大家好,我是明哥!
本篇文章,我们回顾一次 hbase 线上问题的分析和解决 - KeyValue size too large,总结下背后的知识点,并分享一下查看开源组件不同版本差异点的方法。
希望大家有所收获,谢谢大家!
01 Hbase 简介
Hbase 作为 hadoop database, 是一款开源,分布式易扩展,面向大数据场景的,多版本,非关系型,数据库管理系统,是 Google Bigtable 的 JAVA 版开源实现。
Hbase 的底层存储引擎是 HDFS,可以在普通商业级服务器硬件(即常说的 x86 架构的服务器)的基础上,提供对超大表(表的数据量可以有百万行,每行的列数可以有百万级)的随机实时读写访问。
Hbase具有以下特征:
- 模块化的线性扩展性;
- 强一致性并发读写支持;
- 可配置的表的自动 sharding;
- 表分区在 RegionServer 间的自动 failover;
- 基于 Block cache 和 Bloom 过滤器的实时读取;
- 基于 server 端过滤器的查询谓词下推;
正是因为 Hbase 的上述特征,Hbase 在各行各业有许多线上应用案列,可以说是 NoSql 数据库的一个典型代表:
- 在各种超大数据量级
- 在需要实时并发读写支持
- 在表的结构比较灵活(即有很多稀疏列:有很多行和很多列,但每一行只有众多列中的少数列有值)
- 笔者就在车联网场景下重度使用过 Hbase
题外话:
Nosql 数据库有几大类,几个典型代表是:Hbase, ElasticSearch, MongoDb;
有个有趣的现象,笔者发现国内 Hbase 使用的多,而国外似乎 Cassandra 使用的多。
02 一次线上 Hbase 问题的问题现象
某线上应用使用了 Hive 到 Hbase 的映射表,在使用 insert overwrite 从 hive 表查询数据并插入 HBASE 表时,发生了错误。
通过查看 HIVE 背后 YARN 上的作业的日志,发现主要错误信息是 java.lang.IllegalArgumentException: KeyValue size too large,详细报错截屏和日志如下:
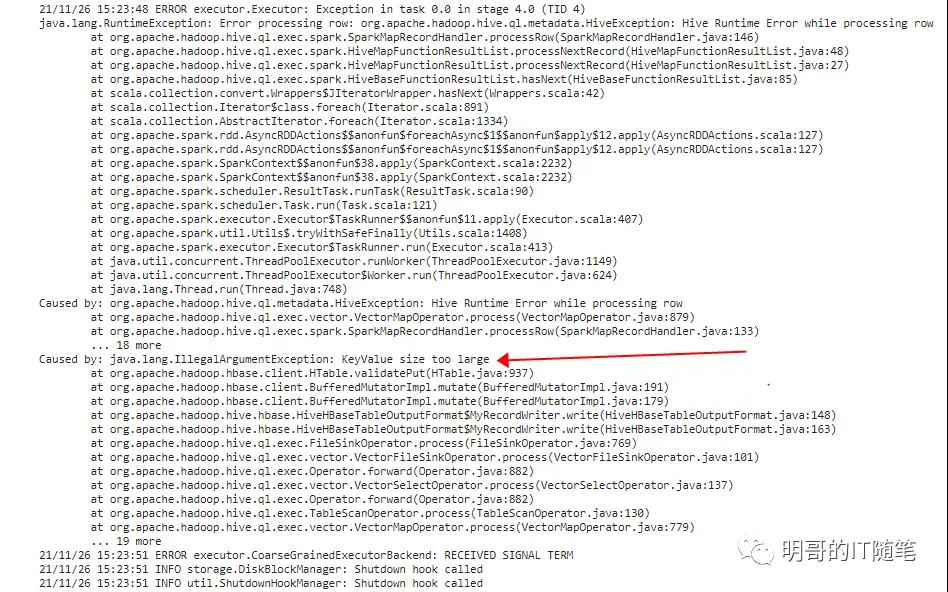
2020-04-08 09:34:38,120 ERROR [main] ExecReducer: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row (tag=0) {"key":{"_col0":"0","_col1":"","_col2":"2020-04-08","_col3":"joyshebaoBeiJing","_col4":"105","_col5":"北京,"},"value":null}
at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:253)
at org.apache.hadoop.mapred.ReduceTask.runOldReducer(ReduceTask.java:444)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:392)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: KeyValue size too large
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processOp(GroupByOperator.java:763)
at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.reduce(ExecReducer.java:244)
