













ArrayList是大家用的再熟悉不过的集合了,而此集合设计之初也是为了高效率,并未考虑多线程场景下,所以也就有了多线程下的CopyOnWriteArrayList这一集合。
回忆下ArrayList
集合的fail-fast机制和fail-safe机制:
- fail-fast快速失败机制,一个线程A在用迭代器遍历集合时,另个线程B这时对集合修改会导致A快速失败,抛出ConcurrentModificationException 异常。在java.util中的集合类都是快速失败的。
- fail-safe安全失败机制,遍历时不在原集合上,而是先复制一个集合,在拷贝的集合上进行遍历。在java.util.concurrent包下的容器类是安全失败的,建议在并发环境下使用这个包下的集合类。
ArrayList定义:
- public class ArrayList extends AbstractList
- implements List, RandomAccess, Cloneable, java.io.Serializable { }
ArrayList简介:
- ArrayList是实现List接口的可变数组,并允许null在内的重复元素
- 底层数组实现,扩容时将老数组元素拷贝到新数组中,每次扩容是其容量的1.5倍,操作代价高
- 采用了Fail-Fast机制,面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险
- ArrayList是线程不安全的,所以在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList
重点关注问题:
ArrayList默认大小(为什么是这个?),扩容机制?
ArrayList的默认初始化大小是10(在新建的时候还是空,只有当放入第一个元素的时候才会变成10),若知道ArrayList的大致容量,可以在初始化的时候指定大小,可以在适当程度减少扩容的性能消耗(看下一个问题解析)。
至于为何是10
据说是因为sun的程序员对一系列广泛使用的程序代码进行了调研,结果就是10这个长度的数组是最常用的最有效率的。也有说就是随便起的一个数字,8个12个都没什么区别,只是因为10这个数组比较的圆满而已。
ArrayList的扩容机制
当添加元素的时候数组是空的,则直接给一个10长度的数组。当需要长度的数组大于现在长度的数组的时候,通过新=旧+旧>>1(即新=1.5倍的旧)来扩容,当扩容的大小还是不够需要的长度的时候,则将数组大小直接置为需要的长度(这一点切记!)。
ArrayList特点访问速度块,为什么?插入删除一定慢吗?适合做队列吗?
ArrayList从结构上来看属于数组,也就是内存中的一块连续空间,当我们get(index)时,可以直接根据数组的首地址和偏移量计算出我们想要元素的位置,我们可以直接访问该地址的元素,所以查询速度是O(1)级别的。
我们平时会说ArrayList插入删除这种操作慢,查询速度快,其实也不是绝对的。
当数组很大时,插入删除的位置决定速度的快慢,假设数组当前大小是一千万,我们在数组的index为0的位置插入或者删除一个元素,需要移动后面所有的元素,消耗是很大的。但是如果在数组末端index操作,这样只会移动少量元素,速度还是挺快的(插入时如果在加上数组扩容,会更消耗内存)。
个人觉得不太适合做队列,基于上面的分析,队列会涉及到大量的增加和删除(也就是移位操作),在ArrayList中效率还是不高。
ArrayList 底层实现就是数组,访问速度本身就很快,为何还要实现 RandomAccess ?
