













1.序篇
废话不多说,咱们先直接上本文的目录和结论,小伙伴可以先看结论快速了解博主期望本文能给小伙伴们带来什么帮助:
- 背景及应用场景介绍:博主期望你能了解到,Flink 支持了 SQL 和 Table API 中的 Table 与 DataStream 互转的接口。通过这种互转的方式,我们就可以将一些自定义的数据源(DataStream)创建为 SQL 表,也可以将 SQL 执行结果转换为 DataStream 然后后续去完成一些在 SQL 中实现不了的复杂操作。肥肠的方便。
- 目前只有流任务支持互转,批任务不支持:在 1.13 版本中,由于流和批的 env 接口不一样,流任务为 StreamTableEnvironment,批任务为 TableEnvironment,目前只有 StreamTableEnvironment 支持了互转的接口,TableEnvironment 没有这样的接口,因此目前流任务支持互转,批任务不支持。但是 1.14 版本中流批任务的 env 都统一到了 StreamTableEnvironment 中,流批任务中就都可以进行互转了。
- Retract 语义 SQL 转 DataStream 需要重点注意:Append 语义的 SQL 转为 DataStream 使用的 API 为 StreamTableEnvironment::toDataStream,Retract 语义的 SQL 转为 DataStream 使用的 API 为 StreamTableEnvironment::toRetractStream,两个接口不一样,小伙伴萌一定要特别注意。
2.背景及应用场景介绍
相信大家看到本文的标题时,会比较好奇,要写 SQL 就纯 SQL 呗,要写 DataStream 就纯 DataStream 呗,为啥还要把这两个接口做集成呢?
博主举一个案例:在拼多多发优惠券的场景下,为了控制成本,希望能在每日优惠券发放金额加和超过 1w 时,及时报警出来,控制预算。
优惠券表的发放数据:
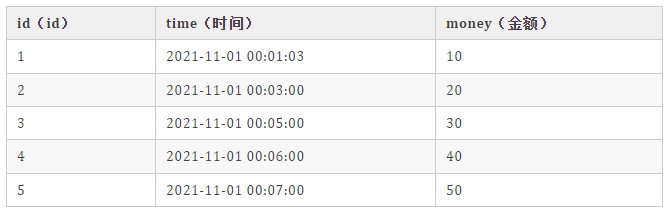
最终期望的结果是:每天的 money 之和超过 1w 的时候,报警报警报警!!!
那么针对上述场景,有两种对应的解决方案:
- 方案 1:可想而知,DataStream 是必然能够解决我们的问题的。
- 方案 2:DataStream 开发效率不高,可以使用 SQL 计算优惠券发放的结果,但是 SQL 无法做到报警。所以可以将 SQL 的查询的结果(即 Table)转为 DataStream,然后在 DataStream 后自定义报警逻辑的算子,超过阈值进行报警。
本节就介绍方案 2 的实现思路。
注意:
当然还有一些其他的比如模式识别监控异常然后报警的场景使用 DataStream 去实现就更加复杂了,所以我们也可以使用类似的思路,先 SQL 实现业务逻辑,然后接一个 DataStream 算子实现报警逻辑。
3.Table 与 DataStream API 的转换具体实现
3.1.先看一个官网的简单案例
官网的案例主要是让大家看看要做到 Table 与 DataStream API 的转换会涉及到使用哪些接口。
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.table.api.Table;
- import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
- import org.apache.flink.types.Row;
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
- DataStream<String> dataStream = env.fromElements("Alice", "Bob", "John");
- // 1. 使用 StreamTableEnvironment::fromDataStream API 将 DataStream 转为 Table
- Table inputTable = tableEnv.fromDataStream(dataStream);
- // 将 Table 注册为一个临时表
- tableEnv.createTemporaryView("InputTable", inputTable);
- // 然后就可以在这个临时表上做一些自定义的查询了
- Table resultTable = tableEnv.sqlQuery("SELECT UPPER(f0) FROM InputTable");
- // 2. 也可以使用 StreamTableEnvironment::toDataStream 将 Table 转为 DataStream
- // 注意:这里只能转为 DataStream<Row>,其中的数据类型只能为 Row
- DataStream<Row> resultStream = tableEnv.toDataStream(resultTable);
- // 将 DataStream 结果打印到控制台
- resultStream.print();
- env.execute();