... 7 more
Caused by: java.lang.IllegalArgumentException: KeyValue size too large
at org.apache.hadoop.hbase.client.HTable.validatePut(HTable.java:1577)
at org.apache.hadoop.hbase.client.BufferedMutatorImpl.validatePut(BufferedMutatorImpl.java:158)
at org.apache.hadoop.hbase.client.BufferedMutatorImpl.mutate(BufferedMutatorImpl.java:133)
at org.apache.hadoop.hbase.client.BufferedMutatorImpl.mutate(BufferedMutatorImpl.java:119)
at org.apache.hadoop.hbase.client.HTable.put(HTable.java:1085)
at org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat$MyRecordWriter.write(HiveHBaseTableOutputFormat.java:146)
at org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat$MyRecordWriter.write(HiveHBaseTableOutputFormat.java:117)
at org.apache.hadoop.hive.ql.io.HivePassThroughRecordWriter.write(HivePassThroughRecordWriter.java:40)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.processOp(FileSinkOperator.java:717)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
at org.apache.hadoop.hive.ql.exec.SelectOperator.processOp(SelectOperator.java:84)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.forward(GroupByOperator.java:1007)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processAggr(GroupByOperator.java:818)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processKey(GroupByOperator.java:692)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processOp(GroupByOperator.java:758)
... 8 more
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
03 该线上 Hbase 问题的问题原因
其实以上作业的报错日志还是比较详细的:Caused by: java.lang.IllegalArgumentException: KeyValue size too large at org.apache.hadoop.hbase.client.HTable.validatePut(HTable.java:1577);