RandomAccess是一个空的接口, 空接口一般只是作为一个标识, 如Serializable接口。
JDK文档说明RandomAccess是一个标记接口(Marker interface), 被用于List接口的实现类, 表明这个实现类支持快速随机访问功能(如ArrayList). 当程序在遍历这中List的实现类时, 可以根据这个标识来选择更高效的遍历方式。
优缺点
上面说的查询速度快自然就是其中的优点,除此之外,还可以存储相同的元素。
底层数据结构属于数组,和数组的优缺点大同小异,数组属于线性表,更适合于那种在末尾经常添加数据的场景,而对于在整个list中各个位置随机添加元素比较多的情况则不太合适。
因为可能会涉及到很多元素位置的移动。
ArrayList还有一个比较大的缺点就是不适应于多线程环境,这个设计之初也不是用于多线程环境的,像ArrayList、LinkedList、HashMap这种常见的都是以效率优先的,都是没有考虑线程安全的,也就自然不是线程安全的。
而这,恰恰也就是本文的重点,也是面试官最爱的菜。
ArrayList中的Fail-fast机制
fail-fast快速失败机制,一个线程A在用迭代器遍历集合时,此时另一个线程B如果对集合进行修改,就会导致线程A快速失败,然后线程会抛出.。ConcurrentModificationException异常。
在java.util中的集合类都是快速失败的,快速失败机制就是应对多线程场景的。
Vector真的安全吗
如何使用安全的ArrayList,很多人的答案可能是Vector,而Vector的实现其实也很简单,我给大家看段代码。
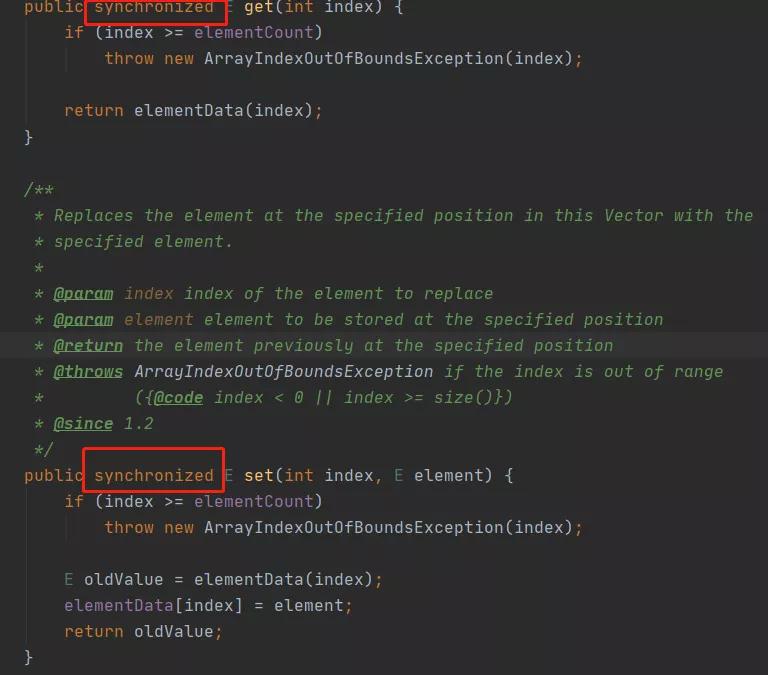
是的,道理也很简单,就是直接在每个方法加上synchronized关键字。
- public class CaptainTest {
- private static Vector<Integer> vector = new Vector();
- public static void main(String[] args) {
- while (true) {
