












文本人脸合成指的是基于一个或多个文本描述,生成真实自然的人脸图像,并尽可能保证生成的图像符合对应文本描述,可以用于人机交互,艺术图像生成,以及根据受害者描述生成犯罪嫌疑人画像等。针对这个问题,中科院自动化所联合北方电子设备研究所提出了一种基于多输入的文本人脸合成方法(SEA-T2F),并建立了第一个手工标注的大规模人脸文本描述数据集(CelebAText-HQ)。该方法首次实现多个文本输入的人脸合成,与单输入的算法相比生成的图像更加接近真实人脸。相关成果论文《Multi-caption Text-to-Face Synthesis: Dataset and Algorithm》已被ACM MM 2021录用。

- 论文地址:https://zhaoj9014.github.io/pub/MM21.pdf
- 数据集和代码已开源:https://github.com/cripac-sjx/SEA-T2F

图1 不同方法的文本到人脸图像生成结果
相较于文本到自然图像的生成,文本到人脸生成是一个更具挑战性的任务,一方面,人脸具有更加细密的纹理和模糊的特征,难以建立人脸图像与自然语言的映射,另一方面,相关数据集要么是规模太小,要么直接基于属性标签用网络生成,目前为止,还没有大规模手工标注的人脸文本描述数据集,极大地限制了该领域的发展。此外,目前基于文本的人脸生成方法[1,2,3,4]都是基于一个文本输入,但一个文本不足以描述复杂的人脸特征,更重要的是,由于文本描述的主观性,不同人对于同一张图片的描述可能会相互冲突,因此基于多个文本描述的人脸生成具有很重大的研究意义。
针对该问题,团队提出了一个基于多输入的文本人脸生成算法。算法采用三阶段的生成对抗网络框架,以随机采样的高斯噪声作为输入,来自不同文本的句子特征通过SFIM模块嵌入到网络当中,在网络的第二第三阶段分别引入了AMC模块,将不同文本描述的单词特征与中间图像特征通过注意力机制进行融合,以生成更加细密度的特征。为了更好地在文本中学习属性信息,团队设计了一个属性分类器,并引入属性分类损失来优化网络参数。
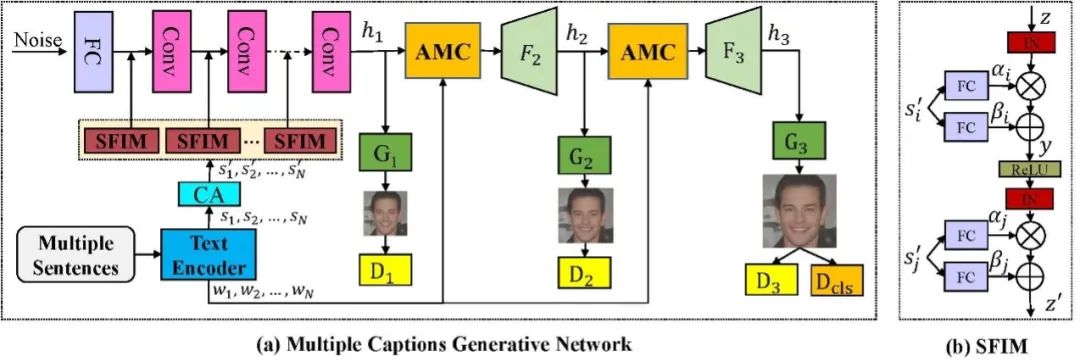
图2 模型框架示意图
此外,团队首次建立了一个大规模手工标注数据集,首先在CelebAMask-HQ数据集中筛选了15010张图片,每个图片分别由十个工作人员手工标注十个文本描述,十个描述按照由粗到细的顺序分别描述人脸的不同部位。
实验结果
团队对提出的方法进行了定性和定量分析[5,6],实验结果表明,该方法不仅能生成高质量的图像,并且更加符合文本描述。