- 即报错详细信息是:KeyValue size too large;
- 报错来自 Hbase (而不是 HIVE)的类,从类名看是 hbase 客户端在对待插入数据校验时发现了错误:org.apache.hadoop.hbase.client.HTable.validatePut(HTable.java:1577);
熟悉 Hbase 的小伙伴(其实不熟悉 Hbase 的小伙伴,也能从报错信息和报错类上猜到一点点),从以上信息能够猜到,是 Hbase 对每条记录的 KyeValue 的大小做了限制,当实际插入的 KeyValue 的大小超过该大小限制阈值时,就会报上述错误。
什么是 KeyValue 呢?
- 这涉及到 Hbase 的存储结构,Hbase 内部是通过 KeyValue 结构来存储表数据的;
- 大致上大家可以认为:某个 KeyValue 对应的是 Hbase 大宽表中的某行的某列;
- 每个 KeyVlue 内部内容包含:rowKey+CF(ColumnFamily)+CQ(Column qualifier)+Timestamp+Value;
- 详细说明见官方文档,截图如下:

Hbase 为什么要限制每个 KeyValue 的大小呢?
- 究其原因,是因为 Hbase 需要在 hdfs 存储引擎(基于分磁盘)之上提供对数据实时读写的支持;
- Hbase 在内部数据读写时使用了 LSM 数据结构 (Log-Structured-Merge Tree),这背后涉及到了大量对内存的使用(读数据时使用 BlockCache,写数据时使用 memStore),也涉及到了内存数据的异步 flush 和 hfile 文件的异步 compaction;(当然为了容错,又涉及到了 wal Hlog);
- 因为涉及到基于内存提供对数据读写的支持,所以需要限制使用的内存的总大小,由于内存 BlockCache 中缓存的数据是以Block 为单位的,而Block内部存储的是一个个 KeyValue, 所以从细节来讲也需要限制每个 KeyValue的大小;
- 这里的 Block 是 Hbase的概念,不是 HDFS Block; (Hbase 每个 Block 的默认大小是 64KB, HDFS 每个BLOCK的默认大小一般是 128MB);
04 该线上 Hbase 问题的扩展知识-不同 Hbase 版本相关的参数
Hbase 作为一个流行的 Nosql数据库,推出十多年来,目前有多个经典版本:
- 0.98;-- 该版本比较老了,部分遗留线上应用还有使用该版本的;
- 1.2.x;(1.4.x) -- 1.2.x 和 1.4.x 都是1.x 系列下用的比较多的稳定版本
- 2.1.x(2.4.x) -- 2.1.x 和 2.4.x 都是2.x系列下用的比较多的稳定版本
- 3.0.0-alpha-1 -- 3.x 系列目前还不是稳定版
对应该 “KeyValue size too large” 问题,不同版本推出了不同的相关参数:
- 在hbase-1.4 以前的版本中,(包括hbase 1.2.0-cdh5.14.2 和 hbase 1.2.0-cdh5.16.2),只有一个客户端参数 hbase.client.keyvalue.maxsize;
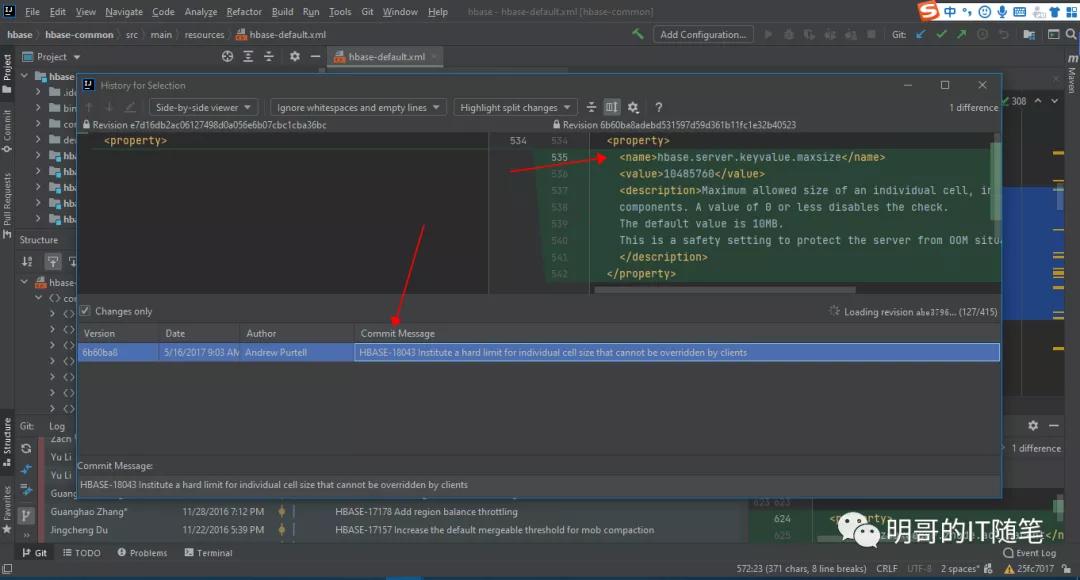
- 在 hbase-1.4 及以后版本中,除了该客户端参数 hbase.client.keyvalue.maxsize,还有一个服务端参数 hbase.server.keyvalue.maxsize;
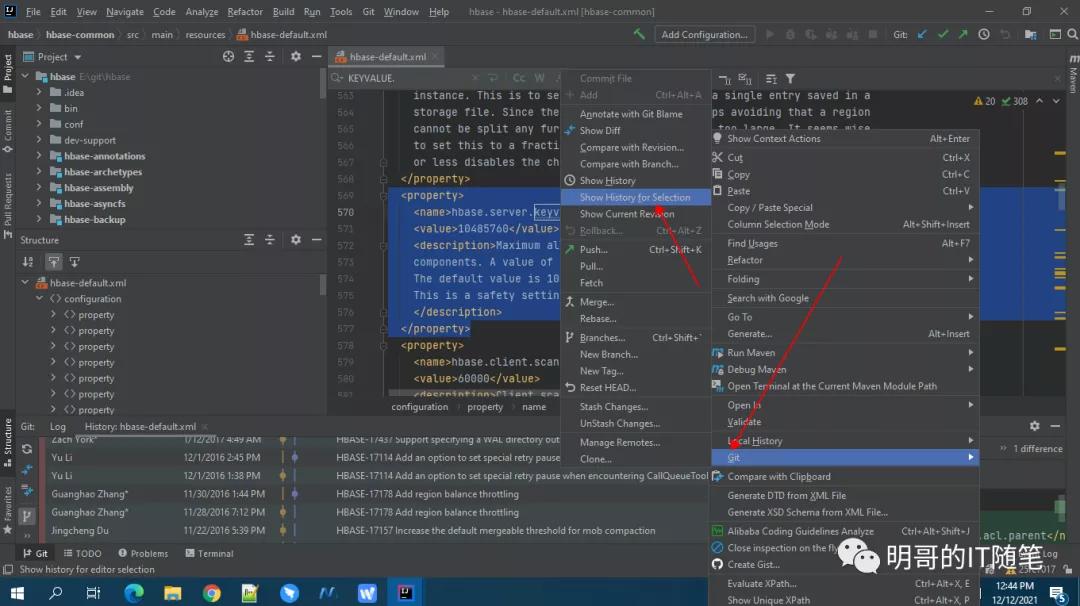