- for (int i = 0; i < 10; i++) {
- vector.add(i); //往vector中添加元素
- }
- Thread removeThread = new Thread(new Runnable() {
- @Override
- public void run() {
- for (int i = 0; i < vector.size(); i++) {
- Thread.yield();
- //移除第i个数据
- vector.remove(i);
- }
- }
- });
- Thread printThread = new Thread(new Runnable() {
- @Override
- public void run() {
- for (int i = 0; i < vector.size(); i++) {
- Thread.yield();
- //获取第i个数据并打印
- System.out.println(vector.get(i));
- }
- }
- });
- removeThread.start();
- printThread.start();
- //避免同时产生过多线程
- while (Thread.activeCount() > 20) ;
- }
- }
- }
我们来执行上面的这段代码,这段代码会产生两种线程,一种remove移除元素,一种是get获取元素,但是都调用了size方法获取大小。
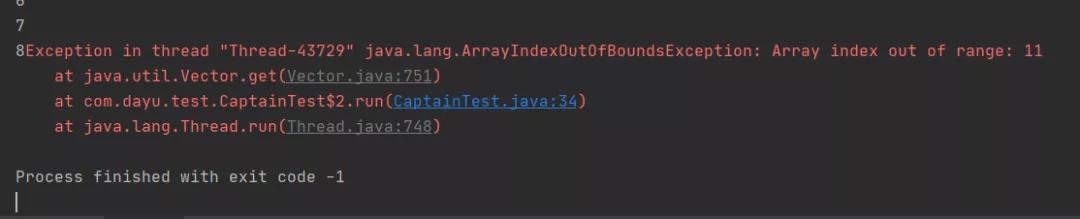
执行之后会报一个越界的异常,这是为啥呢,Vector不是每个方法都加上了synchronized关键字了吗,怎么会出现这种错误。
加上关键字保证其它线程不能同时调用这些方法了,也就是,不能出现两个及两个以上的线程在同时调用这些同步方法。
图中报错的问题的原因是:例子中的线程连续调用了两个或者两个以上的同步方法,听起来很奇怪是吗?我来解释下。
例子中的removeThread线程会首先调用size方法获取大小,接着调用remove方法移除相应位置的元素,而printThread线程也是先调用size方法获取大小,接着调用get方法获取相应位置的元素。
