












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
继GauGAN2之后,英伟达推出了一个GAN的“超级缝合体”——PoE GAN。
PoE GAN可以接受多种模态的输入,文字描述、图像分割、草图、风格都可以转化为图片。

而且它可以同时接受以上几种输入模态的任意两种组合,这便是PoE的含义。

所谓PoE是Hinton在2002年提出的“专家乘积”(product of experts)概念,每个专家(单独模型)被定义为输入空间上的一个概率模型。
而每种单独的输入模态都是合成图像必须满足的约束条件,因此满足所有约束的一组图像是满足每个约束集合的交集。

假设每种约束的联合条件概率分布都服从高斯分布,就用单条件概率分布的乘积来表述交集的分布。
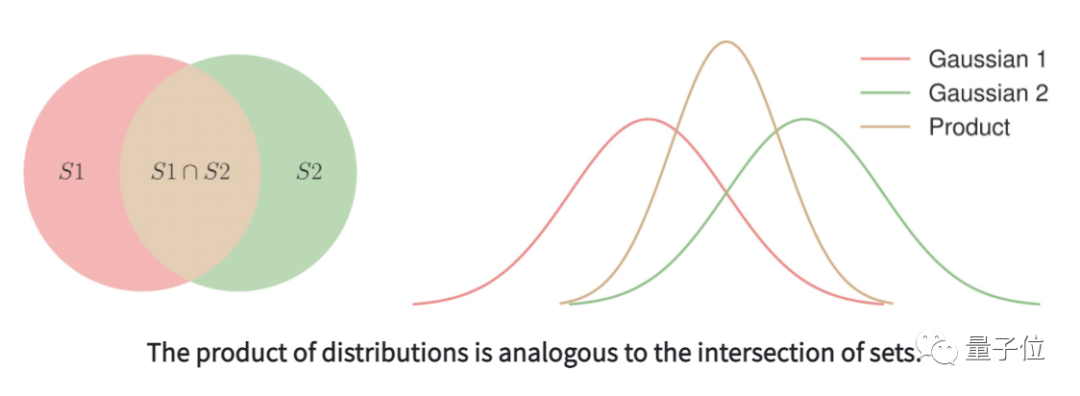
在此条件下,为了使乘积分布在一个区域具有高密度,每个单独的分布需要在该区域具有高密度,从而满足每个约束。
而PoE GAN的重点是如何将每种输入混合在一起。
PoE GAN的设计
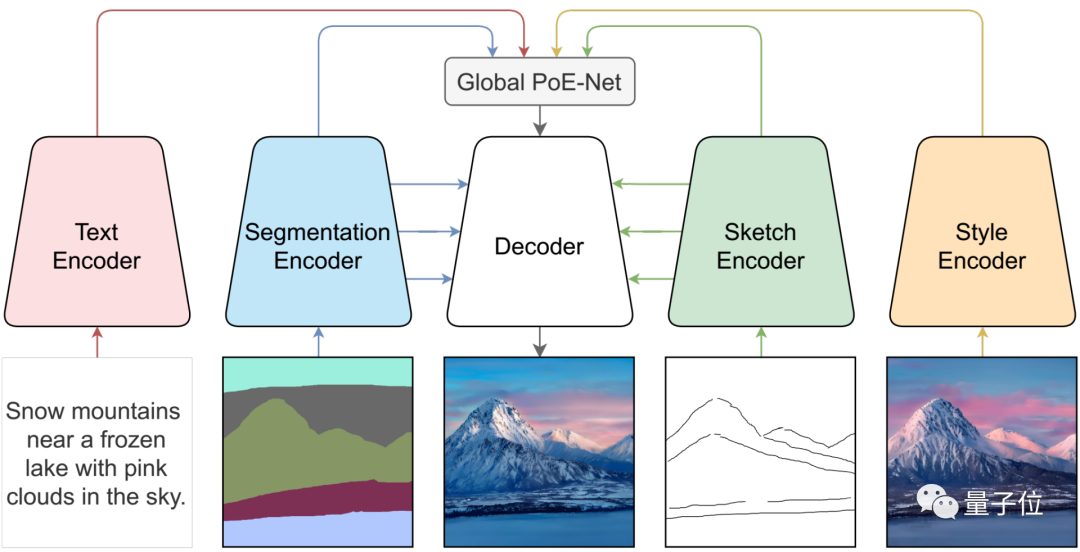
PoE GAN的生成器使用全局PoE-Net将不同类型输入的变化混合起来。
我们将每个模态输入编码为特征向量,然后使用PoE汇总到全局PoE-Net中。解码器不仅使用全局PoE-Net的输出,还直接连接分割和草图编码器,以此来输出图像。
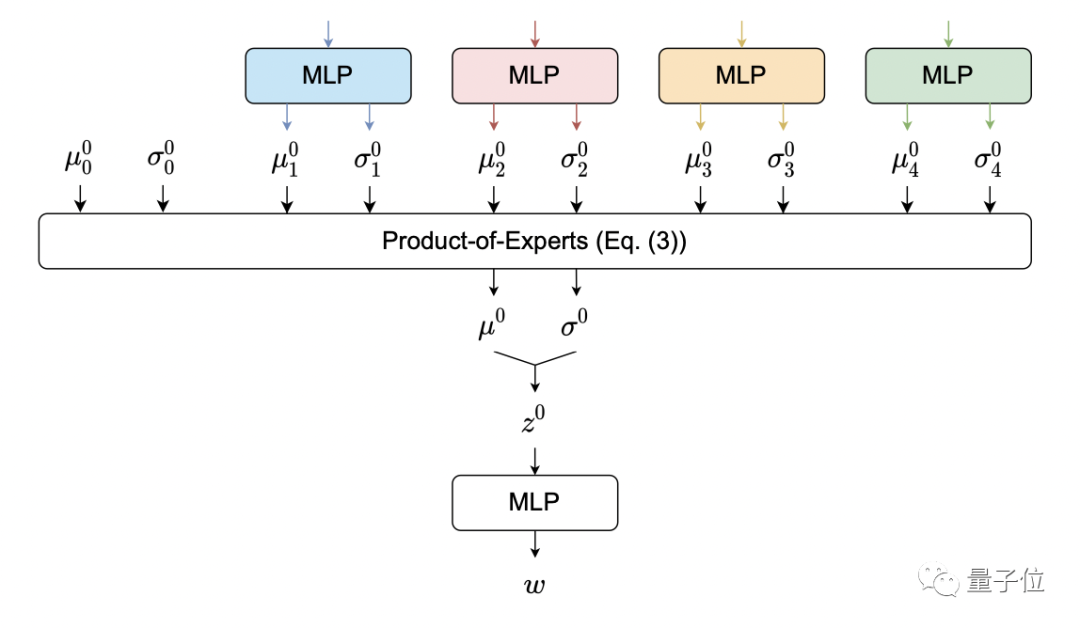
全局PoE-Net的结构如下,这里使用一个潜在的特征矢量z0作为样本使用PoE,然后由MLP处理以输出特征向量w。
