大家好,我是冰河~~
很多小伙伴去大厂面试,几乎都会遇到一些开放式的题目,这些开放式的题目没有固定的答案,但是它能够实实在在的体现面试者较为真实的系统设计能力和技术功底。如果你回答的比较完美,那么,通过这种开放式题目,就能够让你从众多的面试者中脱颖而出。
今天,我们就一起来聊聊,去大厂面试时,一个较为常见的开放式题目:如果让你设计一个高并发的消息中间件,你会怎么做?
消息中间件涉及的知识点
要想设计一个具有高并发的消息中间件,那么首先就要了解下消息中间件涉及哪些具体的知识点。通常,设计一个良好的消息中间件最少需要满足如下条件:
- 生产者、消费者模型。
- 支持分布式架构。
- 数据的高可用。
- 消息数据不丢失。
接下来,我们就针对消息中间件来分别谈谈这些技术点。
生产者消费者模型
相信很多小伙伴对于生产者和消费者模型都比较了解了,简单的说:就是消息中间件能够使其他应用来生产消息,也能够使其他应用来消费相应的消息。
对于生产者和消费者模型,我们需要考虑的问题点就比较多了。接下来,我就一步步来引导大家进行思考。
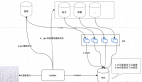
首先,我们来思考这样一个问题:如果生产者生产了消息,那么消息中间件应该怎样存储相应的数据呢?存储在内存? 存储在磁盘?还是同时存储在内存和磁盘中呢?
如果是将消息数据同时存储在内存和磁盘中,我们又该如何处理这些数据呢?是生产者将消息投递到消息中间件之后,我们就立刻将数据写入磁盘?还是说数据先驻留到内存,然后每隔一段时间刷到磁盘上?
如果是每隔一段时间刷到磁盘上,那我们又要考虑磁盘文件的切分问题,也就是说,需要将消息数据分成多少个磁盘文件?(总不能把所有的数据放到一个磁盘文件中吧)。如果是需要切分成多个磁盘文件,那切分的规则又是什么呢?
上面这些问题都是我们在设计一个消息中间件时需要考虑的问题。然而,这还只是一小部分问题。如果想在面试时脱颖而出,那就还需要继续往下看,还有一些重要的问题点需要注意。
如果文件按照一定的规则切分到多个磁盘文件中了,那是不是还需要管理元数据来标识数据的具体消息(就像是Hadoop中的NameNode节点中存储着DataNode的元数据信息,NameNode节点通过这些元数据信息就能够更好的管理DataNode节点)?
这些元数据可以包括:消息数据的偏移量、也可以是消息数据的唯一ID。
考虑完数据的存储问题,我们还需要考虑的是:消息中间件是如何将数据投递到对应的消费者的?
在设计生产者和消费者时,还一个很重要的问题需要我们考虑:我们在设计消息中间件时,采用的消费模式是什么?会不会将数据均匀的分配给消费者?还是会通过一些其他的规则将数据投递到消费者?
支持分布式架构
如果我们设计的消息中间件,每天会承载TB级别的数据高并发和高吞吐量的写入操作。这里,我们就需要考虑将消息中间件设计成分布式架构。
在设计分布式架构时,我们还需要考虑将存储的比较大的数据,做成分片存储,对数据进行分片等操作。
除了这些,我们还需要考虑另外一个核心问题:对于消息中间件来说,需要支持自动扩容操作。
还有就是是否支持数据分片,如何实现数据分片的扩容和自动数据负载均衡迁移等。
数据的高可用
一般互联网应用的高可用,是通过本地堆内存,分布式缓存,和一份数据在不同的服务器上都搞一个副本来实现的。此时,任何一个存储节点宕机,都不会影响整体的高可用。我们在设计消息中间件时也可以参考这个思路。
消息数据不丢失
此时,我们就需要提供手动ACK的机制,也就是说:当消费者真正消费消息完毕后,向消息中间件返回“ 处理完成” 的标识,消息中间件删除相应的已处理的消息。
但是,细化的话,这里,我们就需要两套ACK机制:
一种ACK对应的是生产端。如果一直没有接收到ACK消息,则需要通过生产者来重新发送一条消息来保证生产消息成功。
另一种ACK对应的是消费端。一旦一条消息消费并处理成功,必须返回一个ack给消息中间件,然后消息中间件才能删除这条消息。否则一旦消费者宕机,就必须重发这条消息给其他的消费者实例,保证消息一定会被处理成功。
今天,我们没有聊具体的业务点,而是从整体上考虑:如果实现一个消息中间件,需要我们注意的各项知识点和专业技能!