假设vector大小是5,此时printThread线程执行到i=4的时候,进入for循环但是在执行输出之前,线程的CPU时间片到了,此时printThread则转入到就绪状态。
此时removeThread线程获得CPU的执行权,然后把vector中的5个元素都删除了,此时removeThread的CPU时间片到了。
而此时printThread再获取到CPU的执行权,此时执行输出中的get(4)方法就会出现越界的错误,因为此时vector中的元素已经被remove线程删除了。
synchronized关键字保证的是同一时间片只有一个线程进入该方法执行,但是无法保证多个线程之间的数据同步,也就是remove线程删除vector元素之后无法通知到print线程。
聪明的你应该已经理解这个场景了吧,所以,vector在多线程使用的时候也不是绝对安全的。
CopyOnWriteArrayList
这个就是为了解决多线程下的ArrayList而生的,位于java.util.cocurrent包下,就是为并发而设计的。
我们听名字其实也可以简单的读懂,就是写的时候会复制一份新的数据,而事实是每一次的数据改动都会伴随这一次数据的复制。
设计的重点其实就是读写分离,这个思想大家再熟悉不过了吧,读的时候不会加锁,而写的时候会复制一份新数据,然后加上锁之后进行修改。
老规矩,先看一段代码,我们通过debug的方式来学习下先。
- public static void main(String[] args) {
- CopyOnWriteArrayList list = new CopyOnWriteArrayList();
- list.add("test1");
- Thread addThread = new Thread(new Runnable() {
- @Override
- public void run() {
- list.add("test4");
- try {
- Thread.sleep(1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- addThread.start();
