本文转载自微信公众号「bigsai」,作者大赛鸽 。转载本文请联系bigsai公众号。
前言
hello,大家好,我是bigsai哥哥,好久不见,甚是想念哇??!
今天给大家分享一个TOPK问题,不过我这里不考虑特别大分布式的解决方案,普通的一道算法题。
首先搞清楚,什么是topK问题?
topK问题,就是找出序列中前k大(或小)的数,topK问题和第K大(或小)的解题思路其实大致一致的。
TopK问题是一个非常经典的问题,在笔试和面试中出现的频率都非常非常高(从不说假话)。下面,从小小白的出发点,认为topK是求前K大的问题,一起认识下TopK吧!
当前,在求TopK和第K大问题解法差不多,这里就用力扣215数组的第k个大元素 作为解答的题演示啦。可以看看这篇程序员必知必会十大排序非常有助于学习!
排序法
找到TopK,并且排序TopK
啥,你想要我找到TopK?不光光TopK,你想要多少个,我给你多少个,并且还给你排序给排好,啥排序我最熟悉呢?
如果你想到冒泡排序O(n^2)那你就大意了啊。
如果使用O(n^2)级别的排序算法,那也是要优化的,其中冒泡排序和简单选择排序,每一趟都能顺序确定一个最大(最小)的值,所以不需要把所有的数据都排序出来,只需要执行K次就行啦,所以这种算法的时间复杂度也是O(nk)。
这里给大家回顾一下冒泡排序和简单选择排序区别:
冒泡排序和简单选择排序都是多趟,每趟都能确定一个最大或者最小,区别就是冒泡在枚举过程中只和自己后面比较,如果比后面大那么就交换;而简单选择是每次标记一个最大或者最小的数和位置,然后用这一趟的最后一个位置数和它交换(每一趟确定一个数枚举范围都慢慢变小)。
下面用一张图表示过程:
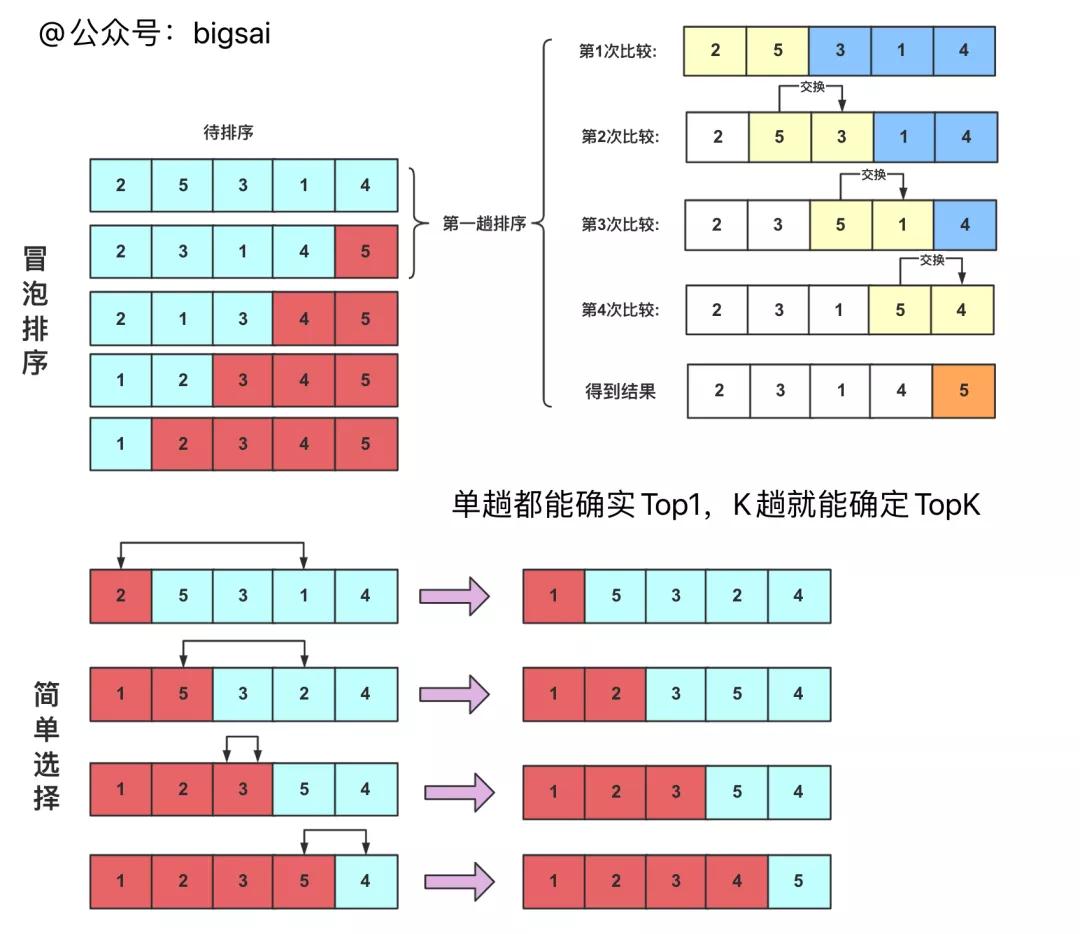
这里把code也给大家提供一下,简单选择上面图给的是每次选最小,实现的时候每次选最大就可以了。
- //交换数组中两位置元素
- private void swap(int[] arr, int i, int j) {
- int temp = arr[i];
- arr[i] = arr[j];
- arr[j] = temp;
- }
- //冒泡排序实现
- public int findKthLargest1(int[] nums, int k) {
- for(int i=nums.length-1;i>=nums.length-k;i--)//这里也只是k次
- {
- for(int j=0;j<i;j++)
- {
- if(nums[j]>nums[j+1])//和右侧邻居比较
- {
- swap(nums,j,j+1);
