搜索引擎在任何人的日常生活和工作中都承担着很重要的角色,说到搜索大家想到的最多可能就是百度,谷歌,必应等搜索引擎。
这些确实是 PC 互联网时代的搜索先锋,但是现在移动互联网时代搜索已经很普及了,各大应用基本上都支持搜索,像抖音,微信,知乎等等应用程序,都会内置搜索引擎来实现自家内容的搜索。
Elasticsearch 是一个实时的分布式搜索分析引擎,它的搜索速度和规模,堪称前所未有。我们只需要把数据按照规定的索引格式去存储,后续就可以进行极致的搜索,因此 Elasticsearch 被广泛的应用于各大互联网公司。
根据 Elasticsearch 的官方介绍,Wikipedia,Github,Stack Overflow 等大厂都在使用。
Wikipedia 使用 Elasticsearch 提供带有高亮片段的全文搜索,还有 search-as-you-type 和 did-you-mean 的建议。
卫报使用 Elasticsearch 将网络社交数据结合到访客日志中,为它的编辑们提供公众对于新文章的实时反馈。
Stack Overflow 将地理位置查询融入全文检索中去,并且使用 more-like-this 接口去查找相关的问题和回答。
GitHub 使用 Elasticsearch 对1300亿行代码进行查询。
安装使用
Elasticsearch 提供了开箱即用的功能,我们通过在官网 https://www.elastic.co/downloads/elasticsearch 下载最新的符合自己电脑系统的稳定版本,然后解压后执行./bin/elasticsearch

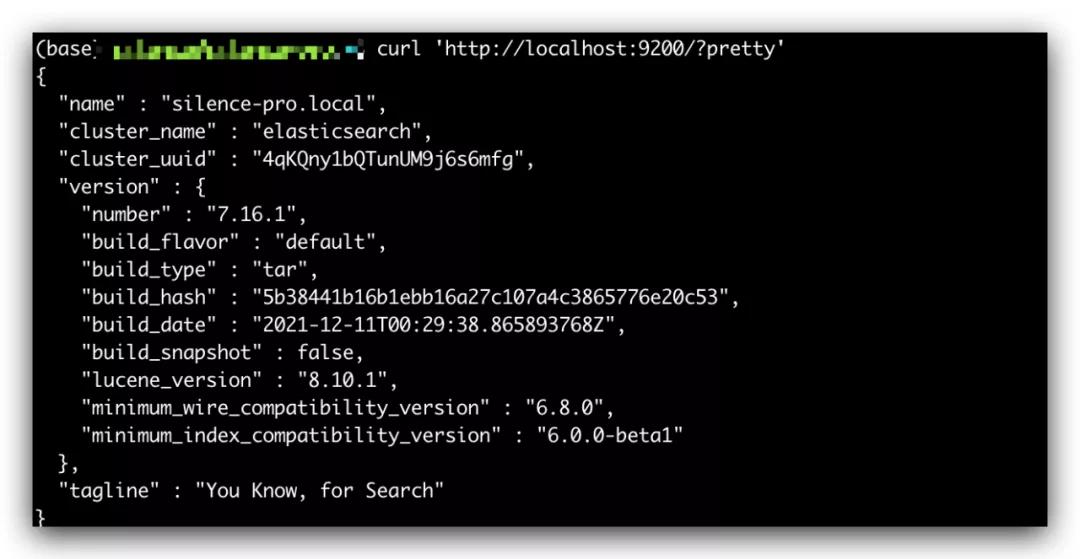
显示 successfully 表示启动成功,再通过执行命令curl 'http://localhost:9200/?pretty' 可以看到如下输出,表示 Elasticsearch 本地启动成功。
在使用 Elasticsearch 之前,我们先简单介绍一个 Elasticsearch 的存储结构,便于我们后面进行学习。
首先我们要知道一个事情那就是 Elasticsearch 是面向文档的,所谓文档就是一个 document,如果用过 MongoDB的话,小伙伴对文档应该比较熟悉,是一个 NoSQL 的形式,可以理解为一个JSON 形式的结构,跟我们常用的 MySQL 关系型的结构不一样,目前基本上任何一门语言的对象都可以直接转化成 JSON 形式,这极大方便了我们的使用。
