从本篇文章起,就要基于 raft 构建分布式 kv 了。
raft 是一个分布式一致性算法,主要保证的是在分布式系统中,各个节点的数据一致性。raft 算法比较复杂,因为它所解决的分布式一致性问题本来就是一个比较棘手的问题,raft 算法的实现主要可以拆解为三个部分:
- 领导选举
- 日志复制
- 安全性
如果不太熟悉 raft 算法,可以看下这个网站的动画展示:
http://thesecretlivesofdata.com/raft
非常形象的展示了 raft 算法面临的问题,以及 raft 算法解决问题的基本过程。
当然,raft 算法的 paper 也值得参考:
https://github.com/maemual/raft-zh_cn
我在网上还找到了一个不错的 raft 算法的系列文章:
https://www.codedump.info/post/20180921-raft
https://blog.betacat.io/post/raft-implementation-in-etcd
看完了这些资料之后,应该就对 raft 算法有了一个大致的了解,然后就可以看看具体怎么实现。
这篇文章暂时只介绍第一个 Leader 选举问题,对应的是 TinyKV 中的 Project 2aa 部分。
在 raft 集群中,节点分为了三种状态:Follower(跟随者)、Candidate(候选者)、Leader(领导者),节点的初始状态是 Follower。
Follower 节点需要定期获取 Leader 的心跳信息来维持自己的状态。Follower 节点有一个超时时间(ElectionTimeout),在这段时间内,如果它没有收到来自 Leader 的心跳信息,那么它会认为集群中没有 Leader,然后便会发起选举。
选举的具体流程:
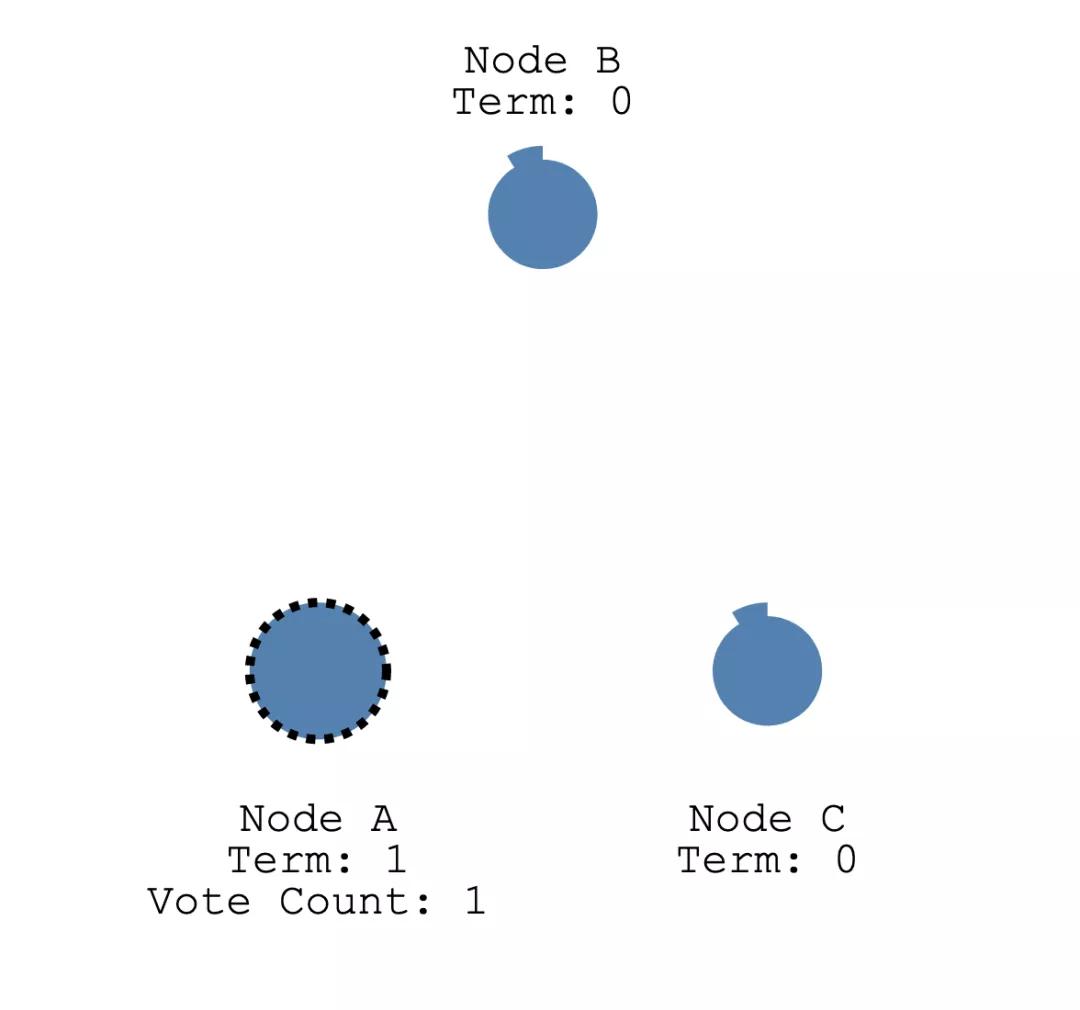
