












谷歌团队在CoRL 2021上提出了一种隐式行为克隆 (Implicit BC) 算法,该方法在7项测试任务中的6项上优于此前最佳的离线强化学习方法(Conservative Q Learning)。Implicit BC在现实世界中表现也得特别好,比基线的显式行为克隆(explicit BC)模型好10倍。
尽管过去几年中,机器人学习取得了相当大的进步,但在模仿精确或复杂的行为时,机器人代理的一些策略仍难以果断地选择动作。
要让机器人把桌子上的小滑块精确地滑进一个插槽里。解决这个任务有很多方法,每种方法都需要精确的移动和修正。机器人只能采取这些策略选项中的一个,还必须在每次滑块滑得比预期的更远时及时改变策略。
人类可能认为这样的任务很容易,但对于机器人来说,情况往往并非如此,它们经常会学习一些人类专家看来「优柔寡断」或「不精确」的行为。

机器人需要在桌子上滑动滑块,然后将其精确插入固定装置,显式行为克隆模型表现得很犹豫
为了让机器人更加果断,研究人员经常利用离散化的动作空间,迫使机器人进行明确的「二选一」,而不是在选项之间摇摆不定。
比如,离散化是近年来很多游戏agent著名模型的固有特征,比如AlphaGo、AlphaStar 和 OpenAI 打Dota的AI agent。
但离散化有其自身的局限性——对于在空间连续的现实世界中运行的机器人来说,离散化至少有两个缺点:
- 精度有限。
- 因计算维度导致成本过高,许多离散化不同的维度会显著增加内存和计算需求。在 3D 计算机视觉任务中,近期的许多重要模型都是由连续,而非离散表示来驱动的。
为了学习没有离散化特征缺陷的决定性策略,谷歌团队提出了一种隐式行为克隆 (Implicit BC) 的开源算法,这是一种新的、简单的模仿学习方法,已经在 CoRL 2021 上展示。
该方法在模拟基准任务和需要精确和果断行为的现实世界机器人任务上都取得了很好的结果。在7项测试任务中,隐式 BC 的性能在其中6项上优于此前最佳的离线强化学习方法(Conservative Q Learning)。
有趣的是,隐式 BC 在不需要任何奖励信息的情况下实现了这些结果,即可以使用相对简单的监督学习,而不是更复杂的强化学习。
隐式行为克隆(Implicit BC)
这种方法是一种行为克隆,可以说是机器人从演示中学习新技能的最简单的方法。在行为克隆中,agent会学习如何通过标准监督学习模仿专家的行为。传统的行为克隆一般是训练一个显式神经网络(如下图左所示),接受观察并输出专家动作。
而隐式行为克隆背后的关键思想是,训练一个神经网络来接受观察和动作,并输出一个数字,该数字对专家动作来说很低,对非专家动作来说很高,将行为克隆变成一个基于能量的建模问题。
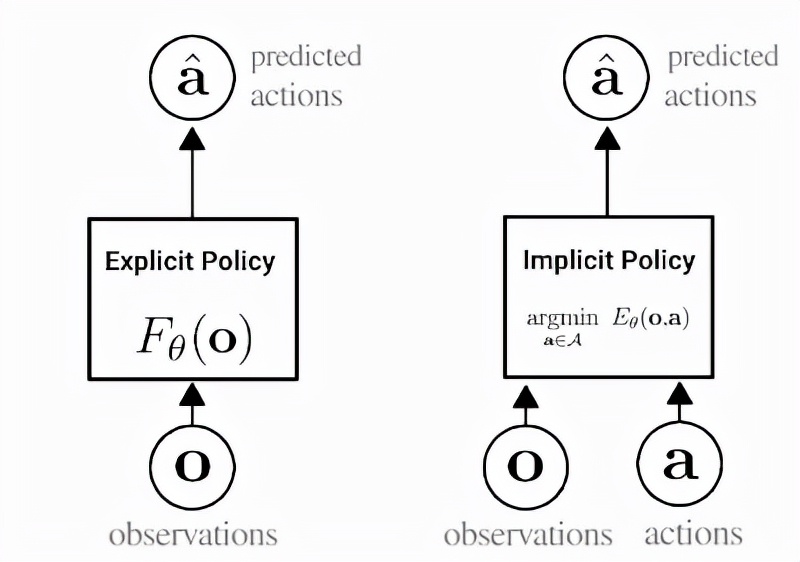
显式(左)和隐式(右)策略之间差异的描述。在隐式策略中,「argmin」表示与特定观察配对时最小化能量函数值的动作。
训练后,隐式行为克隆策略会查找对给定观察具有最低能量函数值的动作输入,以此生成动作。
为了训练隐式 BC 模型,研究人员使用InfoNCE损失,让网络为数据集中的专家动作输出低能量,为所有其他动作输出高能量。有趣的是,这种使用同时接受观察和行动的模型的思想在强化学习中很常见,但在有监督的策略学习中则不然。
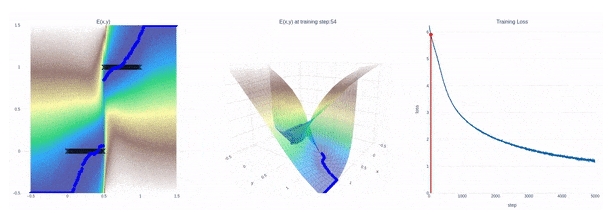
上图所示为隐式模型如何适应不连续性的动画——在这种情况下,训练隐式模型来适应一个步长(Heaviside)函数。左:拟合黑色训练点的2D图,颜色代表能量值(蓝色低,棕色高)。中间:训练期间能量模型的3D图。右图:训练损失曲线。
一旦经过训练,Google AI发现隐式模型(implicit model)特别擅长精确地建模先前显式模型(explicit model)难以解决的不连续性问题,从而产生新的策略,能够在不同行为之间果断切换。