其实,由于笔者并没有持续跟进 HBASE 社区对 feautre 和 issue相关的讨论(大部分使用者可能都不会),所以也是在查阅不同版本的官方文档时留意到了上述细节,然后通过在本地 IDEA 中使用 git->show history 对比不同版本 HBASE 中 hbase-default.xml 的源码,进而确认到了JIRA记录号,并在JIRA中确认了这点:
正如该 JIRA 中描述:
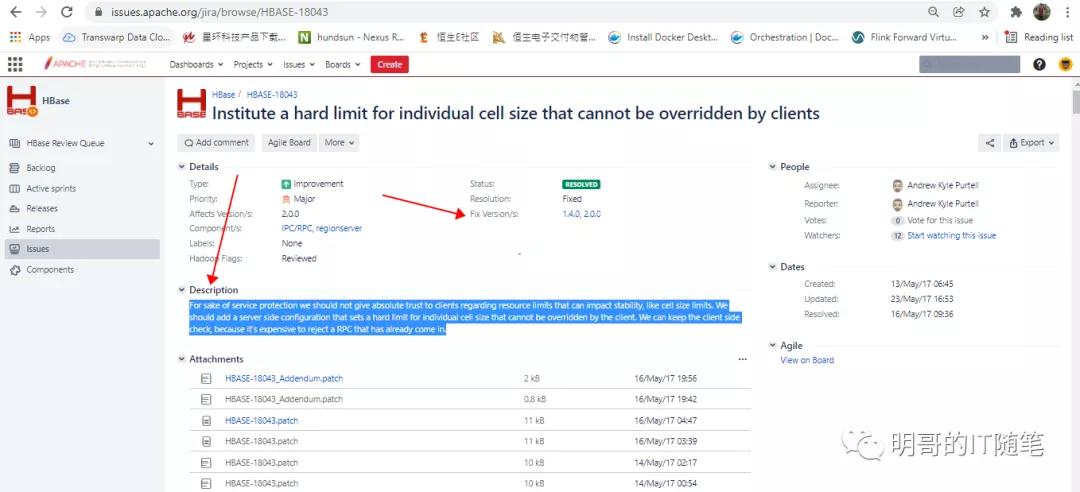
HBASE-18043:
For sake of service protection we should not give absolute trust to clients regarding resource limits that can impact stability, like cell size limits. We should add a server side configuration that sets a hard limit for individual cell size that cannot be overridden by the client. We can keep the client side check, because it's expensive to reject a RPC that has already come in.
所以,不同版本中遇到不同情况,可能会包的错误主要有两个:
- 情况1:Hbase KeyValue size too large
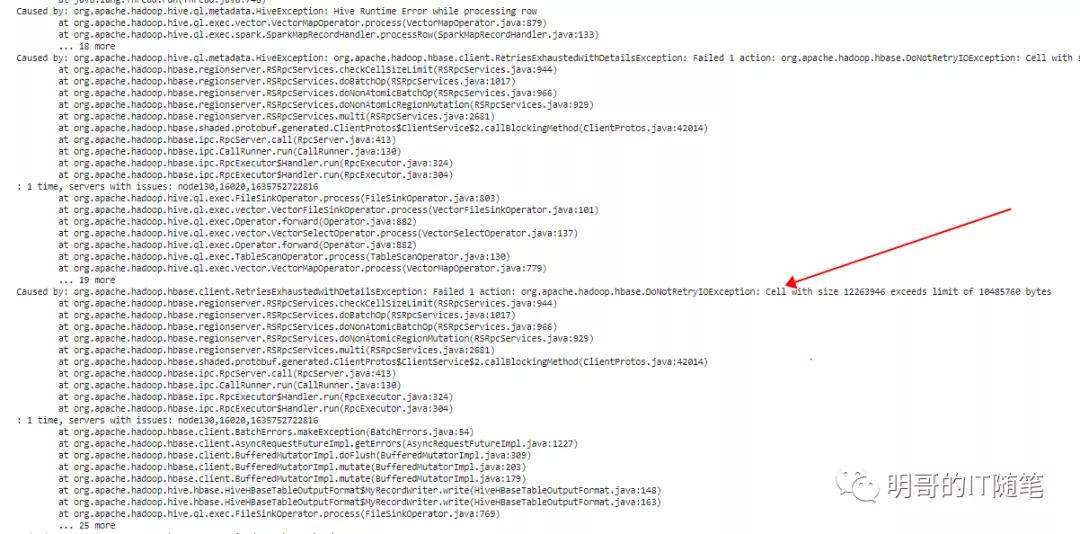
- 情况2:Cell with size 25000046 exceeds limit of 10485760 bytes
报错情况一和报错情况而,问题原因如下:
报错情况一:没有配置客户端参数 hbase.client.keyvalue.maxsize,且实际插入的 keyvalue 的大小超过了该客户端参数的默认大小限制;
报错情况二:程序设置调大了客户端参数 hbase.client.keyvalue.maxsize,但没有调大服务端参数 hbase.server.keyvalue.maxsize,且实际插入的 keyvalue 小于该客户端参数,但大于该服务端参数:
报错情况二,某次作业日志:
Exception in thread "main"org.apache.hadoop.hbase.DoNotRetryIOException:
org.apache.hadoop.hbase.DoNotRetryIOException: Cell with size 25000046 exceeds limit of 10485760 bytes at org.apache.hadoop.hbase.regionserver.RSRpcServices.checkCellSizeLimit(RSRpcServices.java:944)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.mutate(RSRpcServices.java:2792)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42000)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
报错情况二,某次报错截图:
05 该线上 Hbase 问题的解决方案
知道了问题原因,其实解决方法也就呼之欲出了,在确认要插入的业务数据没有异常,确实需要调大 keyvalue 限制的阈值时,大体总结下,有以下解决办法:
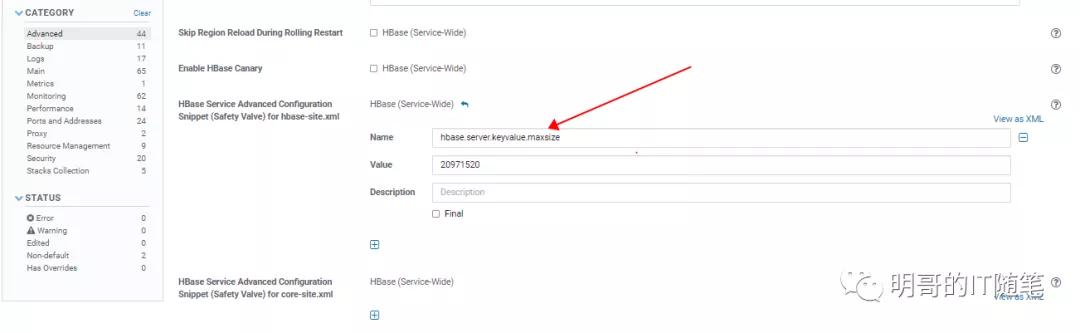
- 方法一:修改配置文件 hbase-site.xml, 调大客户端参数 hbase.client.keyvalue.maxsize 的值;
