本文转载自微信公众号「开发内功修炼」,作者张彦飞allen。转载本文请联系开发内功修炼公众号。
大家好,我是飞哥!在互联网时代里,我觉得网络是最重要的一门技术了。但是我觉得从国内计算机系的学生,到已经工作了的工程师,在网络的学习上整体存在两个问题。
第一个是对实践的重视程度不够。这个问题在大学计算机课程中尤为突出。但这也不只是在学生群体中存在,很多工作了的工程师也是。在学习一个新技术的时候止步于眼睛看完就拉到,不想着去动手写一写,做测试跑一跑验证一下。
第二是对实现的重视程度不够。大部分的人都愿意把精力放在自己代码能波及的范围内。盲目相信工程中的黑盒依赖,把底层当成黑盒来使用,不愿意花功夫去了解一点底层实现,这是对于成长非常不利的。拿汽车来举例,我们工程师更应该是知晓汽车各项参数的优秀赛车手,而不是靠车谋生的出租司机。
今天我就这两点我就结合咱们内功修炼技术文章的创作过程,来分别展开了和大家聊聊~
一、对实践的重视程度不够
对于大部分应用场景来说,计算机科学与技术这个专业在技术的占比是远远要高于科学占比的,也就是说它的技术属性更多。对于一门技术来讲,动手就是非常非常重要的。
而我们国内的教学模式太过于偏重理论了,所以很多人都会觉得网络技术这门课太抽象了。这不是学生的问题,而是教育方法的缺陷。你应该也没听说过有哪门技术是光看书就能看会的。
根据美国学者艾德加·戴尔1946年发现的金字塔学习理论,见下图。传统的理论性的学习如听讲和阅读对知识的吸收率只有 10% 左右,而动手实践对知识的吸收率能达到 75% 以上。从效率上来讲,通过实践的方式进行学习的效率对理论学习的 7 -8 倍。

我觉得正确的学习方法应该是边学理论边动手实践。动手包括两类方法,一类是用一些命令行工具进行观测,另外一类就是写程序验证。
如果你是一位计算机系学生,我建议首先要准备一台 Linux 电脑(工程师就不用说了,应该大部分都用上 Linux 了)。在 Linux 下有很多成熟的网络相关的工具可供你使用。现在国内的互联网公司的服务器基本上也都是 Linux。而且用 Linux 有个好处就是源码是公开的。实在遇到不懂的问题,可以更容易地搜答案。这点比 Windows 强太多了。
对于第一类动手观测法,我的建议是你学到某一层的时候,就找到一些相关的工具来做几个实验。比如你可以启动一个 Nginx(或者干脆自己写一个 Server),用 curl 等工具发起 TCP 连接建立请求。这时候用 tcpdump 动手进行抓包,看看每次握手的时候,包体究竟是长什么样的。有资深工作经验的同学可以试试 systemtab、perf 等高级工具。
