













在昨天的文章一日一技:爬虫模拟浏览器如何避免重复登录?中,我讲到了如何使用Puppeteer接管已经运行的Chrome。今天我们来讲讲使用Selenium如何实现这个功能。
在正式开始之前,先纠正昨天的一个错误。昨天我讲到,Windows电脑启动Chrome的远程调试模式用到的命令是:
- 文件路径/chrome.exe --remote-debugging-port=9222
这个地方漏掉了一个参数。正确的命令应该是:
- 文件路径/chrome.exe --remote-debugging-port=9222 --user-data-dir="某个存在的文件夹地址"
好了,回到正题。现在无论你使用macOS还是Windows,首先按昨天的文章所说,启动Chrome开放9222端口。然后,在这个Chrome中,手动登录示例网站。
接下来,编写下面这段代码:
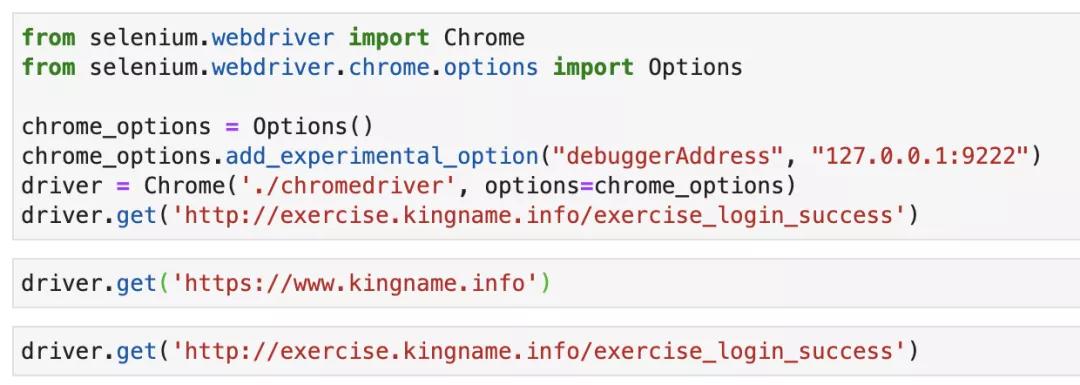
- from selenium.webdriver import Chrome
- from selenium.webdriver.chrome.options import Options
- chrome_options = Options()
- chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
- # 注意我把chromedriver文件放到了当前文件夹里面,所以可以这样调用
- # 如果你是windows电脑,你需要使用./chromedriver.exe
- driver = Chrome('./chromedriver', options=chrome_options)
- driver.get('http://exercise.kingname.info/exercise_login_success')
- input('输入任意内容继续')
- driver.get('https://www.kingname.info')
- input('输入任意内容继续')
- driver.get('http://exercise.kingname.info/exercise_login_success')
如下图所示:
由于使用Selenium的时候,始终操作的都是当前标签页,为了证明确实有效,所以我在示例代码里面,先把爬虫暂停,需要你在终端按下任何键以后,再打开我的博客。接下来,等你确认博客已经打开以后,再回到终端按下任意键,Chrome会再次打开登录成功的页面。
你还可以试一试把Python程序终止,再重新运行。你会发现代码依然可以接管这个浏览器窗口。























