【51CTO.com快译】如今,企业比以往任何时候都更加依赖数据。根据Gartner的最新数据质量市场调查,那些糟糕的数据质量,每年平均会给企业造成1500万美元的巨大损失。而且错误的数据往往会让企业失去商机、损毁市场声誉、拉低客户信心、甚至造成重大的财务损失。毋庸置疑,只有准确、一致、完整且可靠的数据,才能真正为业务提供实际、有利的价值。为此,许多企业往往会使用数据质量的相关工具。在本文中,我们将和您讨论如下五种数据质量类工具:
- Great Expectations
- Spectacles
- Datafold
- dbt(数据构建工具)
- Evidently
在深入探讨工具之前,让我们首先了解一下保障数据质量的相关概念。
数据问题从何而来?
从广义上讲,内、外部因素都会导致数据出现质量问题。其中,外部因素是指企业从诸如Meta、Google Analytics或AWS Data Exchange等,无法控制的第三方获取数据。例如,不同公司的IT系统可能在合并或收购之后,需要进行数据整合。但是,由于未能审核这些来自第三方的数据质量,或是因为应用程序中的输入验证不当,则可能导致数据质量出现问题。
而内部原因则源于企业生态系统的内部。例如,我们常听说的企业数据孤岛,就是一些鲜为人知的数据源。它们仅由组织内的某些团队或部门所使用。此外,缺乏适当的数据所有权管理,使用错误的数据类型和模型,甚至是软件工程师在应用程序的任何层更改字段、或引入破坏数据的代码更新,都可能导致数据质量的不佳和不一致。
衡量数据质量
数据在企业中的质量与价值,很大程度上取决于该企业如何定义它们,以及如何确定它们的优先级。通常,我们有七个实用的质量衡量指标。
- 相关性:数据与业务的相关程度。
- 准确性:数据的精准程度。
- 完整性:数据是否完整,是否处于稳定状态。
- 一致性:数据在整个组织中的是否能保持一致。如果使用同一个应用程序,去转换多个来源的同一条数据,其输出应当始终相同。
- 合规性:数据是否符合业务规则所期望的标准和格式。
- 唯一性:相同数据的多个副本是否在企业中都可用,而且它是否来自唯一的真实数据源。
- 及时性:数据对于当前业务需求的及时性。
确保数据质量
如前所述,企业通常使用一些自动化工具,来检查数据的质量。这些工具既可以是定制开发的,也可以是由供应商直接提供的。这两种选择各有利弊。
如果拥有充沛的IT资源,并且明确地定义了数据质量的要求,那么企业可以考虑采用定制化的开发方案,通过推出适合自己的工具,去减少持续的成本支出。当然,构建自定义方案也可能比较耗时,而且容易超过最初的预算。
而如果公司需要快速、可靠的方案,且不想自行维护的话,那么购买现成的方案则是最好的选择。说到这里,下面让我们来讨论五种典型的数据质量工具。当然,市场上还有许多其他相似的工具。您可以选择混合搭配的方式,来满足自己的预算和真实使用场景。
1.Great Expectations
