













计算机只能理解 0 和 1 组成的二进制数据, 一个 bit 的值是 0 或 1,八个这样的 bit 组成了一个字节,通过字节,计算机可以表示一些复杂的数据,比如:音频、视频等,有些数据用一个字节就能表示,比如英文字符,而有些数据需要多个字节来表示,比如:汉字, 对于多字节的数据,存储的时候会有字节顺序的问题,也就是字节序
字节序是什么
字节序是计算机存储多字节数据的方式,目前的方式有:大端字节序和小端字节序,字节序主要是针对多字节的数据类型,比如 short、int 等
- 大端字节序
高位字节存储在内存的低地址上,低位字节存储在内存的高位地址上
- 小端字节序
高位字节存储在内存的高地址上,低位字节存储在内存的低地址上
如何理解字节序
我们平常书写和阅读数字的习惯是从左到右的,所以把最左边的字节当作最高位字节,最右边的字节当作做最低位字节,从左到右,表示从高位字节到低位字节
例如:对于 0x01020304,它的大端和小端字节序在内存中的布局如下图所示
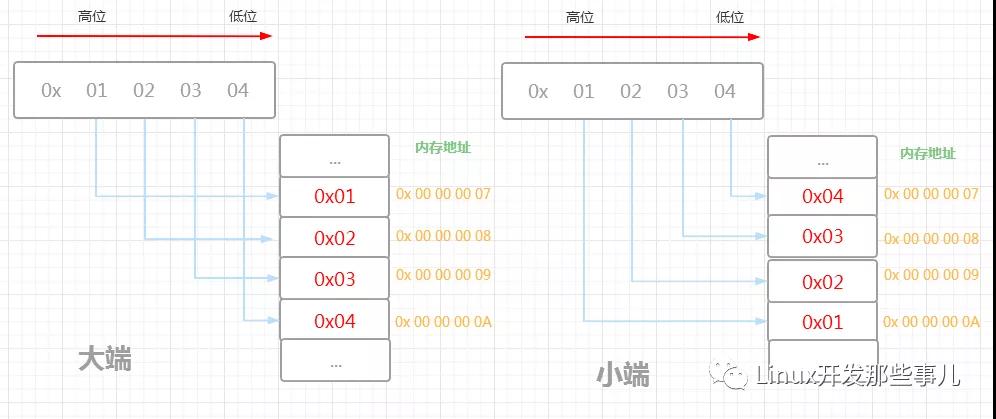
0x 01 02 03 04 总共四个字节大小,以人们习惯的阅读顺序,0x01 处于左边,属于高位字节,0x04 处于右边,属于低位字节
内存地址从 0x 00 00 00 07 到 0x 00 00 00 0A 4个字节的空间,刚好能存储得下
根据大端字节序的的规则:高位字节存储在内存低地址,所以处于高位字节的 0x01 存储在 0x 00 00 00 07 地址处,紧接着 次高位字节 0x02 存储在次低地址 0x 00 00 00 08 处,剩下的两个字节 0x03 和 0x04 分别存储于 0x 00 00 00 09 和 0x 00 00 00 0A 地址处,最后的结果是 0x 01 02 03 04
小端字节序和大端刚好相反,它指的是 高位字节存储在内存高地址处,所以处于高位字节的 0x01 存储在 0x 00 00 00 0A 地址处,次高位字节 0x02 存储在次高地址 0x 00 00 00 09 处,余下的 0x03 和 0x04 分别存储于 0x 00 00 00 08 和 0x 00 00 00 07 地址处,最后的结果是 0x 04 03 02 01
从上图可以看出,对于相同的数据,大端和小端的内存布局是不一样的,大端字节序的存储形式更符合人们平常书写和阅读的习惯
为什么会有字节序
可能有人会感到疑惑:既然大端字节序更符合人们阅读的习惯,为什么不全部都采用大端的方式,这样也就不会有字节序的问题了 ?
