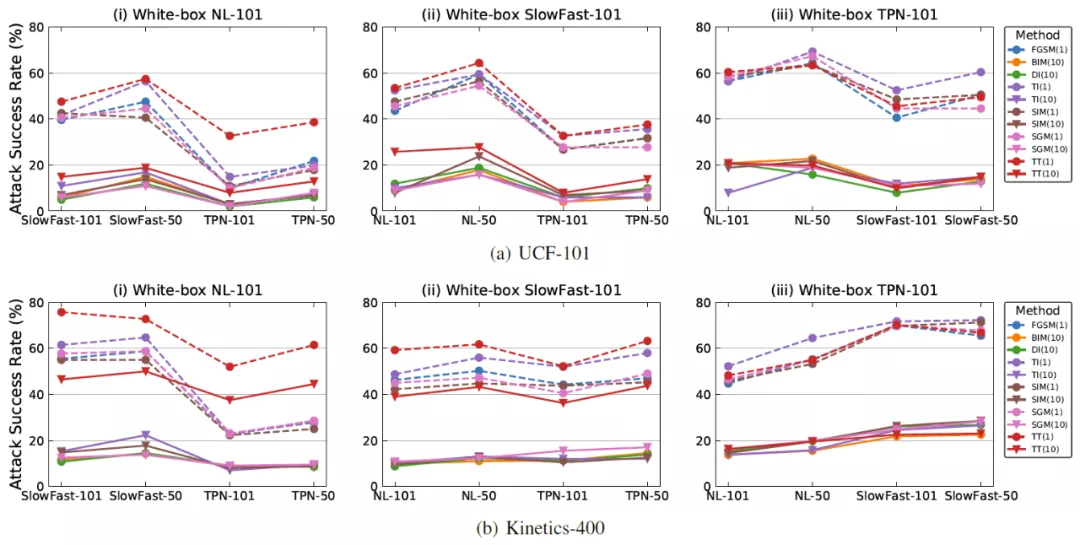
视频识别模型上的 ASR 对比图
下表展示了与 Translation-invariant(TI)攻击方法、Attention-guided(ATA)攻击方法和 Momentum iterative(MI)攻击方法相结合后的性能比较。可以看出,时序平移方法可以辅助这些方法发挥更好的性能,起到补充的作用。
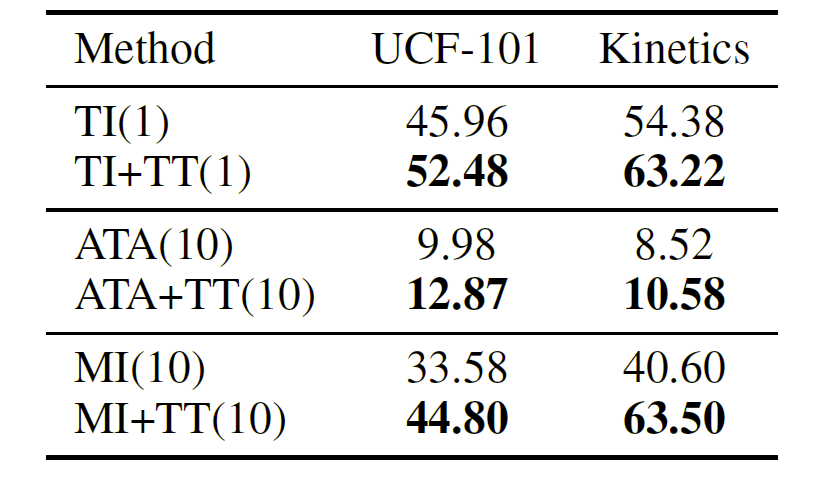
结合现有方法的平均 ASR 结果对比
此外,研究人员还针对不同的平移长度L、权重w_i生成策略及平移策略进行了消融实验。
平移长度L决定了有多少个平移后的视频输入被用来进行特征聚合。当L=0时,时序平移方法将会退化为最基本的迭代攻击方法。因此,针对平移长度的研究是十分有必要的。下图展示了不同平移长度下时序平移攻击方法在不同黑盒模型下的 ASR 变化情况。