- // prints:
- // +I[Alice]
- // +I[Bob]
- // +I[John]
可以看到重点的接口就是:
- StreamTableEnvironment::toDataStream:将 Table 转为 DataStream
- StreamTableEnvironment::fromDataStream:将 DataStream 转为 Table
3.2.实现第 2 节中的逻辑
我们使用上面介绍的两个接口对优惠券发放金额预警的案例做一个实现。
- @Slf4j
- public class AlertExample {
- public static void main(String[] args) throws Exception {
- FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
- String createTableSql = "CREATE TABLE source_table (\n"
- + " id BIGINT,\n"
- + " money BIGINT,\n"
- + " row_time AS cast(CURRENT_TIMESTAMP as timestamp_LTZ(3)),\n"
- + " WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND\n"
- + ") WITH (\n"
- + " 'connector' = 'datagen',\n"
- + " 'rows-per-second' = '1',\n"
- + " 'fields.id.min' = '1',\n"
- + " 'fields.id.max' = '100000',\n"
- + " 'fields.money.min' = '1',\n"
- + " 'fields.money.max' = '100000'\n"
- + ")\n";
- String querySql = "SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, \n"
- + " window_start, \n"
- + " sum(money) as sum_money,\n"
- + " count(distinct id) as count_distinct_id\n"
- + "FROM TABLE(CUMULATE(\n"
- + " TABLE source_table\n"
- + " , DESCRIPTOR(row_time)\n"
- + " , INTERVAL '5' SECOND\n"
- + " , INTERVAL '1' DAY))\n"
- + "GROUP BY window_start, \n"
- + " window_end";
- // 1. 创建数据源表,即优惠券发放明细数据
- flinkEnv.streamTEnv().executeSql(createTableSql);
- // 2. 执行 query 查询,计算每日发放金额
- Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
- // 3. 报警逻辑(toDataStream 返回 Row 类型),如果 sum_money 超过 1w,报警
- flinkEnv.streamTEnv()
- .toDataStream(resultTable, Row.class)
- .flatMap(new FlatMapFunction<Row, Object>() {
- @Override
- public void flatMap(Row value, Collector<Object> out) throws Exception {
- long l = Long.parseLong(String.valueOf(value.getField("sum_money")));
- if (l > 10000L) {
- log.info("报警,超过 1w");
- }
- }
- });
- flinkEnv.env().execute();
- }
- }
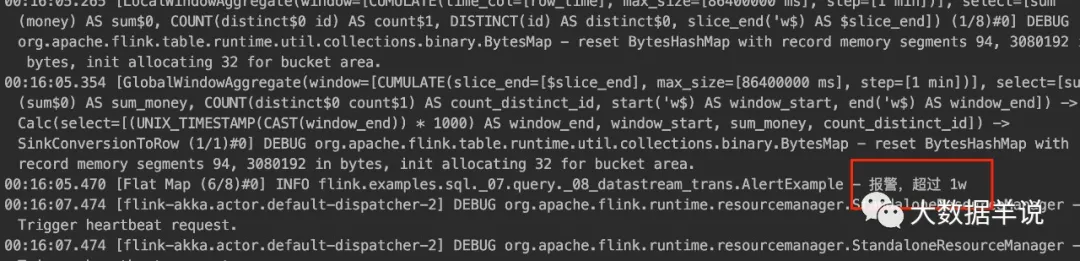
执行效果如下:
3.3.Table 和 DataStream 转换注意事项
3.3.1.目前只支持流任务互转(1.13)
目前在 1.13 版本中,Flink 对于 Table 和 DataStream 的转化是有一些限制的:
目前流任务使用的 env 为 StreamTableEnvironment,批任务为 TableEnvironment,而 Table 和 DataStream 之间的转换目前只有 StreamTableEnvironment 的接口支持。
所以其实小伙伴萌可以理解为只有流任务才支持 Table 和 DataStream 之间的转换,批任务是不支持的(虽然可以使用流模式处理有界流(批数据),但效率较低,这种骚操作不建议大家搞)。
那什么时候才能支持批任务的 Table 和 DataStream 之间的转换呢?