- }
来吧,我们一起debug看下过程,顺便看下源码:

加锁用的是ReentrantLock,使用完了要记得手动释放锁,继续:
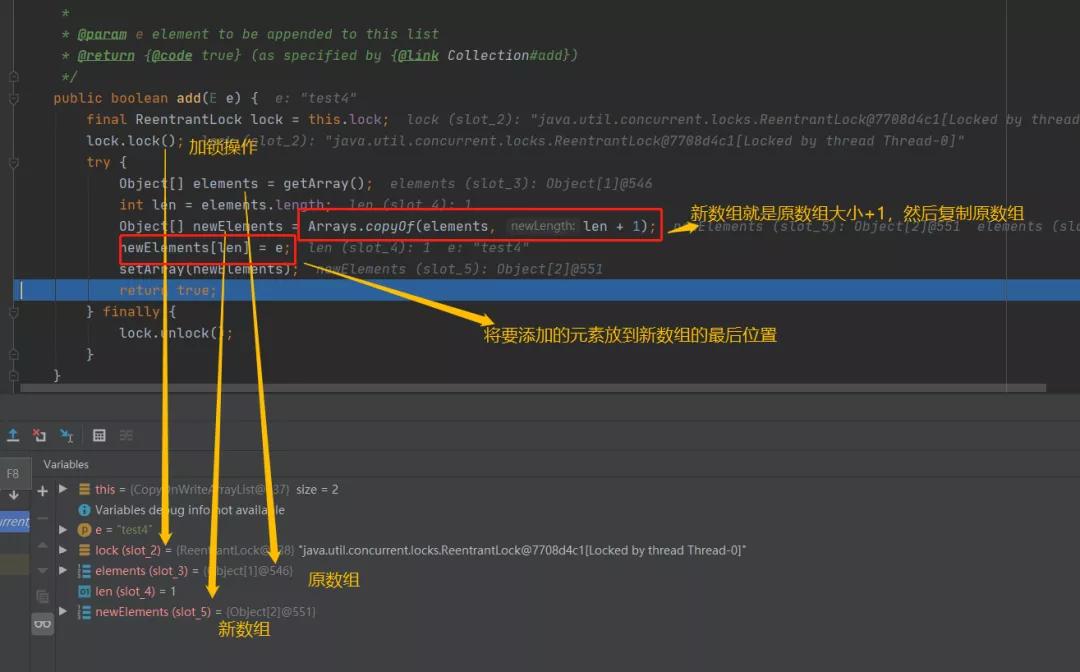
add的过程也是比较简单的,先是加锁,加锁之后调用getArray,这个就是拿到现在的数组,然后取得数组的大小。
接着是将原数组复制到一个大小加一的一个更大的数组中,然后将要添加的元素复制到最后的位置,最后再调用SetArray进行赋值,完成替换。
我们可以通过地址很清晰的看到,新数组就是又重新开辟了一块内存空间,和原来数组是完全不一样的。
其实这也就意味着每次add增加元素都需要一次数组的复制。
对于get获取元素来说也没有太多需要注意的,这个里面没有什么额外的操作,没有什么复制新数组一类的操作,只是简单的从原数组取值即可。
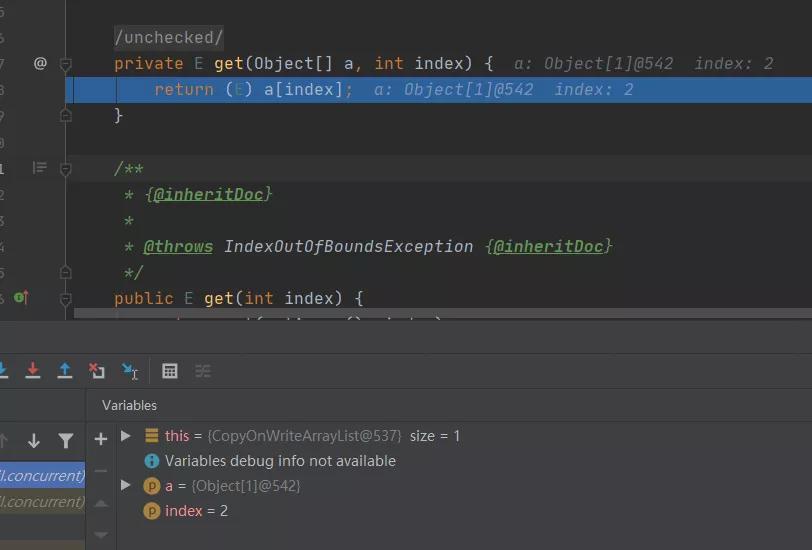
这也就意味着在多线程运行的时候,线程读取到的数据可能不是最新的我们想要的数据,但是这种情况是需要我们考虑到的,必须在可以接受的情况下来使用。
remove和iterator
分析remove过程:
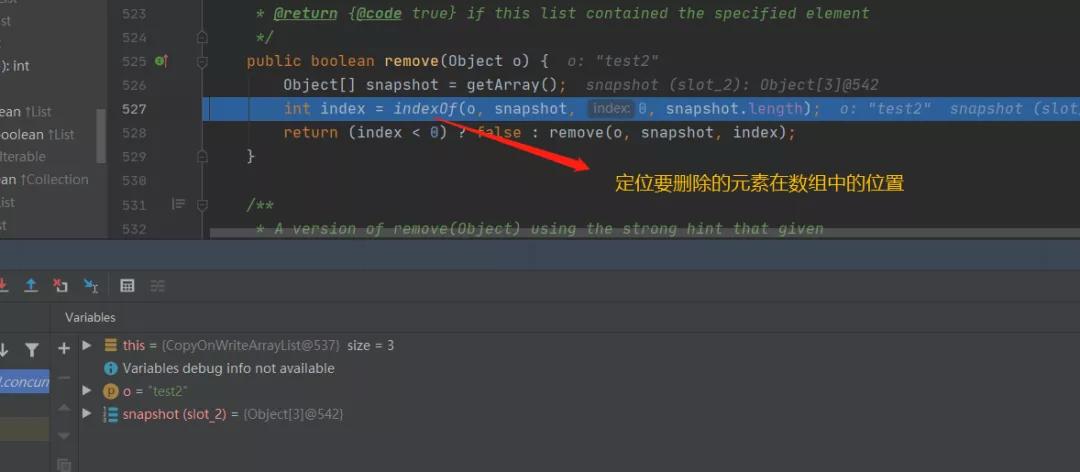
进去indexOf看:

这个其实也很好理解,就是循环遍历,然后通过equals判断,相同则返回定位到的位置。
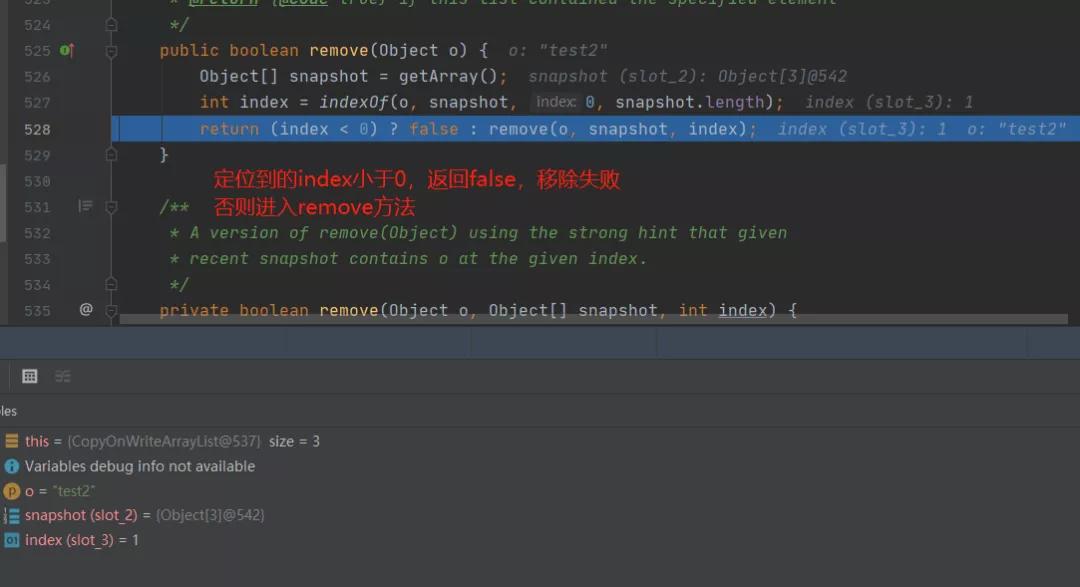
当我们想要删除一个不存在的元素的时候,我们在这里会拿到false,因为底层定位不到会返回-1,我们进入remove方法看,这个是重点。

我们再重新看一下remove的源码。
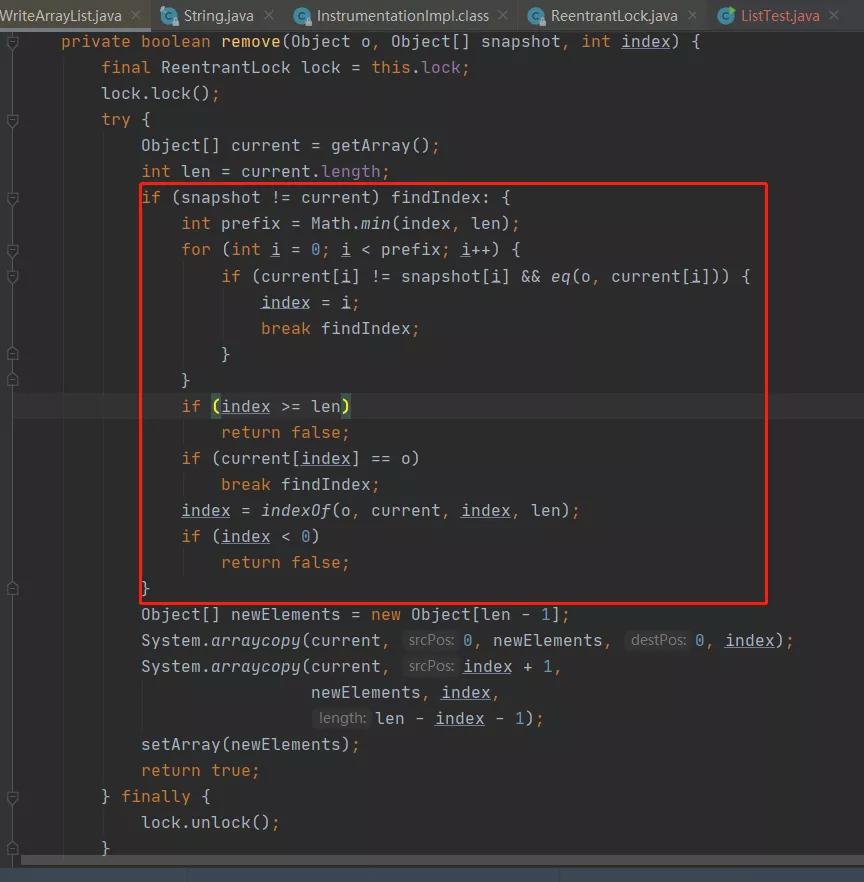
刚刚的调试是没有走到这里面的,我们把目光聚集到这块代码。
snapshot是刚刚的镜像数据,这里考虑到了多线程的情况,即原有的数组可能已经被其它的线程修改了,snapshot已经过时的数据了,而这段处理的就是如果该数组被别的线程修改了的情况下,是如何处理的。