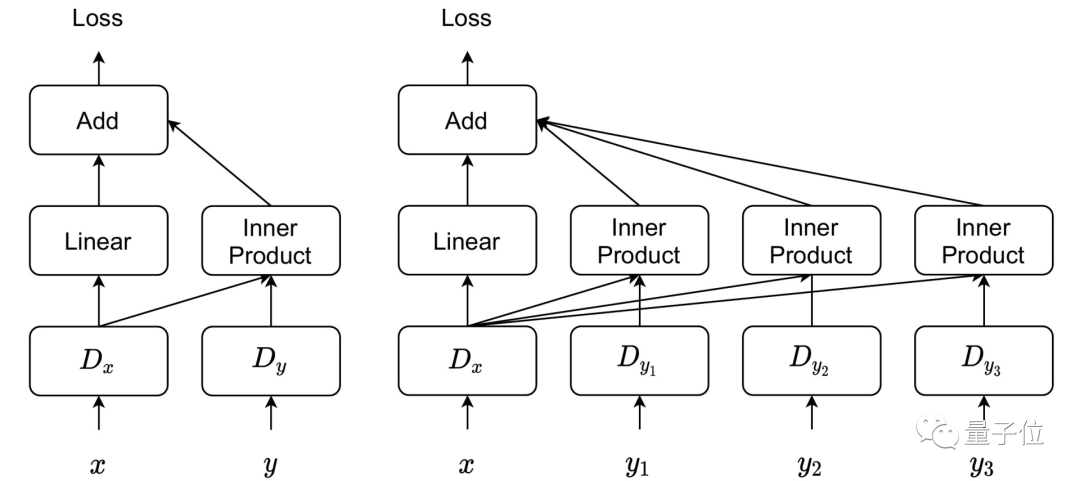
在鉴别器部分,作者提出了一种多模态投影鉴别器,将投影鉴别器推广到处理多个条件输入。
与计算图像嵌入和条件嵌入之间单个内积的标准投影鉴别器不同,这里要计算每个输入模态的内积,并将其相加以获得最终损失。
随意变换输入的GAN
PoE可以在单模态输入、多模态输入甚至无输入时生成图片。
当使用单个输入模态进行测试时,PoE-GAN的表现优于之前专门为该模态设计的SOTA方法。
例如在分割输入模态中,PoE-GAN优于此前的SPADE和OASIS。

在文本输入模态中,PoE-GAN优于文本到图像模型DF-GAN、DM-GAN+CL。

当以模式的任意子集为条件时,PoE-GAN可以生成不同的输出图像。下面展示了PoE-GAN的随机样本,条件是两种模式(文本+分割、文本+草图、分割+草图)在景观图像数据集上。

PoE-GAN甚至还能没有输入,此时PoE-GAN就会成为一个无条件的生成模型。以下是PoE-GAN无条件生成的样本。

团队介绍
论文通讯作者是英伟达著名工程师刘洺堉,他的研究重点是深度生成模型及其应用。英伟达Canvas和GauGAN等有趣的产品均出自他手。
论文一作是黄勋,北京航空航天大学本科毕业,康奈尔大学博士,现在在英伟达工作。
论文地址:
https://arxiv.org/abs/2112.05130
PoE:
https://www.cs.toronto.edu/~hinton/absps/icann-99.pdf
投影鉴别器:
https://arxiv.org/abs/1802.05637


