确实,如果所有平台都用同一种存储顺序,就没有字节序这一说法了
在早期, CPU 只有几千个逻辑门,小端的方式能更有效的使用逻辑电路,所以很多计算机内部计算都采用小端的方式,这种方式也就保留到了现在
另外,字节序是跟 CPU 架构相关,不同的厂家设计的规范可能都不一样,比如 Intel 的 x86 是小端方式,而 IBM 的 PowerPC 则采用大端方
大端的方式更符合人们的阅读习惯,因此大部分网络传输以及文件存储都是大端的方式
总的来说,小端主要是在计算机内部使用,大端则在外部使用
计算机如何处理字节序
计算机读取数据的时候是不区分字节序的,它总是从内存低地址到高地址的顺序,按字节读取
下面的示例图展示了数据 0x0102 的 大端和小端的内存布局以及CPU读取内存的顺序
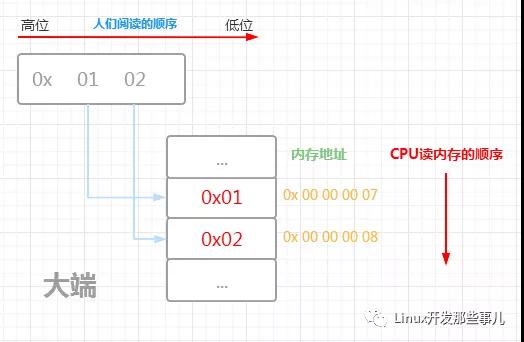
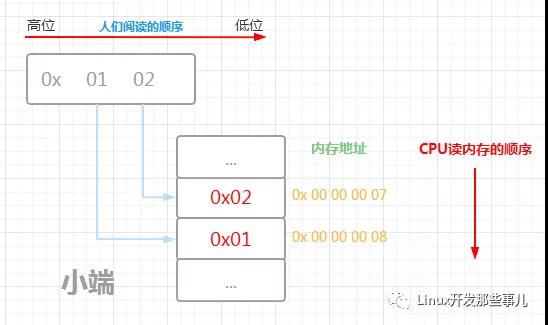
由上图可知,对于大端字节序来说,内存低地址处存储的是高位字节,也即计算机读取内存的第一个字节就是高位字节,小端字节序就正好相反,内存低地址处存储的是低位字节,读取内存的第一个字节是低位字节
计算机只有在读取数据的时候才需要区分字节序
就拿上面展示大端方式的图 ( 第一张 ) 来说,内存 0x 00 00 00 07 地址处存储的数据是 0x01 , 0x 00 00 00 08 地址处存储的数据是 0x02
如果是以大端的方式读取的话,地址 0x 00 00 00 07 处的数据 0x01 会放到高位字节, 0x 00 00 00 08 处的数据是 0x02 放到低位字节,最终这两个字节的数据是 0x 01 02
如果是以小端的方式读取的话,,地址 0x 00 00 00 07 处的数据 0x01 会放到低位字节, 0x 00 00 00 08 处的数据是 0x02 放到高位字节,最终这两个字节的数据是 0x 02 01
网络字节序
所有的协议都是人类编制定的,大端对人们阅读更友好,所以 IEEE 标准协会规定除非有明确说明,否则网络协议都使用大端字节序, 像 TCP/IP 就是如此
还记得我们在编写网络程序的时候,传入 connect 函数实参中的 端口号吗, 传入之前需调用 htons 函数将其转成网络字节序,也就是要转成大端字节序,下面是部分代码示例
- struct sockaddr_in addr;
- addr.sin_family = AF_INET;
- addr.sin_addr.s_addr = inet_addr("192.168.1.10");
- addr.sin_port = htons( 5000 );
- connect( clientfd, (struct sockaddr *)&addr, sizeof(addr)) )
上面红色的 htons 函数的作用是将 端口号 由主机字节序转成网络字节序,网络字节序大多时候都是固定为大端序的,但不同的机器,主机序却不一样,如果本身就已经是大端了,调用 htons 函数,返回值和实参是一样的,如果本身是小端,结果会转成大端的形式,具体的数值也会不一样
怎么判断大小端
上面提到了主机字节序,那如何知道当前机器是大端还是小端呢 ?
