













在数据架构中,数据流水线一般以数据为起点,以洞见为终点。如何从起点到终点,取决于一系列的因素。图1展示了一个数据架构下的数据流水线。
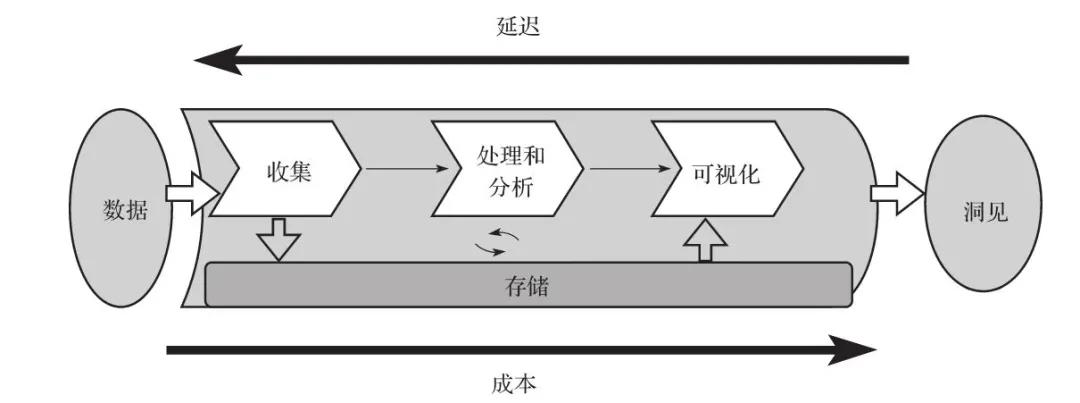
图1 大数据架构设计中的数据流水线
如图1所示,大数据流水线的标准工作流程包括以下步骤:
1)通过合适的工具收集数据(摄取)。
2)持久化存储数据。
3)数据处理或分析。从存储中获取数据,对其进行操作,然后将处理后的数据再次存储。
4)数据被其他处理/分析工具使用,或者被同一工具再次处理,从数据中获得进一步的结果。
5)为了使结果对业务用户有用,使用商业智能(BI)工具将结果可视化,或者将结果输入机器学习算法中进行预测。
6)一旦将合理的结果呈现给用户,这就为他们提供了对数据的洞见,然后他们可以采用这些数据进行进一步的业务决策。
你在流水线中部署的工具决定了获得结果的时间,也就是从数据被创建到能从中获得洞见之间的延迟。在考虑延迟的同时,设计数据架构的最佳方法是确定如何平衡吞吐量与成本,因为更高的性能和随之而来的低延迟通常会导致更高的成本。
大数据处理流水线设计
许多大数据架构所犯的关键性错误之一是,试图用一个工具包办数据流水线的多个阶段的数据处理。用一个服务器机群来端到端地处理从数据存储、转换到数据可视化的整个流水线可能是最简单,但它也是最容易发生故障的。这种紧耦合的大数据架构通常不能根据你的需求提供吞吐量和成本的最佳平衡。
建议数据架构师对流水线进行解耦,特别是将存储和处理分为多个阶段,这样做有很多好处,包括提高容错能力。例如,如果在第二轮处理中出了问题,或者专门用于处理该任务的硬件出现故障,不必从流水线的起点重新开始,系统可以从第二个存储阶段恢复。将存储与各个处理层解耦,使你有能力对多个数据存储进行读写。
图2说明了设计大数据架构流水线时需要考虑的各种工具和流程。
为大数据架构进行工具选型时,应该考虑以下几点:
- 数据结构。
- 最大可接受的延迟。
- 最低可接受的吞吐量。
- 系统终端用户的典型访问模式。
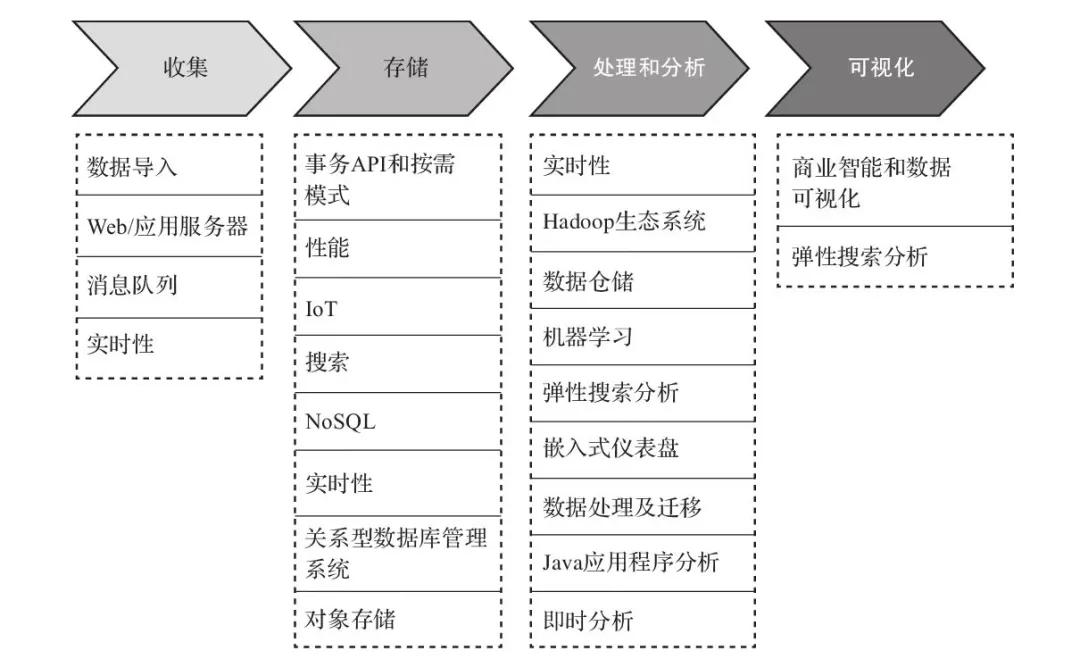
图2 大数据架构设计中的工具与流程
数据结构会影响数据处理工具以及存储位置的选择。数据的顺序及要存储和检索的数据对象的大小也是必不可少要考虑的因素。获得结果的时间取决于解决方案如何权衡延迟、吞吐量和成本。
用户访问模式是另一个需要考虑的重要因素。有些作业需要定期快速连接许多相关的表,有些作业则需要每天或按更低频率使用存储的数据。有些作业需要比较来自各种数据源的数据,而有些作业只需要从一个非结构化表中提取数据。了解终端用户最常使用数据的方式将有助于确定大数据架构的广度和深度。接下来,我们将更加深入地探讨大数据架构中的每个流程和涉及的工具。
本文摘编自《解决方案架构师修炼之道》,经出版方授权发布。(ISBN:9787111694441)转载请保留文章出处。




