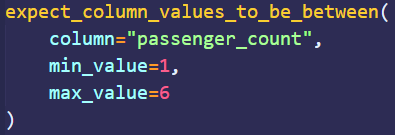
作为一个开源库,Great Expectations可用于验证、记录和分析数据。用户以期望(expectations)的形式定义断言(assertions)。顾名思义,期望是您期望从数据中获得的质量;断言则是用声明性语言编写的。例如,下图的断言示例定义了passenger_count列的值必须介于1和6之间。
Great Expectations的另一个功能是自动化数据分析。它可以根据统计数据,自动从数据中生成期望。由于数据质量工程师不必从头开始编写断言,因此大幅节省了开发的时间。
一旦各种预期准备就绪,它们就可以被合并到数据管道中。例如,在Apache Airflow中,数据验证步骤可以被定义为一个使用BashOperator的checkpoint script。它会在数据流经管道时,触发相应的质量检查。目前,Great Expectations兼容大部分数据源,其中包括CSV文件、SQL数据库、Spark DataFrames和Pandas等。
2.Spectacles
Spectacles是一种持续集成(CI)类工具,旨在验证项目中LookML。此处的LookML是Looker类型的数据建模语言。而Looker是一个BI(业务智能)平台,它允许那些不懂SQL的人员去分析和可视化数据。
Spectacles通过在后台运行SQL查询,并检查错误,来验证LookML。它能够与GitHub、GitLab和Azure DevOps相集成。该工具适用手动调用、从拉取请求中触发,以及作为ETL作业的一部分运行等,几乎任何类型的部署模式。而将Spectacles作为CI/CD工作流的一部分,意味着它能够在将代码部署到生产环境之前,自动验证LookML的相关查询。
3.Datafold
作为一个主动式的数据质量平台,Datafold由数据差异(Data Diff)、具有列级沿袭(lineage)的数据目录(Data Catalog)、以及数据监控(Data Monitoring),三个主要组件所构成。
Data Diff允许您在合并到生产环境之前,对两个数据集(例如dev和prod)进行比较。这有助于用户采用更为主动的开发策略。它也可以被集成到团队的CI/CD管道中,以便共享GitHub或GitLab中的代码更改,并显示出具体的差异。
我们来看一个例子,Datafold的沙箱环境中自带有一个taxi_trips的数据集。如下图所示,我们在数据集datadiff-demo.public.taxi_trips和datadiff-demo.dev.taxi_trips之间运行了Data Diff操作。
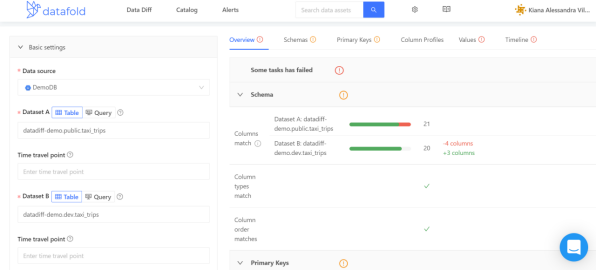
那么在右侧带有详细信息的面板上,您将可以选择不同的选项卡,以获得针对结果的不同视角。其中,“Overview”选项卡将包含成功和失败测试的概要。