为什么传统的显式模型(explicit model)在这个问题上表现不佳呢?
现代神经网络几乎总是使用连续激活函数——例如,Tensorflow、Jax和PyTorch都只提供连续激活函数。
在试图拟合不连续数据时,用这些激活函数构建的显式网络无法准确表示,因此必须在数据点之间绘制连续曲线。隐式模型(implicit model)的一个关键优势是,即使网络本身仅由连续层组成,也能够表示出尖锐的不连续性。
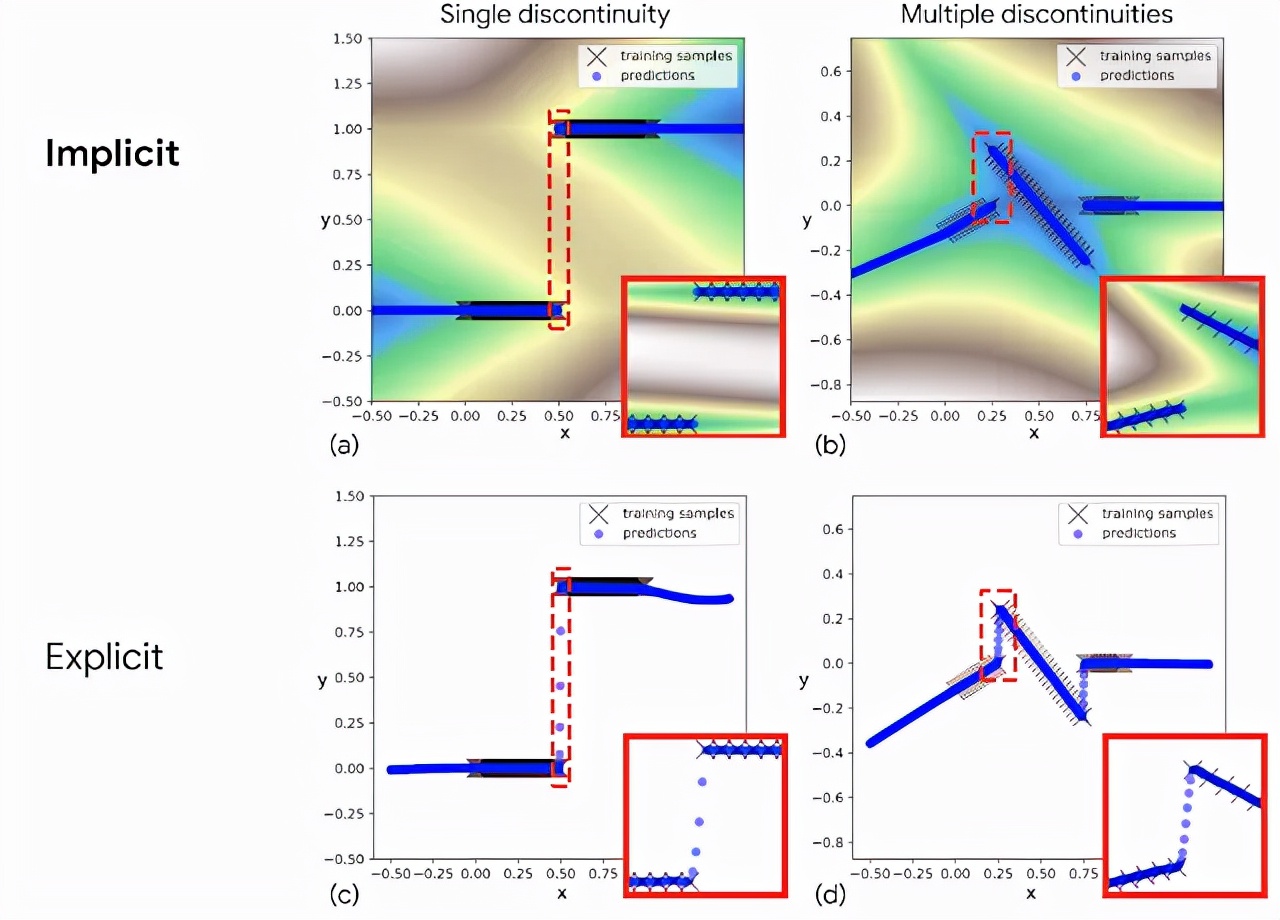
与显式模型(底部)相比,隐式模型(顶部)拟合不连续函数的示例。红色突出显示的插图显示,隐式模型表示不连续性(a)和(b),而显式模型必须在不连续性之间画出连续的线(c)和(d)
Google AI在这个方面建立了理论基础,提出了一个普遍近似的概念,证明了隐式神经网络可以表示的函数类别,这将有助于证明和指导未来的研究。
Google AI最初尝试这种方法时面临的一个挑战是「高动作维度」,这意味着机器人必须决定如何同时协调多个电机。为了扩展到高作用维度,Google AI使用自回归模型或朗之万动力学。
全新SOTA
在实验中,Google AI发现Implicit BC在现实世界中表现得特别好,在毫米精度的滑块滑动及插槽任务上比基线的显式行为克隆(explicit BC)模型好10倍。
在此任务中,隐式模型(implicit model)在将滑块滑动到位之前会进行几次连续的精确调整。