文档的形式
文档的组成由文档数据和元数据组成,其中元数据包括_index,_type,_id 三个特别重要的元数据,其中 _index 表示文档在哪存放,_type 表示文档的对象类别,_id文档唯一标识。
虽然 Elasticsearch 是以文档形式存储的,但这里我们可以用关系型数据库作类比,比如这里的_index 可以类似于 MySQL 的 database,_type 类似有 MySQL 的 table,其中_id 类似于 ID 字段。
与 Elasticsearch 进行交互
通过官方文档我们可以知道一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:curl -X
被 < > 标记的部分表示含义如下:
| 标记 | 含义 |
|---|---|
VERB |
适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者DELETE。 |
PROTOCOL |
http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
HOST |
Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
PORT |
运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
PATH |
API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
QUERY_STRING |
任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
BODY |
一个 JSON 格式的请求体 (如果请求需要的话) |
示例
查看 Elasticsearch 集群中文档的个数:
- curl -XGET 'http://localhost:9200/_count?pretty' -H 'Content-Type:application/json' -d '
- "query": {
- "match_all": {}
- }
- '
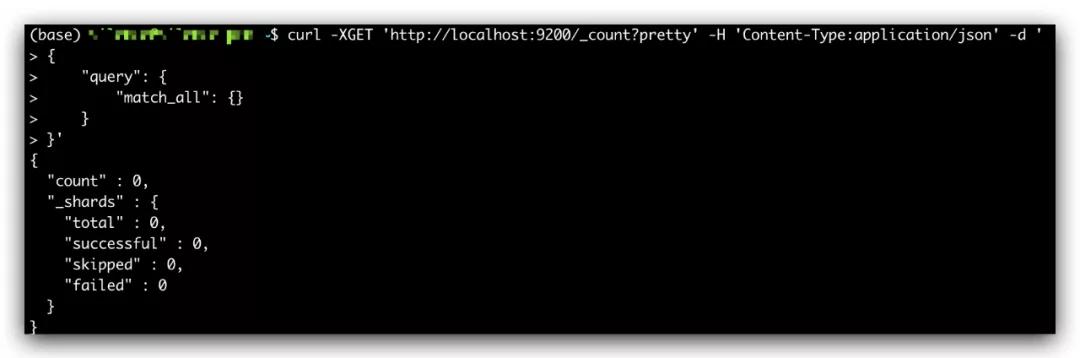
返回如下,其中 count 为 0,表示我们集群中暂时还没有文档:
索引文档
通过我们上面提到的内容,这里我们尝试进行一个文档的索引,语句如下,然后再查询一下文档的数据,结果如下