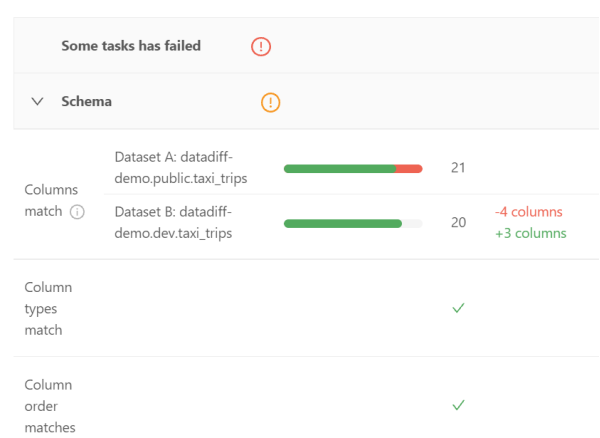
其Schema部分展示了两个数据集的列(包括数据类型,以及出现的顺序)是否相匹配。
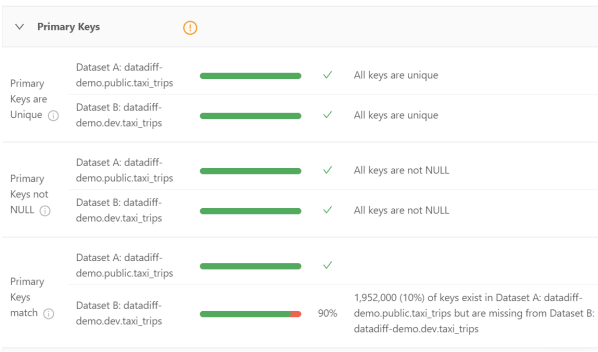
其Primary Keys部分显示了主键的唯一性、非NULL、以及和两个数据集之间匹配的百分比。
尽管Overview选项卡已经充分展示了各种信息来源,但是其他选项卡也能提供更多实用的详细信息。例如,Schemas选项卡就包含了如下方面:
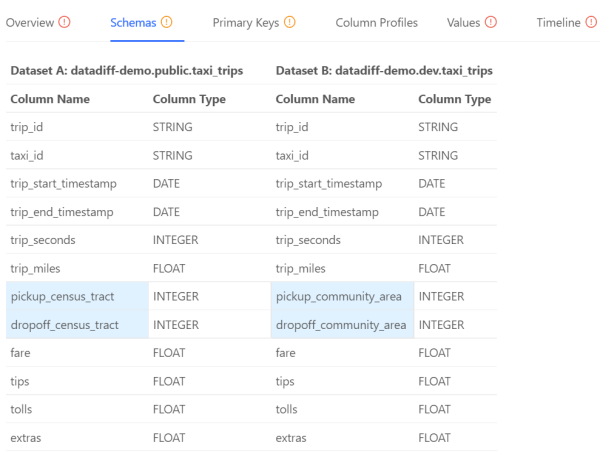
上图突出显示了具有两个不同数据集的列。据此,数据工程师可以仅专注于这两个领域的内容,而节省宝贵的时间。
Data Catalog不但能够列出所有注册到Datafold的数据源,而且允许用户使用过滤器,去查找和分析任何特定的数据集。对于拥有数百个、甚至是数千个数据集的组织来说,这无疑会大幅节省时间。作为一种发现异常的实用方法,它能够针对数据沿袭(data lineage)功能,协助“回答”如下问题:
- 这个值从何而来?
- 这个值如何影响其他表?
- 这些表是如何关联的?
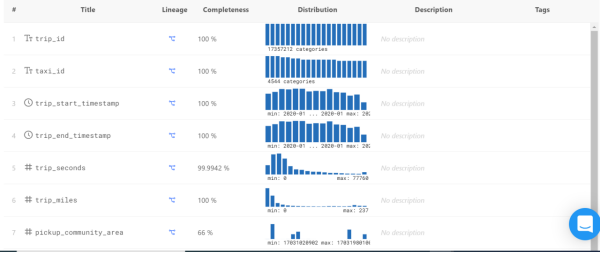
Data Catalog提供了如下仪表板。通过滚动鼠标,您可以看到每一列的详细信息,其中包括:
- 完整性(Completeness)-- 不为NULL值的百分比。
- 分布(Distribution)-- 显示了出现得最多与最少的值,以及偏向某个范围的值。
单击Lineage下的图标,您会看到如下内容:
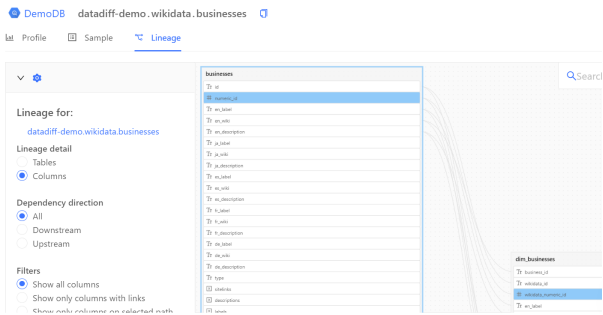
图形沿袭图(graphical lineage diagram)可以协助数据工程师快速找到列值的来源。您可以检查表、所有(或特定)列、以及与上下游有关的各种沿袭。
Datafold的Data Monitoring功能允许数据工程师通过编写SQL命令,来查找异常,并创建自动警报。这些警报由机器学习提供支持。而机器学习通过研究数据的趋势和周期性,能够准确地发现某些异常情况。下图显示了此类查询:
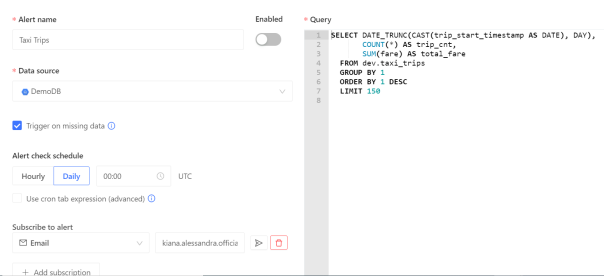
该查询是由Datafold自动生成的。它跟踪了出租车数据集中的每日总车费,以及总行程的趟数。
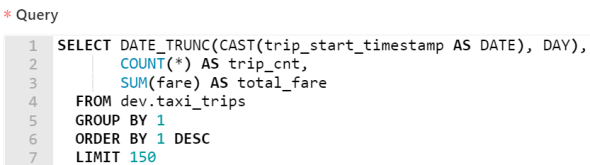
如下图所示,Datafold还允许用户去检查异常跟随时间变化的趋势。其中,黄点表示相对于最小和最大值的各种异常。
4.Dbt
Dbt是一个数据转换类工作流工具。它在部署之前,能够针对目标数据库执行数据转换的代码,显示代码将如何影响数据,并突出显示各种潜在的问题。也就是说,Dbt通过运行SELECT语句,以基于转换的逻辑,去构建数据的结束状态。