我把 linux 下的各种网络工具简单整理了一下,各位有需要可以把这张图保存下来。
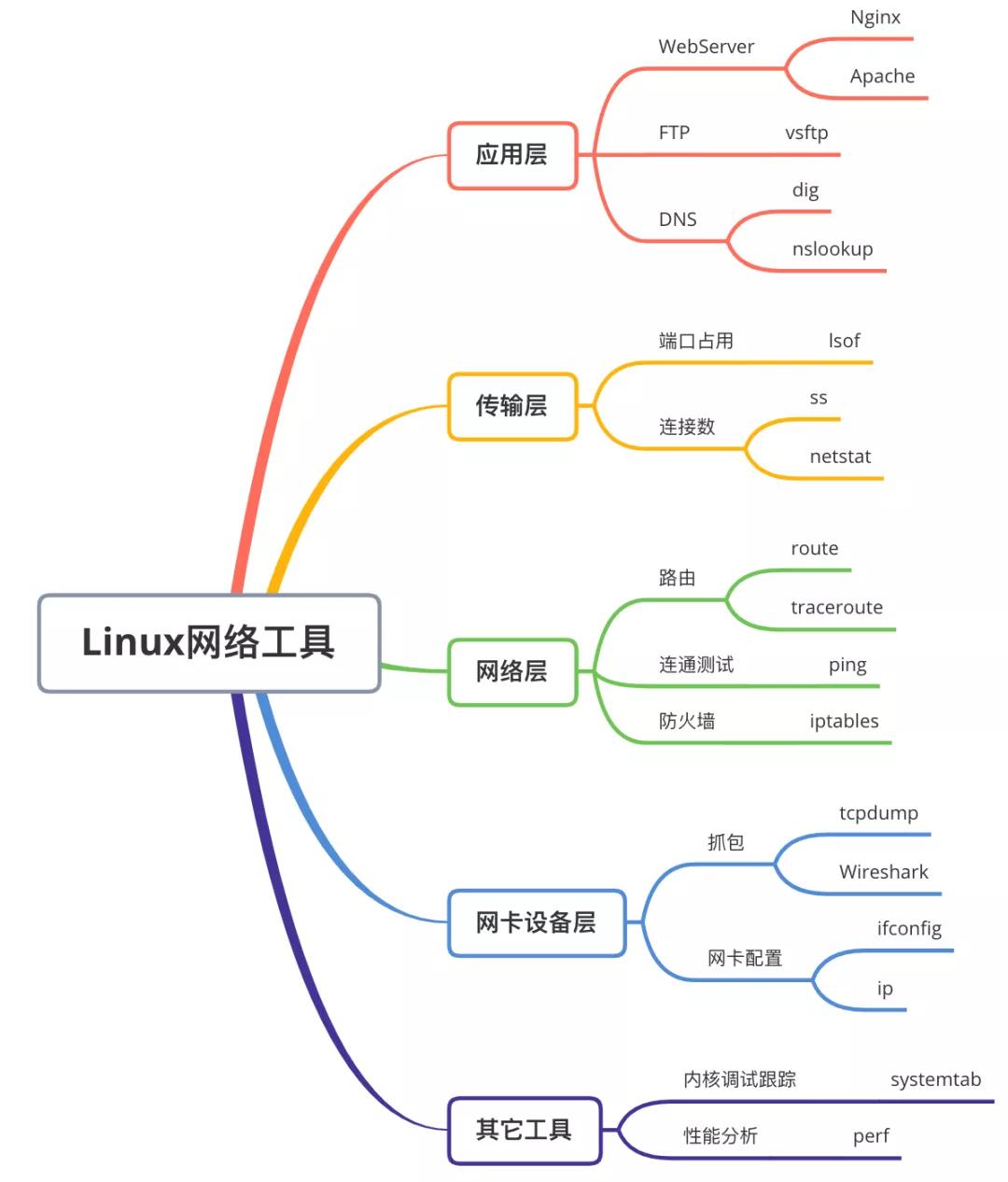
值得多提一下的是 systemtab 这个工具,他能够跟踪内核中的函数并打印一些调试信息。可以获取内核函数里的变量值,也可以打印调用堆栈。不过需要安装对应版本的内核调试包。
另外一个工具就是 perf,它可以统计和跟踪内核活动。通过 perf list 可以查看当前系统支持的所有性能事件、检查点。
第二类方法就是动手编程。对于学生来说,刚开始可以从一些简单的开始,比如就写个 tcp server, tcp client 让他们相互连接然后传输一些简单的数据。然后可以开始练一些更为复杂一点的。比如写一套 FTP Server 和 Client, 让它们之间能够实现简单的文件下载。或者写一个 Web Server,支持通过浏览器来下载 Web Server 上的静态文件。
或者参考 Libevent、Redis、Sogou WorkFlow 等项目包封装一个简单的网络库出来。再比如说模拟 tcpdump 来写一个抓包工具。(可以参考我的这篇文章,里面提供了一个简单的 demo)。
对于工程师来说也是一样。新学到一个的技术方案的时候,要尽量多动手去测试一下,验证验证。比如对于零拷贝来说,如果不使用零拷贝的话,单纯的使用 read 文件 + write 发送的方式和直接使用 sendfile 的方法比起来性能大概是差多少,能不能得出一些真实数据上的结论。
比如使用裸 epoll 的 QPS 数据最高能到多少, Golang 中的 net 包对 epoll 使用协程封装一次后能达到多少,完全不使用 epoll 的同步阻塞网络 IO 性能数据几何。
如果你经过实践测试验证之后,你对性能的理解会得到质的提升。对于我个人来讲,我也是一直通过理论 + 实践的方法来对知识进行学习的,效果真的不错。
比如我在网络中,我想弄懂一条空的 TCP 连接消耗多大的内存。我自己在工作之余抽了好长时间去翻内核源码,然后动手做实验。当实验完成的时候,我对 TCP 连接的内存开销的理解就非常的深了。
漫画 | 花了七天时间测试,我彻底搞明白了 TCP 的这些内存开销!
