数据科学是一个广泛的领域。
因为它是如此的多样化,我们很难具体定义数据科学家要做些什么。但最重要的是,我们要认识到,数据科学是一个过程,而不仅仅是一个职位名称。
数据科学可以应用于许多不同的领域,可以用来做许多不同的事情。
如今数据科学、机器学习和数据工程正在以非常快的速度发展。
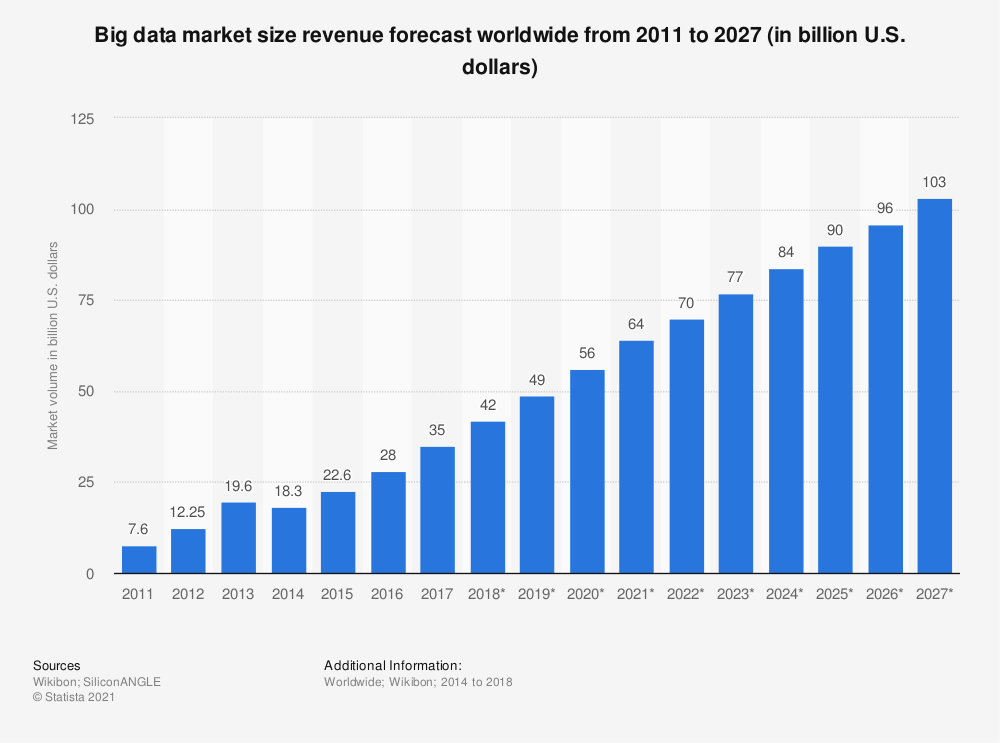
2011-2027年全球大数据市场规模预测
随着数据领域的发展速度加快,许多人对这些领域的概念也有一些错误的认识。
在本文中,我们将带你了解一下数据工程师、数据科学家和机器学习工程师之间的区别。
让我们先了解一下完整的数据项目包括哪些环节。
公司通过各种渠道从客户处收集数据,例如亚马逊,他们可能会收集用户的电子邮件、姓名、年龄、位置等数据。
以及关于用户购买历史和订单的数据,用户搜索关键字和最近查看的项目等。
如今,这些数据有各种形式和格式,数据可能位于不同的表和不同的位置。
任何数据项目的出发点无一例外,都是为了从数据中提取价值,从而帮助企业做出决策,并改进其产品和服务。
这里可以看到一个案例——亚马逊建立的推荐系统,当中将用用户经常购买的产品排列在一起,并根据产品的性能进行排名。
任何数据项目的第一步都是理解。
企业真正需要什么
假设,我们想针对会从已购商品中进行回购的客户建立一个分类器。
我们对所需的最终结果进行定义,可能会根据可用数据而改变,但假设现在一切准备就绪,开始项目开发。
这时数据工程师们就派上用场了。
在数据项目工作中,数据工程师将从各种来源提取数据并编写查询,或使用ETL工具将所有数据集中到一个地方。
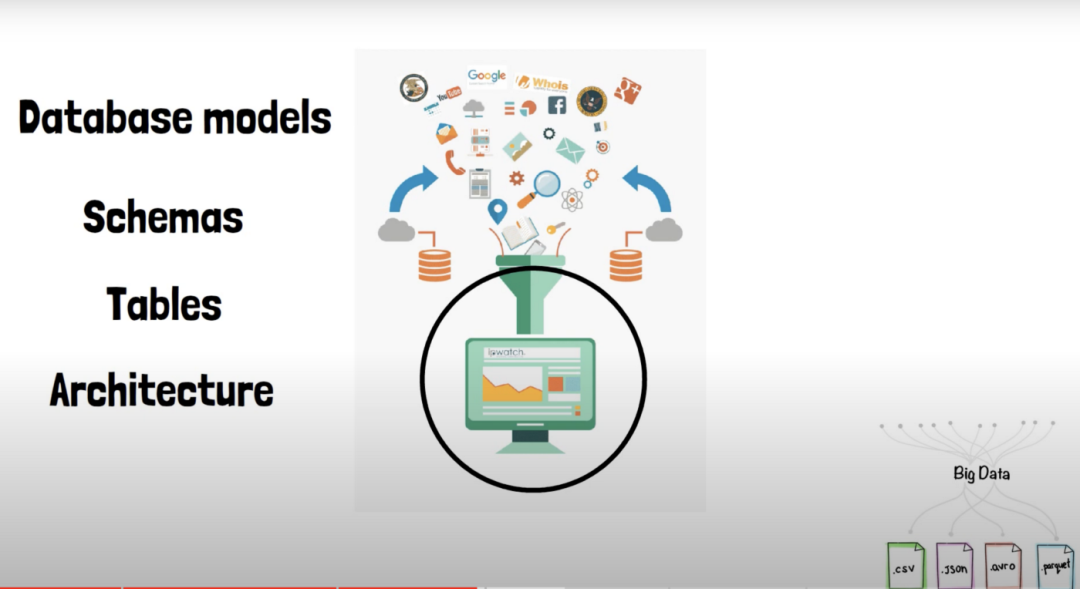
数据被储存为各种格式,比如SQL表、CSV文件、JSON文件等。
因此,数据工程师要做的就是对这些数据进行转换,并将所有东西整合在一起。并负责建立数据库模型、模式、表、架构以及数据的整体结构。