可以看到,Non-local Resnet-50 模型的曲线更加稳定,而其他黑盒模型的曲线呈现先上升再趋于稳定的特点。这是因为 Non-local Resnet-50 与 Non-local Resnet-101 共享相似的模型结构。为了平衡 ASR 和计算复杂度,研究人员最终选取L=7来进行实验。
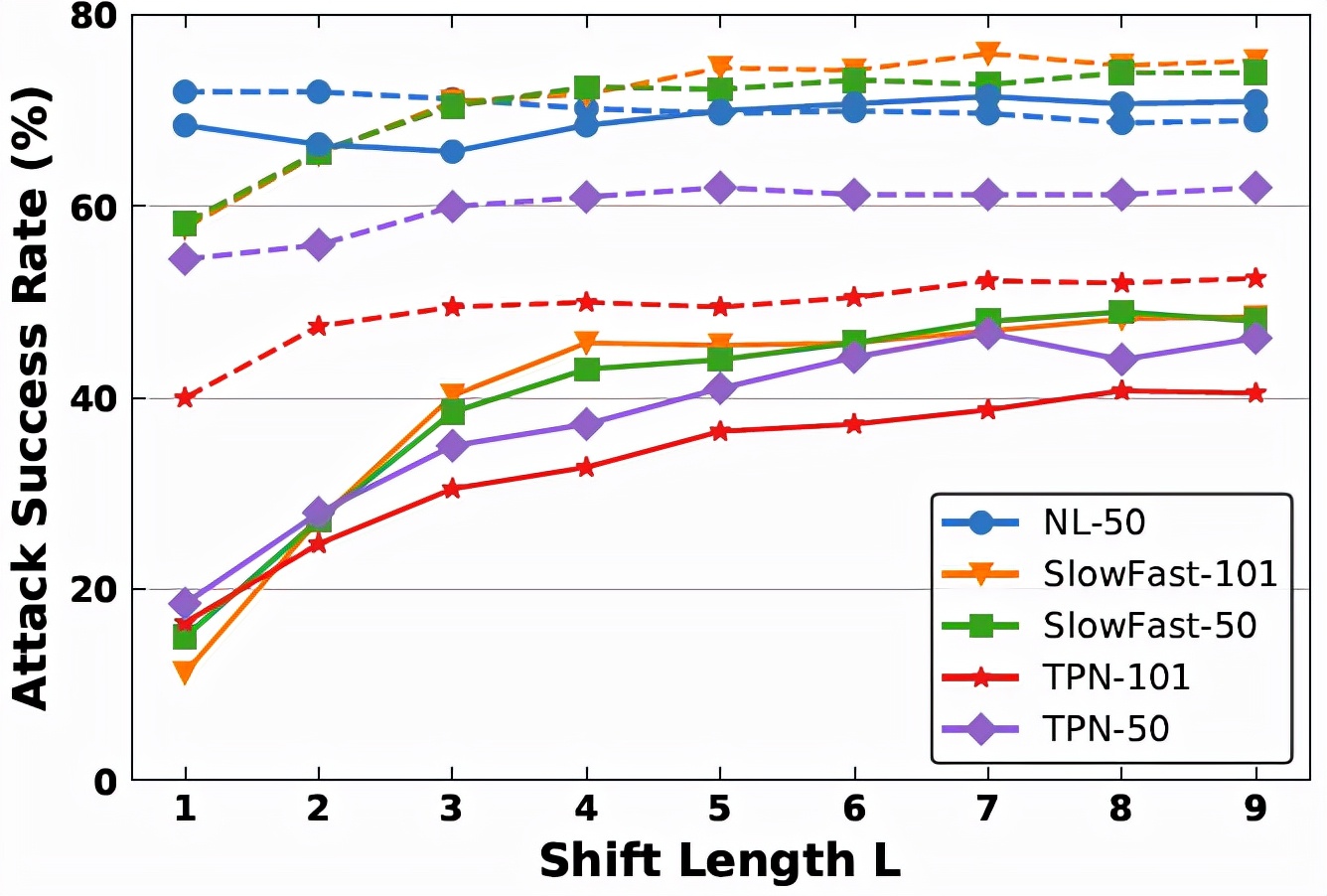
不同平移长度下的时序平移攻击方法性能对比
下表展示的是对于权重生成策略和平移策略的消融实验结果。从表中可以看出,当赋予具有更大时序平移长度的视频输入以更小的权重时,时序平移攻击方法能取得较好的结果。此外,当平移策略变为随机帧交换或远距离交换时,时序平移攻击方法会取得较差的结果。
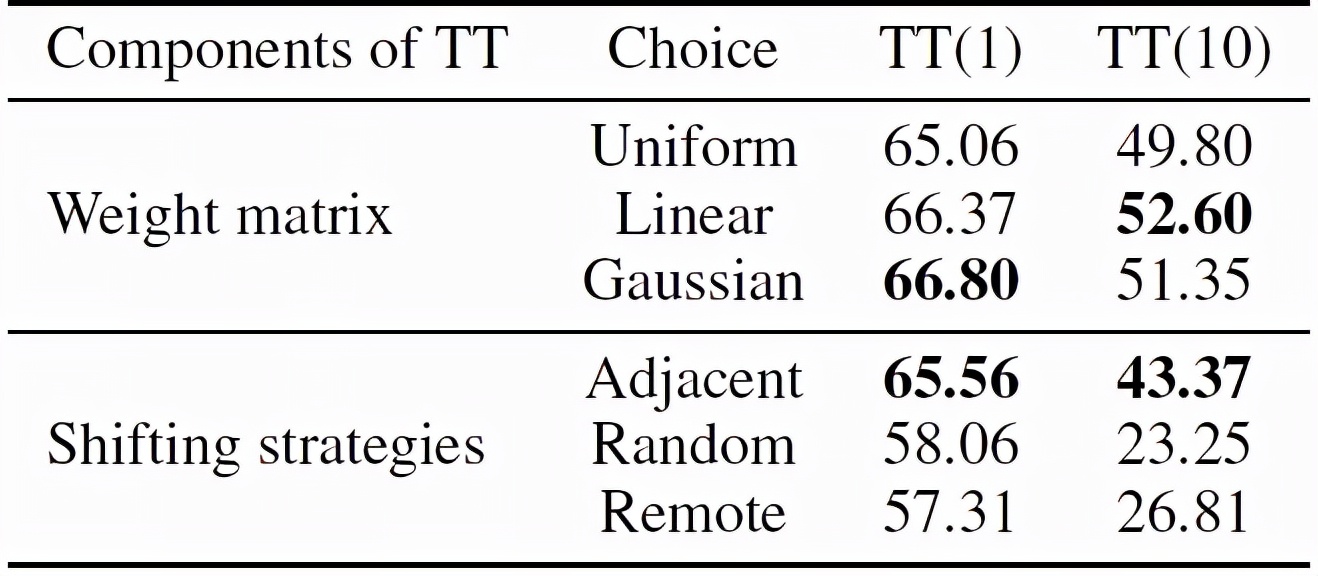
不同权重生成策略和平移策略下时序平移攻击方法的性能对比