- }
- }
- }
- return nums[nums.length-k];
- }
- //简单选择实现
- public int findKthLargest2(int[] nums, int k) {
- for (int i = 0; i < k; i++) {//这里只需要K次
- int max = i; // 最小位置
- for (int j = i + 1; j < nums.length; j++) {
- if (nums[j] > nums[max]) {
- max = j; // 更换最小位置
- }
- }
- if (max != i) {
- swap(nums, i, max); // 与第i个位置进行交换
- }
- }
- return nums[k-1];
- }
当然,快排和归并排序甚至堆排序也可以啊,这些排序的时间复杂度为O(nlogn),也就是将所有数据排序完然后直接返回结果,这部分就不再详细讲解啦,调调api或者手写排序都可。
两种思路的话除了K极小的情况O(nk)快一些,大部分情况其实还是O(nlogn)情况快一些的,不过从O(n^2)想到O(nk),还是有所收获的。
基于堆排优化
这里需要知道堆相关的知识,我以前写过优先队列和堆排序,这里先不重复讲,大家也可以看一下:
优先队列不知道,看看堆排序吧
硬核,手写一个优先队列
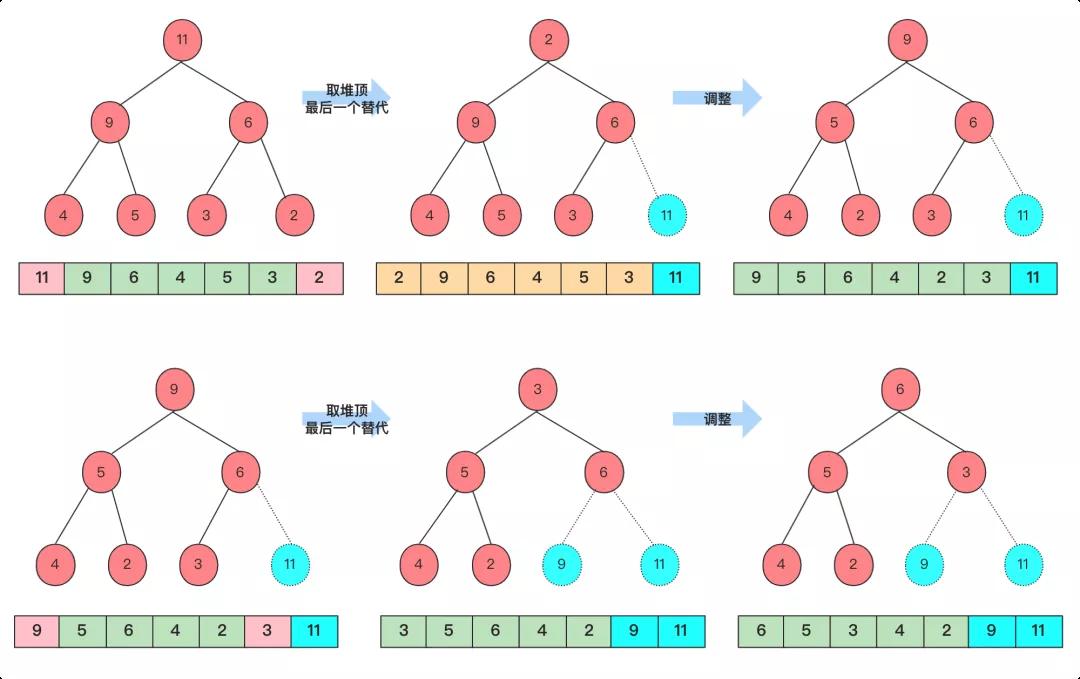
上面说道堆排序O(nlogn)那是将所有元素都排序完然后取前k个,但是其实上我们分析一下这个堆排序的过程和几个注意点哈:
堆这种数据结构,分为大根堆和小根堆,小根堆是父节点值小于子节点值,大根堆是父节点的值大于子节点的值,这里肯定是要采用大根堆的。
堆看起来是一个树形结构,但是堆是个完全二叉树我们用数组存储效率非常高,并且也非常容易利用下标直接找到父子节点,所以都用数组来实现堆,每次排序完成的节点都将数移到数组末尾让一个新数组组成一个新的堆继续。
堆排序从大的来看可以分成两个部分,无序数组建堆和在堆基础上每次取对顶排序。其中无序数组建堆的时间复杂度为O(n),在堆基础上排序每次取堆顶元素,然后将最后一个元素移到堆顶进行调整堆,每次只需要O(logn)级别的时间复杂度,完整排序完n次就是O(nlogn),但是咱们每次只需要k次,所以完成k个元素排序功能需要花费O(klogn)时间复杂度,整个时间复杂度为O(n+klogn)因为和前面区分一下就不合并了。
画了一张图帮助大家理解,进行两次就获得Top2,进行k次就获得TopK了。
实现代码为:
- class Solution {
- private void swap(int[] arr, int i, int j) {
- int temp = arr[i];
- arr[i] = arr[j];
- arr[j] = temp;
- }
- //下移交换 把当前节点有效变换成一个堆(大根)
- public void shiftDown(int arr[],int index,int len)//0 号位置不用
- {
- int leftchild=index*2+1;//左孩子
- int rightchild=index*2+2;//右孩子
- if(leftchild>=len)
- return;
- else if(rightchild<len&&arr[rightchild]>arr[index]&&arr[rightchild]>arr[leftchild])//右孩子在范围内并且应该交换
- {
- swap(arr, index, rightchild);//交换节点值
- shiftDown(arr, rightchild, len);//可能会对孩子节点的堆有影响,向下重构
- }
- else if(arr[leftchild]>arr[index])//交换左孩子
- {
- swap(arr, index, leftchild);
- shiftDown(arr, leftchild, len);
- }
- }
- //将数组创建成堆
- public void creatHeap(int arr[])
- {
- for(int i=arr.length/2;i>=0;i--)
- {
- shiftDown(arr, i,arr.length);
- }
- }
- public int findKthLargest(int nums[],int k)
- {
- //step1建堆
- creatHeap(nums);
- //step2 进行k次取值建堆,每次取堆顶元素放到末尾
- for(int i=0;i<k;i++)
- {
- int team=nums[0];
- nums[0]=nums[nums.length-1-i];//删除堆顶元素,将末尾元素放到堆顶
- nums[nums.length-1-i]=team;
- shiftDown(nums, 0, nums.length-i-1);//将这个堆调整为合法的大根堆,注意(逻辑上的)长度有变化
- }
- return nums[nums.length-k];
- }
- }
基于快排优化
上面堆排序都能优化,那么快排呢?