因为操作系统必须适配所有类型的 CPU ,所以对于操作系统来说,大端和小端它都是支持的
为了让程序易于判断当前平台是大端还是小端,Linux 下 glibc 库提供了下面几个宏定义
- BIG_ENDIAN # 大端序
- LITTLE_ENDIAN # 小端序
- BYTE_ORDER # 字节序
下面是测试代码 test.c 文件
- #include <stdio.h>
- int main(int argc, char *argv[])
- {
- if(BYTE_ORDER == BIG_ENDIAN)
- {
- printf("big endian...\n");
- }
- else
- {
- printf("little endian...\n");
- }
- }
执行 gcc -g -o test test.c 命令进行编译,运行测试程序,结果如下:
- [root@localhost test]# ./test
- little endian...
由此,可以知道当前平台是小端字节序
除了用上面的方法之外,我们可以根据大端和小端的特点,自己写代码获取,修改 test.c 文件,内容如下
- #include <stdio.h>
- int main(int argc, char *argv[])
- {
- union
- {
- unsigned short i;
- char ch[2];
- }un;
- un.i = 0x0102;
- if(0x01 == un.ch[0])
- {
- printf("big endian...\n");
- }
- else
- {
- printf("little endian...\n");
- }
- }
编译并运行,结果如下:
- [root@localhost test]# ./test
- little endian...
可以看出,不管是通过系统库提供的宏来判断还是自行封装接口来判断机器的字节序都是可行的
最后,如果想知道 LITTLE_ENDIAN、 BIG_ENDIAN 、BYTE_ORDER 宏定义的详细情况,可以查看 glibc 源码,它们在 glibc-2.17\string\endian.h 以及 glibc-2.17\sysdeps\x86\bits\endian.h 文件中
注意:不同版本的 glibc 源码,具体的位置可能有差异,我使用的是 glibc-2.17 版本
大端小端的转换
熟悉了大端和小端特点,它们之间的转换就简单了,对于两字节来说,每个字节值不变,互换字节位置,如果是更多字节的话,最低位字节和最高位字节交换,次低位字节与次高位字节交换,直到所有字节都完成了一遍交换为止
比如:下面是小端转大端的伪代码
- #小端转大端 假设:ch 和 i 是小端序
- char ch[2];
- int i = 0;
- # x 是大端字节序
- x = ch[1] << 8 | ch[0]
- # y 是大端字节序
- y = ( (i & 0xff000000) >> 24 ) | ( (i & 0x00ff0000) >> 8 ) | ( (i & 0x0000ff00) << 8 ) | ( (i & 0x000000ff) << 24 )
变量 i 字节序转换说明:按照从左到右的顺序,把 i 的第一个字节右移 3 个字节( 24 bit ),第二个字节右移 1 字节 ( 8 bit ),第三个字节左移 1 字节 ( 8 bit ),第四个字节左移 3 个字节 ( 24 bit ),最后把移位后的字节组合起来就可以了
在实际的程序处理中,不应该出现字节序的问题,只有 "网络字节序" 和 "主机字节序" ,需要转换字节序时,使用 ntohl, ntohs, htonl, htons 等函数即可
- ntohl # uint32 类型 网络序转主机序
- htonl # uint32 类型 主机序转网络序
- ntohs # uint16 类型 网络序转主机序
- htons # uint16 类型 主机序转网络序
小结
本文详述了字节序的一些知识,开发网络应用的时候会涉及到字节序的相关问题,所以,花点儿时间弄明白还是很有必要的



