- 方法二:如果使用了 HBASE JAVA API, 可以修改代码使用 configuration 对象修改此客户端参数的默认配置:Configuration conf = HBaseConfiguration.create();
- conf.set("hbase.client.keyvalue.maxsize","20971520");
- 方法三:如果使用了 HIVE,可以在客户端覆盖该客户端参数:set hbase.client.keyvalue.maxsize=0; (hive sql中)
- 说明:一般该客户端参数和服务端参数,默认值应该配置一样;当更改服务端参数时,需要重启服务端才能生效;当更改客户端参数时,不同客户端设置的值可以不同,且不需要重启服务端;
- 在CDH中配置更改截图如下:
06 该线上 Hbase 问题的技术背景
- Hbase 内部是通过 KeyValue 结构来存储表数据的,某个 KeyValue 对应的是 Hbase 大宽表中的某行的某列,每个 KeyVlue 内部内容包含:rowKey+CF(ColumnFamily)+CQ(Column qualifier)+Timestamp+Value;
- hbase 在进行 PUT 操作的时候,会逐个检查要插入的每个列 (keyvalue cell) 的大小,当其大小大于 maxKeyValueSize 时,就会抛出异常,拒绝写入;
- maxKeyValueSize 大小相关的参数,在hbase-1.4 以前的版本中,(包括hbase 1.2.0-cdh5.14.2 和 hbase 1.2.0-cdh5.16.2),只有一个客户端参数 hbase.client.keyvalue.maxsize;
- maxKeyValueSize 大小相关的参数,在 hbase-1.4 及以后版本中,除了该客户端参数 hbase.client.keyvalue.maxsize,还有一个服务端参数 hbase.server.keyvalue.maxsize;
- Hbase 限制每个 KeyValue 大小的原因,主要在于:
- Hbase 需要在 hdfs 存储引擎(基于分磁盘)之上提供对数据实时读写的支持,因此 Hbase 在内部数据读写时使用了 LSM 数据结构 (Log-Structured-Merge Tree),这背后涉及到了大量对内存的使用(读数据时使用 BlockCache,写数据时使用 memStore),也涉及到了内存数据的异步 flush 和 hfile 文件的异步 compaction;(当然为了容错,又涉及到了 wal Hlog);
- 因为涉及到基于内存提供对数据读写的支持,所以需要限制使用的内存的总大小,由于内存 BlockCache 中缓存的数据是以Block 为单位的,而Block内部存储的是一个个 KeyValue, 所以从细节来讲也需要限制每个 KeyValue的大小;
- 这里的 Block 是 Hbase的概念,不是 HDFS Block; (Hbase 每个 Block 的默认大小是 64KB, HDFS 每个BLOCK的默认大小一般是 128MB);
- 该客户端参数 hbase.client.keyvalue.maxsize,和服务端参数hbase.server.keyvalue.maxsize,集群级别的默认配置推荐保持一致,且不推荐在集群级别配置这两个参数为0或更小(即禁用大小检查),因为此时可能会造成某个cell 存很大的数据比如 1G,此时集群性能就会大打折扣;
- 服务端参数只能在服务端进行配置,且配置后要重启服务端的 hbase, 其做用是 “This is a safety setting to protect the server from OOM situations.”;