一旦数据准备妥当,数据科学家、数据分析师或BI人员就要上场了。
为了便于理解,这里我们用数据科学家来概括这些角色,因为数据科学是一个非常广泛的领域,他们所做的工作内容包罗万象。
现在,数据科学人员有了正确格式的数据,而数据科学家对业务有很好理解,他很清楚需要做些什么来完成工作。
数据科学家需要负责的工作内容有:
- 提取业务需要的数据;
- 为机器学习模型清理数据;
- 定义训练模型所需的特征;
- 建立仪表盘或可视化以更好地理解数据;
- 为机器学习模型准备数据等等。

由于数据项目需要团队协作,因此有许多人会参与到这个过程。
不是每个人都会清理数据或构建数据可视化,这完全取决于数据人员的技能和角色。
接着就需要机器学习工程师,他们同时拥有软件工程和数据科学方面的知识。
他们使用大数据工具和编程框架,确保从数据管道中收集的原始数据被重新定义为数据科学模型,并根据需要进行扩展。
在这个推荐系统的项目中,我们可能需要实时预测的模型,也需要通过调用API来提供预测的模型。
机器学习工程师的职责是建立机器学习模型,对其进行适当调整,确保模型产生良好的结果,在产品中部署模型。
机器学习工程师使机器能够在自己的编程数据中识别模式,并教会自己理解命令。
结语
现在这三个领域相互依赖,没有哪一个更好的比较,每个领域都有自己的角色、责任和所需的技能,完全取决于你选择哪一个。
现在,这三种职业相互依赖,没有哪个职业更好的说法。在工作项目中,这三者分别都有不同的角色担当,责任和技能要求,选择从事哪一种完全取决于你自己的兴趣。
如果你喜欢构建管道,数据模型和模式,那么成为数据工程师是不错的选择。
如果你更喜欢清理数据、数据可视化和构建仪表盘,那么你可以选择成为一名数据科学家,或者机器学习工程师,前提是你有完成工作所需的知识和技能。
因此不妨问问自己,你更适合哪一种?数据工程师,数据科学家,还是机器学习工程师?