先给不了解内核态、用户态的简单介绍一下,我们在什么时候会提到这两个概念。
例如我们的应用程序需要从磁盘读取某个文件的数据,此时并不是直接从磁盘加载到应用内存中,而是:
- 先将数据从「磁盘」复制到「内核 Buffer」
- 再将数据从「内核 Buffer」复制到「用户 Buffer」
以上就是用户态和内核态的概念。首先我们给他下个定义,这两个态是操作系统的运行级别。
然后我们知道,我们写的程序,最终运行的时候实际都会被编译、解释成一条一条的 CPU 指令被 CPU 执行。
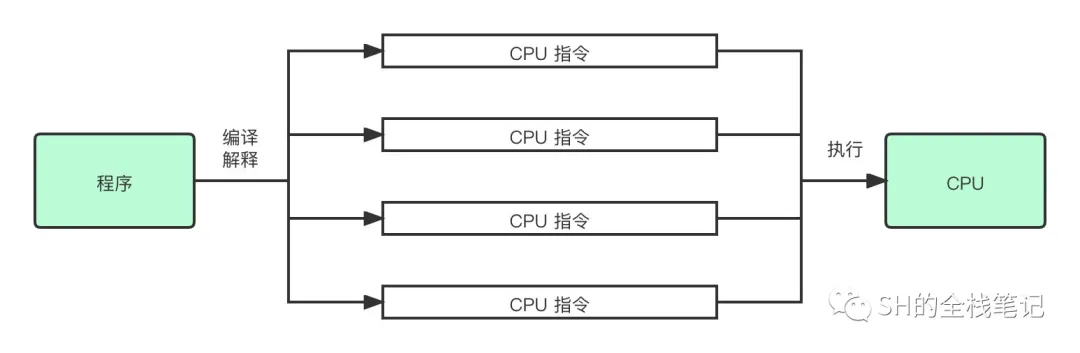
解释成一条一条的指令
用户态、内核态的指令都是 CPU 都在执行,所以我们可以换个说法,实际上这个态代表的是当前 CPU 的状态。那既然这些指令最终都由 CPU 执行,那对其区分的理由是什么呢?
那是因为,CPU 指令根据其重要的程度,也分为不同的权限。有一些指令执行失败了无关痛痒,而有一些指令失败了会导致整个操作系统崩溃,甚至需要重启系统。如果将这些指令随意开放给应用程序的话,整个系统崩溃的概率将会大大的增加。
再举个类似的例子。我们设计一个类,里面有几个很重要的变量,你大概率是不会把它们声明成 public 的吧?应该声明成 private,并开发几个专门修改他们的方法,对传入的值进行一系列的校验之后再去设置。
上面说到,CPU 指令是做了权限划分的, 例如 Intel X86 中将 CPU 指令权限划分为了 4 个等级:
权限分类
它们之间的权限的高低程度可以通过这张图来识别:
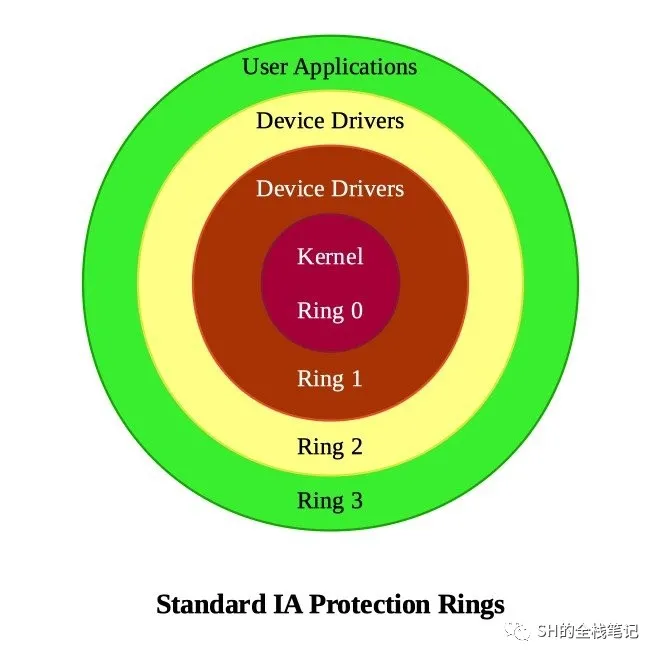
上图中的 IA 指的是 Intel Architecture
所以可以看到,越靠近的核心的权限越高。换句话说,权限由高到低为:Ring0 > Ring1 > Ring2 > Ring3
在 Linux 系统中,由于只有 Ring0 和 Ring3 级别的指令,所以我们可以对用户态、内核态给一个更细节的区别描述:运行 Ring0 级别指令的叫内核态,运行 Ring3 级别指令的叫用户态。

内核态用户态
了解了指令集权限的概念,我们就可以再更正一下上面的描述:什么态实际上代表的是当前 CPU 正在执行什么级别的指令
知道了用户态和内核态的区别、以及为什么要对其进行区别之后,我们就可以来看什么时候会从用户态切换到内核态了。
答案是发生系统调用的时候
那什么又是系统调用呢?看这张图
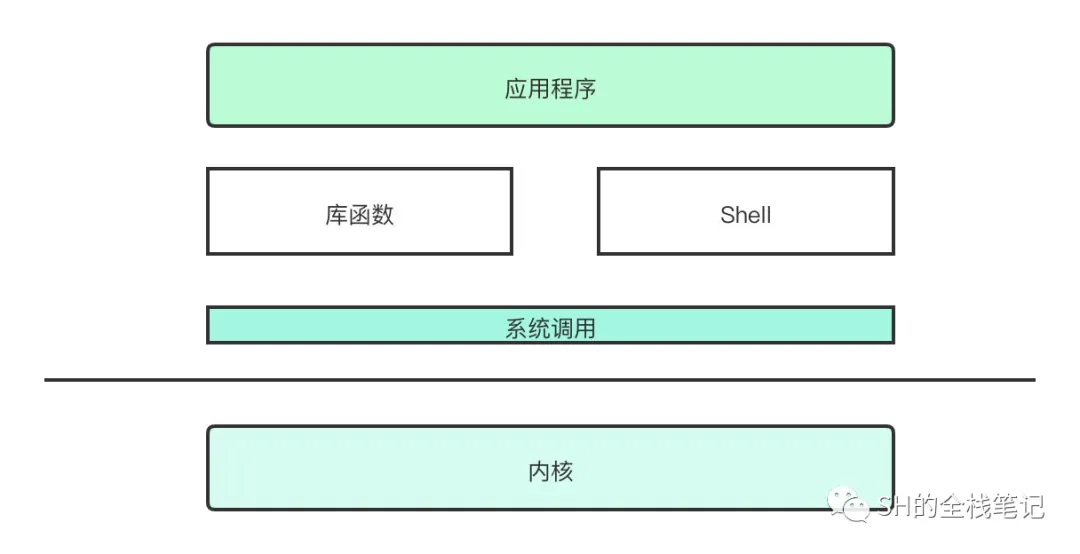
系统调用 (1)
当用户态的程序需要向操作系统申请更高权限的服务时,就通过系统调用向内核发起请求。
内核自然也会提供很多的接口来供调用,例如申请动态内存空间。但是申请了内存是不是还得考虑释放内存?如果把这块内存管理交给应用程序的话,复杂的管理工作会给开发带来很多负担。
所以库函数就是用于屏蔽掉内部复杂的细节的,我们的应用程序可以通过库函数来调用内核的提供的接口,而库函数就会发起系统调用,发起了系统调用之后,用户态就会切换成内核态去执行对应的内核方法。
除了系统调用之外,还有另外两种会导致态的切换:发生异常、中断。