快排当然能啊,这么牛的事情怎么能少得了我快排呢?
这部分需要堆快排有一定了解和认识,前面很久前写过:图解手撕冒泡和快排 (后面待优化),快排的核心思想就是:分治 ,每次确定一个数字的位置,然后将数字分成两个部分,左侧比它小,右侧比它大,然后递归调用这个过程。每次调整的时间复杂度为O(n),平均次数为logn次,所以平均时间复杂度为O(nlogn)。
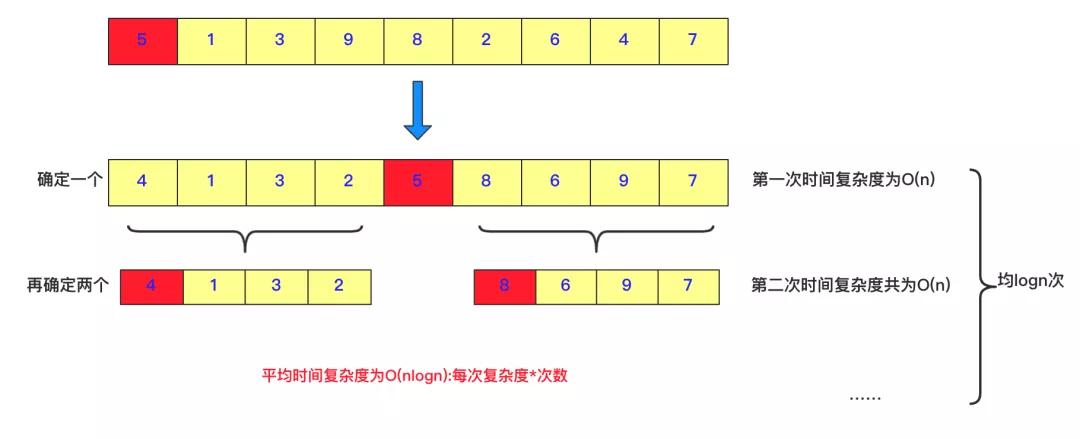
但是这个和求TopK有什么关系呢?
我们求TopK,其实就是求比目标数字大的K个,我们随机选一个数字例如上面的5,5的左侧有4个,右侧有4个,可能会出现下面几种情况了:
① 如果k-1等于5右侧数量,那么说明中间这个5就是第K个,它和它的右侧都是TopK。
②如果k-1小于5右侧数的数量 ,那么说明TopK全在5的右侧,那么可以直接压缩空间成右侧继续递归调用同样方法查找。
③ 如果k-1大于5右侧的数量,那么说明右侧和5全部在TopK中,然后左侧还有(k-包括5右侧数总数),此时搜查范围压缩,k也压缩。举个例子,如果k=7 那么5和5右侧已经占了5个数字一定在Top7中,我们只需要在5左侧找到Top2就行啦。
这样一来每次数值都会被压缩,这里因为快排不是完全递归,时间复杂度不是O(nlogn)而是O(n)级别(详细的可以找一些网上证明),但是测试样例有些极端代码比如给你跟你有序1 2 3 4 5 6…… 找TOP1 就出现比较极端的情况。所以具体时候会用一个随机数和第一个交换一下防止特殊样例(仅仅为了刷题用的),当然我这里为了就不加随机交换的啦,并且如果这里要得到的TopK是未排序的。
详细逻辑可以看下实现代码为:
- class Solution {
- public int findKthLargest(int[] nums, int k) {
- quickSort(nums,0,nums.length-1,k);
- return nums[nums.length-k];
- }
- private void quickSort(int[] nums,int start,int end,int k) {
- if(start>end)
- return;
- int left=start;
- int right=end;
- int number=nums[start];
- while (left<right){
- while (number<=nums[right]&&left<right){
- right--;
- }
- nums[left]=nums[right];
- while (number>=nums[left]&&left<right){
- left++;
- }
- nums[right]=nums[left];
- }
- nums[left]=number;
- int num=end-left+1;
- if(num==k)//找到k就终止
- return;
- if(num>k){
- quickSort(nums,left+1,end,k);
- }else {
- quickSort(nums,start,left-1,k-num);
- }
- }
- }
计数排序番外篇
排序总有一些骚操作的排序—线性排序,那么你可能会问桶类排序可以嘛?