1.14 版本支持。1.14 版本中,流和批的都统一到了 StreamTableEnvironment 中,因此就可以做 Table 和 DataStream 的互相转换了。
3.3.2.Retract 语义 SQL 转 DataStream 注意事项
Retract 语义的 SQL 使用 toDataStream 转换会报错不支持。具体报错截图如下。意思是不支持 update 类型的结果数据。

如果要把 Retract 语义的 SQL 转为 DataStream,我们需要使用 toRetractStream。如下案例:
- @Slf4j
- public class AlertExampleRetract {
- public static void main(String[] args) throws Exception {
- FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
- String createTableSql = "CREATE TABLE source_table (\n"
- + " id BIGINT,\n"
- + " money BIGINT,\n"
- + " `time` as cast(CURRENT_TIMESTAMP as bigint) * 1000\n"
- + ") WITH (\n"
- + " 'connector' = 'datagen',\n"
- + " 'rows-per-second' = '1',\n"
- + " 'fields.id.min' = '1',\n"
- + " 'fields.id.max' = '100000',\n"
- + " 'fields.money.min' = '1',\n"
- + " 'fields.money.max' = '100000'\n"
- + ")\n";
- String querySql = "SELECT max(`time`), \n"
- + " sum(money) as sum_money\n"
- + "FROM source_table\n"
- + "GROUP BY (`time` + 8 * 3600 * 1000) / (24 * 3600 * 1000)";
- // 1. 创建数据源表,即优惠券发放明细数据
- flinkEnv.streamTEnv().executeSql(createTableSql);
- // 2. 执行 query 查询,计算每日发放金额
- Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
- // 3. 报警逻辑(toRetractStream 返回 Tuple2<Boolean, Row> 类型),如果 sum_money 超过 1w,报警
- // Tuple2<Boolean, Row> f0 的 Boolean 标识是否是回撤消息
- flinkEnv.streamTEnv()
- .toRetractStream(resultTable, Row.class)
- .flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, Object>() {
- @Override
- public void flatMap(Tuple2<Boolean, Row> value, Collector<Object> out) throws Exception {
- long l = Long.parseLong(String.valueOf(value.f1.getField("sum_money")));
- if (l > 10000L) {
- log.info("报警,超过 1w");
- }
- }
- });
- flinkEnv.env().execute();
- }
- }
4.总结与展望
本文主要介绍了 flink 中 Table 和 DataStream 互转使用方式,并介绍了一些使用注意事项,总结如下:
- 背景及应用场景介绍:博主期望你能了解到,Flink 支持了 SQL 和 Table API 中的 Table 与 DataStream 互转的接口。通过这种互转的方式,我们就可以将一些自定义的数据源(DataStream)创建为 SQL 表,也可以将 SQL 执行结果转换为 DataStream 然后后续去完成一些在 SQL 中实现不了的复杂操作。肥肠的方便。
- 目前只有流任务支持互转,批任务不支持:在 1.13 版本中,由于流和批的 env 接口不一样,流任务为 StreamTableEnvironment,批任务为 TableEnvironment,目前只有 StreamTableEnvironment 支持了互转的接口,TableEnvironment 没有这样的接口,因此目前流任务支持互转,批任务不支持。但是 1.14 版本中流批任务的 env 都统一到了 StreamTableEnvironment 中,流批任务中就都可以进行互转了。
- Retract 语义 SQL 转 DataStream 需要重点注意:Append 语义的 SQL 转为 DataStream 使用的 API 为 StreamTableEnvironment::toDataStream,Retract 语义的 SQL 转为 DataStream 使用的 API 为 StreamTableEnvironment::toRetractStream,两个接口不一样,小伙伴萌一定要特别注意。






