如上图,节点 A 的 Election Timeout 最先到达,因此它会将自己的状态变更为 Candidate,并且将任期号 Term 加 1(图中最开始的任期号是 0,加一之后变为 1),然后给自己投票,并且发送请求投票消息给 B 和 C 两个节点。
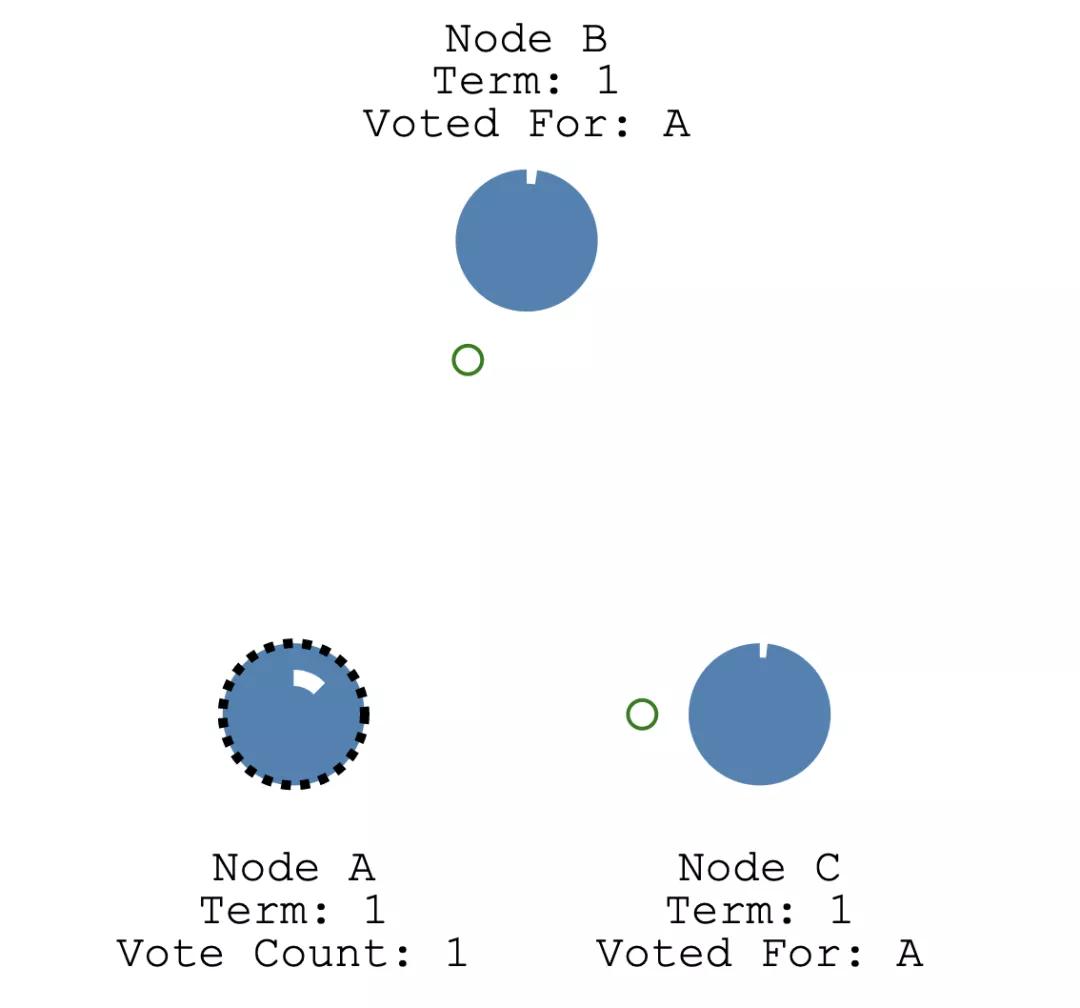
B、C 节点发现自己的任期号比 A 小,所以就会给 A 投同意票,A 节点收到回复之后,计算投票是否超过了节点数的一半,如果满足则成为 Leader。
以上阐述的是最理想的 Leader 选举的情况,严格来说 Candidate 节点发起选举后,需要一直保持状态直到以下情况之一发生:
- 它自身赢得了选举
- 其他的节点赢得了选举
- 选举超时到来,没有节点成为 Leader
第一种情况,就是上面描述的选举流程,它自身发起选举,并且赢得了超过半数节点的投票,然后成为了 Leader。
第二种情况,如果选举的过程当中,有其他的节点成为 Candidate 并且赢得了选举,那么它收到新的 Leader 发来的 AppendEntry RPC 消息,并且如果新的 Leader 任期号比自身的更大,那么它会认为这个 Leader 是有效的,自身变更为 Follower。
第三种情况,对应的是节点在选举中没有输也没有赢,如果集群节点是偶数个,并且同时有两个节点发起选举,那么便可能会出现这种情况,这样的话选举便是无效的。当选举超时再次到来时,如果还是没有新的 Leader,那么 Candidate 会发起新的一轮选举。
具体到代码实现,首先,最开始的逻辑在 tick 函数中,这里会由外层进行调用,我们需要判断节点的 Election Timeout 是否到了,如果是的话,则需要发起选举。
- // tick advances the internal logical clock by a single tick.
- func (r *Raft) tick() {
- // Your Code Here (2A).
- switch r.State {
- case StateLeader:
- // ...
- case StateFollower, StateCandidate:
- r.electionElapsed++
- if r.electionElapsed >= r.electionTimeout {
- // 发起新的选举
- r.startElection()
- }
- }
- }
发起选举,自身变更为 Candidate,任期号 + 1,并且给自己投票。然后需要向其他节点发送 MsgRequestVote 类型的消息。
MsgRequestVote 消息需要包含当前节点最后一条日志的 Index 和 Term,方便 Follower 判断该节点的日志是不是最新的。
其他的 Follower 节点收到 MsgRequestVote 消息之后开始处理,处理时需要注意几个点:
- 如果 msg 的任期号 Term 比自己的 Term 小,直接拒绝这个消息
- 如果 msg 的 Term 比自己的大,则自己需要变更为 Follower(如果不是 Follower 的话),并更新 Term
- 需要检查 msg 的任期号和 index 号,如果 msg 的日志不是最新的,拒绝这个消息
校验全部通过之后,Follower 节点就会投赞成票,然后发送 MsgRequestVoteResponse 消息给 Candidate 节点。
Candidate 节点收到 MsgRequestVoteResponse 消息之后,需要记下投票的结果,然后计算投票是否满足:
- 如果拒绝票超过节点数的 1/2,那么竞选失败,Candidate 节点变为 Follower 状态
- 如果赞成票超过节点数的 1/2,那么竞选成功
如果竞选成功,需要变更自己的状态为 Leader,然后向其他节点发送一个 MsgAppend 消息,附带一个空的数据 Entry,防止其他节点继续发起选举。
ps. 具体的代码实现可参考 etcd 的 raft,然后再基于此来自己手动实现 TinyKV 中的代码。