将滑块精确地插入插槽的示例任务。这些是隐式策略的自主行为,仅使用图像(来自所示的摄像机)作为输入
这项任务有多种决定性因素:由于块的对称性和推动动作的任意顺序,有许多不同的可能解决方案。
机器人需要决定滑块何时已经被推动足够远,然后需要切换到向不同方向滑动。这一过程是不连续的,所以,连续控制型机器人在这一任务上会表现得十分优柔寡断。

完成这项任务的不同策略。这些是来自隐式策略的自主行为,仅使用图像作为输入
在另一个具有挑战性的任务中,机器人需要按颜色对滑块进行筛选,由于挑选顺序是很随意的,这就产生了大量可能的解决方案。

颇具挑战性的连续筛选任务中显式BC模型的表现(4倍速度)
在这项任务中,显式模型(explicit model)还是表现得很拿不准,而隐式模型(implicit model)表现得更好。

颇具挑战性的连续筛选任务中隐式BC模型表现(4倍速度)
而且在Google AI的测试中,Implicit BC在面临干扰时,尽管模型从未见过人类的手,也依然可以表现出强大的适应能力。

机器人受到干扰时,隐式BC模型的稳健行为
总的来说,Google AI发现,与跨多个不同任务领域的最先进的离线强化学习方法相比,Implicit BC策略可以获得更好的结果。
Implicit BC可以完成很多具有挑战性的任务,比如演示次数少(少至19次),基于图像的观察具有高观察维度,还有高达30维的高动作维度,这就需要机器人充分利用自身具有的大量致动器。
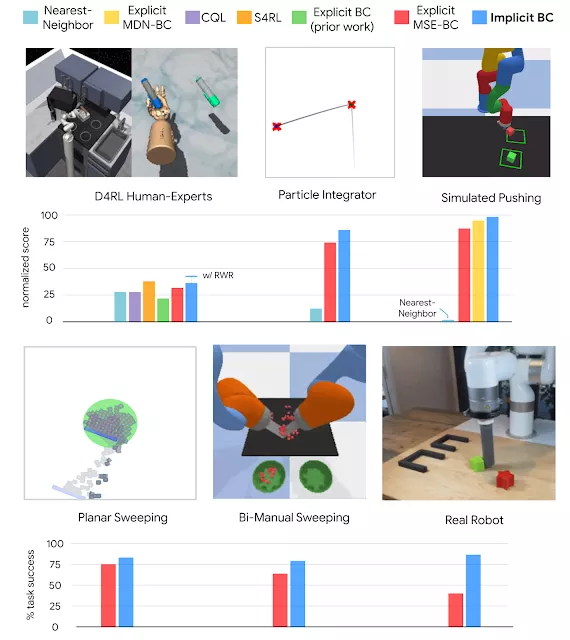
隐式策略学习结果与跨多个域的基线进行了比较
尽管Implicit BC目前还有其局限性,但使用监督学习的行为克隆仍然是机器人从人类行为例子中学习的最简单方法之一。
该工作表明,在进行行为克隆时,用隐式策略替换显式策略可以让机器人克服「犹犹豫豫」,使它们能够模仿更加复杂和精确的行为。
虽然Implicit BC取得的实验结果来自机器人学习问题上,但是隐式函数对尖锐不连续性和多模态标签建模的能力可能在机器学习的其他领域也有更广泛的应用。
