- 客户端参数可以在服务端进行全局默认配置,也可以在客户端进行定制配置,不同客户端设置的值可以不同,但不能大于服务端的值,且客户端配置后不需要重启服务端,其含义是:一个KeyValue实例的最大size(一个KeyValue在io时是不能进一步分割的);
- 客户端参数,具体需要设置为多大,需要根据业务允许的最大keyValue是多少来进行配置,默认是10M,一般是以默认值10M为基础,如果有客户遇到以上报错,且实际的KEYVALUE也不是业务脏数据,就调大1倍到20MB看看;
- 在通过hive外表使用 HBaseStorageHandler 向 HBASE 写数据时,可以直接在beeline中更改配置客户端参数 (set hbase.client.keyvalue.maxsize=10485760),不需要重启hbase服务端;
- 在探究某个开源组件的某个类或配置文件,在不同版本的变化历史时,可以通过 git clone 在本地克隆创建 git repository,然后在本地 IDEA 中通过使用命令 git->show history 对比不同版本中类或配置文件的,进而确认到 JIRA 记录号,并在JIRA中确认相关细节;
- 更多关于hbase数据存储结构的细节:
- hbase 中的数据,可以有多个columnFamily, 每个 columnFamily 内部可以有多个column;
- 每个 ColumnsFamily 落地到hdfs上的文件是 hfile/storeFile, storeFile 是由 data block组成的(block 是IO和压缩的基本单位,默认64KB);(Within an HFile, HBase cells are stored in data blocks as a sequence of KeyValues;KeyValue instances are aggregated into blocks, which are indexed and Indexes also have to be stored; Blocksize is configurable on a per-ColumnFamily basis);
- 每个 block 内部存储了多个columns,每个column都是以 keyvalue 的形式存储的,每个keyvalue的大小受hbase.clent.keyvalue.maxsize/hbase.server.keyvalue.maxsize限制的;
- compression and DATA BLOCK ENCODING doesn't help with the cell size check, as compress and data block encoding happens when flush memstore to hfile and compaction of hfile;
- HBase supports several different compression algorithms which can be enabled on a ColumnFamily. Data block encoding attempts to limit duplication of information in keys, taking advantage of some of the fundamental designs and patterns of HBase, such as sorted row keys and the schema of a given table. Compressors reduce the size of large, opaque byte arrays in cells, and can significantly reduce the storage space needed to store uncompressed data.