我一直想弄清楚一台服务器在实际中最大能支撑多少条 TCP 连接,我也是通过动手实验的方法来学习的,当时我前前后后至少花了半个多月。参见:
漫画 | 一台Linux服务器最多能支撑多少个TCP连接
漫画 | 理解了TCP连接的实现以后,客户端的并发也爆发了!
如果你也想玩玩,直接用我这篇文章里提供的源码就好。
百看不如一练,动手测试单机百万连接的保姆级教程!
在比如在内存和硬盘的性能上,我也是通过理论 + 实测的方法来深度理解的。
机械硬盘随机IO慢的超乎你的想象
实际测试内存在顺序IO和随机IO时的访问延时差异
如果你能能坚持通过动手加实践的方法来学习,相信你的技术水平一定会远远超过其他的同学。
二、对实现的重视程度不够
翻开任何一本计算机网络相关的教材大部分都是在讲协议(首先声明一下,我不反对理解这些基础的协议是挺重要的),那么协议具体是咋实现的,讲这些的貌似很少。
我们的日常开发都是基于操作系统在协议的实现基础上来进行工作的。对实现理解不到位会导致很多线上问题或者是性能优化都无从下手。虽然市场上也有一些内核实现相关的资料,但是又太难啃不动。
比如大家都知道服务器先 listen 一下,然后才能 accpet 接收连接请求。但是,到底为啥要先 listen ,似乎没有人和我们说过。不理解这个的话,就对全连接队列半连接队列理解不深,遇到问题就不好处理。
再比如说,现在的互联网大部分都是通过 TCP 连接来工作的,那么一台机器最多能撑多少个 TCP 连接?按道理说,整个业界都在讲高并发,这应该算是很入门的一个问题了。但当年我产生这个疑问的时候,却在 Google 上搜了个遍也没找到令我满意的答案。
再比如一个网络包是如何从网卡到达你的进程里的? 这个问题表面上看起来简单,但事实上很多性能优化方案都和这个接收过程有关,能不能深度理解这个过程决定了你在网络性能上有多少的优化措施可用。例如多队列网卡的优化方案是在硬中断这一步开始将工作分散在多个 CPU 核上,进而提升性能的。我几年前想把这个问题彻底搞搞清楚,搜遍了互联网,翻遍了各种经典书都没能找到想要的答案。
还比如为啥 TCP 握手耗时过长,一条 TCP 连接会消耗多大的内存。同步阻塞网络 IO 为啥就性能慢了,为啥 epoll 用上了以后就要性能高很多。这些和工程实践相关的问题光知道网络协议理论是任何用都没有的,都是应该建立在对网络实现的深刻理解上才能更好地应对。
针对这个问题,我在实现层面把网络都扒了一遍,成果都通过咱们开发内功修炼公众号发表。
例如,为什么服务端程序都需要先 listen 一下?事实上是因为服务器在接收客户端连接之前,提前准备了半连接和全连接两个队列。一个用于保存第一次握手请求,另一个用于保存第三次握手。客户端呢是在 connect 发起前,在内核里选择好端口号的。