- curl -XPUT 'http://localhost:9200/student/class1/1?pretty' -H 'Content-Type:application/json' -d '
- {
- "name": "ziyou",
- "age": "18",
- "date": "2021/12/19"
- }
- '
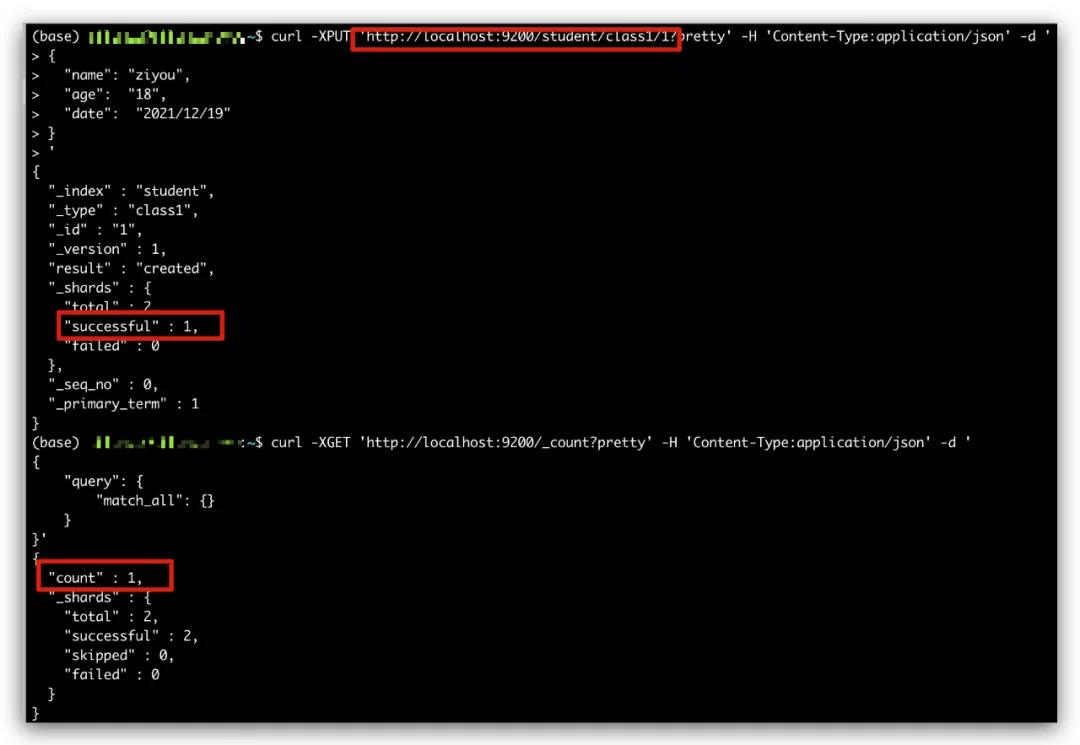
这里我们通过像 student 索引 class1 的 type 下面索引了一篇 id 为 1 的学生,通过 pretty 参数将返回美化查看,通过上面的操作,现在我们的 Elasticsearch 集群里面已经存在了一个 id 为 1 的学生了。
查询文档
索引文档过后,我们再根据下面的语句进行文档的获取
- curl -XGET 'http://localhost:9200/student/class1/1?pretty'
更新文档
我们可以通过前面 PUT 语句再次执行,进行文档的更新,如下所示
- curl -XPUT 'http://localhost:9200/student/class1/1?pretty' -H 'Content-Type:application/json' -d '
- {
- "name": "ziyou",
- "age": "20",
- "date": "2021/12/19"
- }
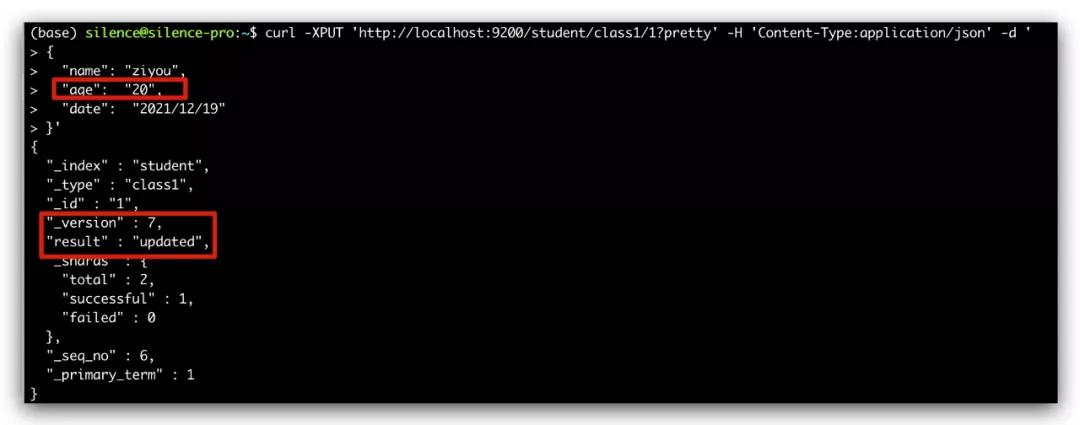
说明:可以看到 age 这个字段已经变更了,但是这里我们还看到多了一个 version 字段,正常这里应该是 2 ,阿粉只是多操作了几次所以这里是 7。
需要说明的是,更新文档并不是更新原来的文档,Elasticsearch 底层帮我们把原来的文档标记成删除状态,然后创建了一个新的文档,再加上了一个版本号,因为文档 ID 是没有变化的。
当随着我们索引数据的越来越多,Elasticsearch 底层会帮我们清理这些删除的文档数据,从我们的视角来看,就是文档已经更新了。
删除文档
- curl -XDELETE 'http://localhost:9200/student/class1/1
通过 DELETE 指令,我们可以将文档进行删除,删除也同更新一样,只是标记为删除状态,并不会立马从磁盘中删除,随着不断的索引更多的数据,Elasticsearch 将会在后台清理标记为已删除的文档。同时进行删除的时候,version 版本也会进行增加。