也可以啦,不过要看数值范围进行优化,桶类排序适合数据均匀密集出现次数比较多的情况,而计数排序更是希望数值能够小一点。
那么利用桶类排序的具体核心思想是怎么样的呢?
先用计数排序统计各个数字出现次数,然后将新开一个数组从后往前叠加求和计算。
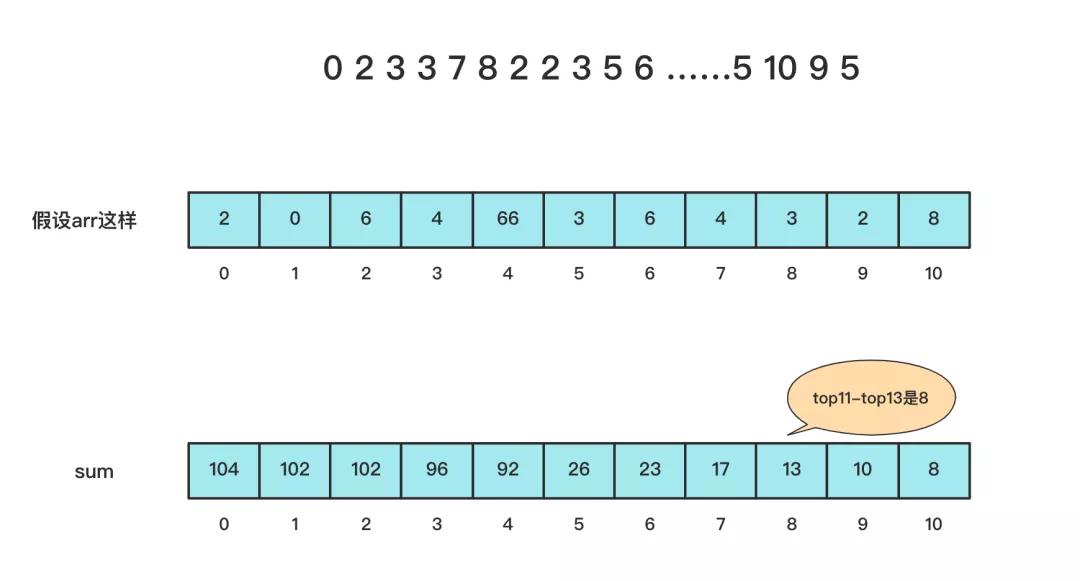
这种情况非常适合数值巨量并且分布范围不大的情况。
代码本来不想写了,但是念在你会给我三连我写一下吧
- //力扣215
- //1 <= k <= nums.length <= 104
- //-104 <= nums[i] <= 104
- public int findKthLargest(int nums[],int k)
- {
- int arr[]=new int[20001];
- int sum[]=new int[20001];
- for(int num:nums){
- arr[num+10000]++;
- }
- for(int i=20000-1;i>=0;i--){
- sum[i]+=sum[i+1]+arr[i];
- if(sum[i]>=k)
- return i-10000;
- }
- return 0;
- }
结语
好啦,今天的TopK问题就到这里啦,相信你下次遇到肯定会拿捏它。
TopK问题不难,就是巧妙利用排序而已。排序是非常重要的,面试会非常高频。
这里我就不藏着掖着摊牌了,以面试官的角度会怎么引导你说TOPK问题。
狡猾的面试官:
嗯,我们来聊聊数据结构与算法,来讲讲排序吧,你应该接触过吧?讲出你最熟悉的三种排序方式,并讲解一下其中具体算法方式。
卑微的我:
bia la bia la bia la bia la……