图3 不同方法比较结果

图4 不同数量输入的生成结果
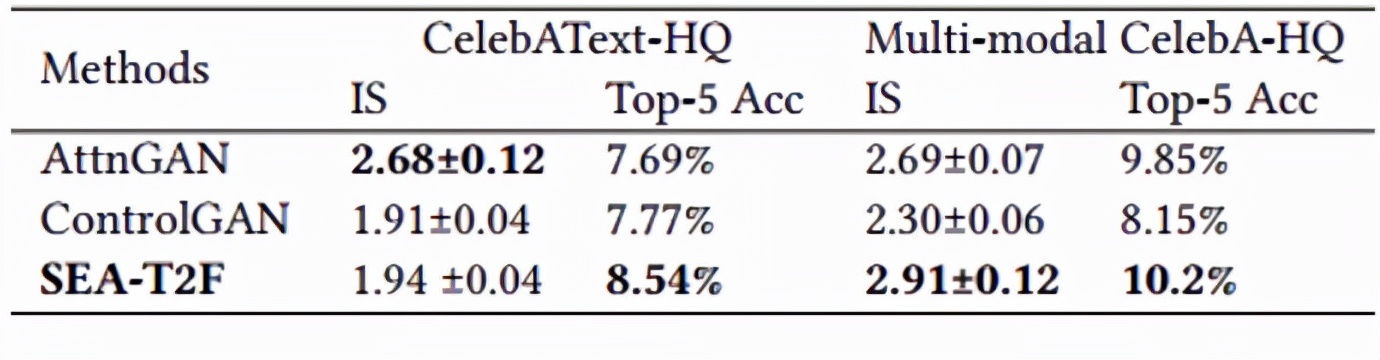
表1 不同方法的定量比较结果
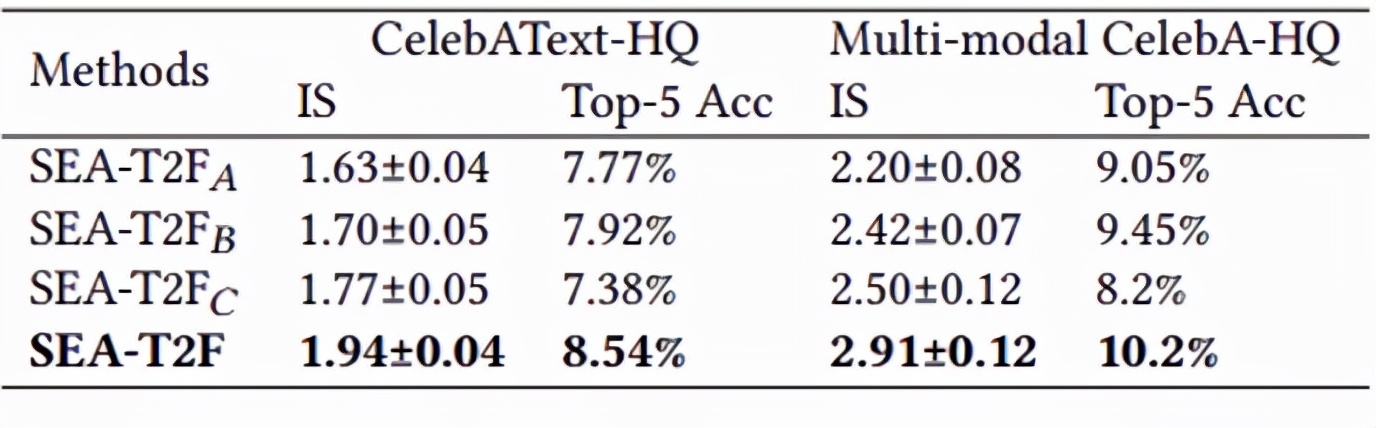
表2 消融实验结果:前三行分别表示网络去除SFIM,AMC,和属性分类损失。






