Dbt不但容易被集成到现代化的BI栈中,并且可以成为CI/CD管道的重要组成部分。它既可以根据拉取请求或按计划自动运行,又具有自动化回滚的功能,可以阻止在部署过程中,具有潜在破坏性的代码更改。
值得一提的是,Datafold和Dbt可以一起用于自动化的数据质量测试。与Dbt类似,Datafold也可以被集成到CI/CD管道中。在协同使用时,它们会显示目标代码是如何影响数据的。
5.Evidently
作为一个开源的Python库,Evidently用于分析和监控机器学习的模型。它能够基于Panda DataFrames和CSV文件生成交互式的报告,可用于对模型进行故障排除和数据完整性检查。这些报告会显示模型的运行状况、数据漂移、目标漂移、数据完整性、特征分析、以及分段性能等指标。
为了了解Evidently的具体功能,您可以在Google Colab上打开一个新的笔记本,然后复制如下代码段:
- wine = datasets.load_wine()
- wine_frame = pd.DataFrame(wine.data, columns = wine.feature_names)
- number_of_rows = len(wine_frame)
- wine_data_drift_report = Dashboard(tabs=[DataDriftTab])
- wine_data_drift_report.calculate(wine_frame[:math.floor(number_of_rows/2)], wine_frame[math.floor(number_of_rows/2):], column_mapping = None)
- wine_data_drift_report.save("report_1.html")
该代码段会在浏览器中生成并加载报告。报告的仪表板概览界面,将显示基于每项功能的参考值与当前值的分布。

Evidently还可以进行更多近距离的检查。例如,下图显示了当前数据集和参考数据集不同的确切值。
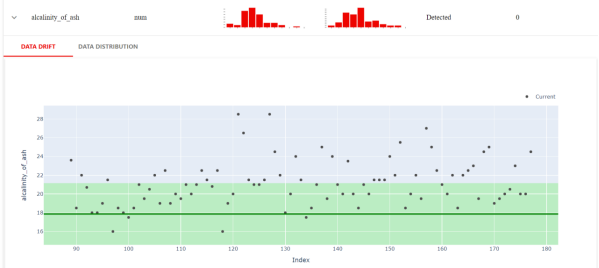
由此,我们可以进一步获悉数值目标漂移、分类目标漂移、回归模型性能、分类模型性能、以及概率分类模型等性能。
小结
随着数据质量标准和业务需求在不断发展,数据质量的保证已经成为了一个持续的过程。上文和您讨论的五种工具,通常可以被用于数据处理和使用的不同阶段。您也可以根据自身业务和数据使用的实际需求,或是单独采用,或是以不同的组合形式进行协同试用。
原文标题:Five Data Quality Tools You Should Know,作者:Michael Bogan
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】