其实根本目的就是重新定位index的值,防止误删别的元素。
先是找到index和当前长度中的最小值,进行遍历,findIndex就是做这个的,在其中重新找相应的元素,找到就就直接跳出,重新判断。
如果没有找到元素下标,就进行下面的判断,index大于len的时候,代表元素被删除或者不存在了。
也不是很难理解,大家看一下这块就可以理解了。
看里面的iterator
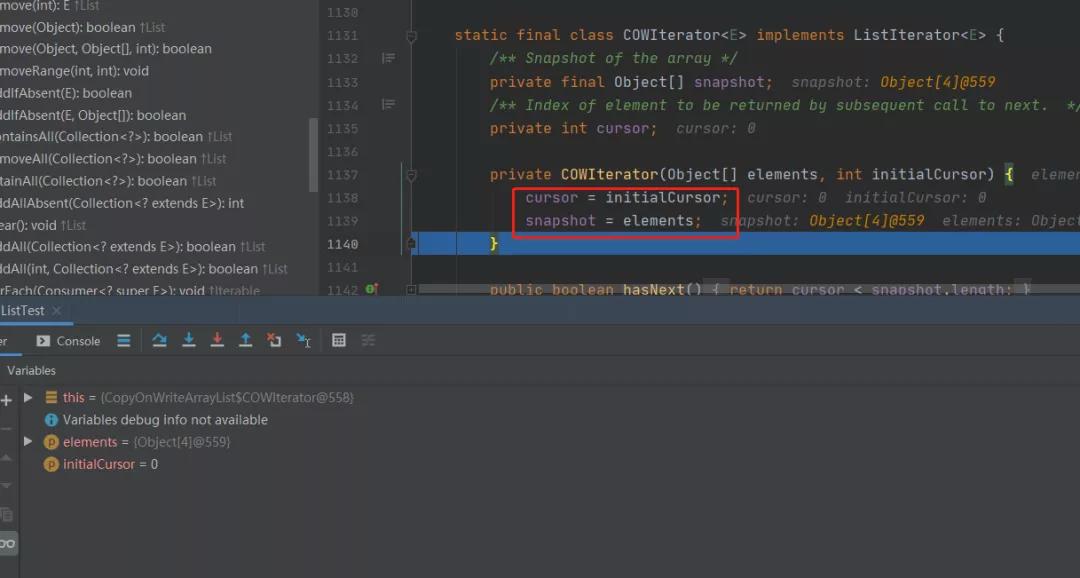
这个迭代器和原来ArrayList中的迭代器区别点就是增加了一个快照机制,这个快照就是把遍历时的这个最新链表状态记录了下来。
此快照数组在迭代器的生存期内是不会更改的,因此也就不可能发生冲突,也就保证了迭代器不会抛出并发修改异常。
创建迭代器以后,迭代器不会反映列表的添加、移除和更改等修改的操作,但是也就同时带来了一个小小的问题,遍历拿到的数据可能不是最新的数据。
需要注意的一点,ArrayList在迭代器上进行元素的更改操作是不被允许的,比如remove、set和add操作,这些方法将抛出UnsupportedOperationException异常。
CopyOnWriteArrayList优缺点分析
优点
读操作性能高,无需要任何的同步措施,比较适合于读多写少的并发场景。
采用读写分离的思想,读的时候读取镜像的数据,写的时候复制一份新的数据进行修改操作,所以也就不会抛出并发修改异常了。
存储的数据有序,刚刚在看源码的时候你应该注意到了,它是先进行原数据的复制,然后再在最后位置上赋值这个要添加的数据。
缺点
内存占用问题,每次写操作都需要将原容器数据拷贝一份,数据量比较大的时候,对内存压力会比较多,也有可能引起频繁的GC。
读取的时候无法保证实时性,这也是读写分离付出的代价,Vector可以保证读写的强一致性,但是缺点上面也已经说过了,不同的场景使用不同的容器。
哦对了,后续所有的文章都会更新到这里。
https://github.com/DayuMM2021/Java
本文转载自微信公众号「Java贼船 」,可以通过以下二维码关注。转载本文请联系Java贼船公众号。























