












本文将分析IPFS的特性,并在与其他分布式文件系统和超文本传输协议(HTTP)比较的基础上,进行并行研究。
引言
互联网是由协议和物理设备连接起来的大量计算机器的集合。大多数互联网内的生态系统都基于客户端-服务器(请求-响应)模型,但这种模型并非不可破坏,网络时不时会出现故障。无论是否有控制中心,点对点(P2P)系统都可以高效分发海量数据。2014年,Juan Benet提出了整合现有的先进技术(分布式哈希表(DHT)、BitTorrent-like协议、基于Git的数据模型等)创建一个新的协议/文件系统,使每个人都具有共享数据的平等权利,符合互联网的早期思想。IPFS具有高效的数据存储与分发、数据保持、面向离线模式和非集中式管理的特性。
IPFS理论介绍
IPFS是一个纯粹的点对点分布式文件系统,这种系统侧重于从主要体系结构中删除中心点,并在网络中为相互连接的节点提供相同的功能。所有共享的数据和计算资源都存储在网络的边缘,节点能够自动运行,并与它们的对等节点共享所需数据。它们能够自主通信、分发数据、本地化其他节点和所需的文件,并使用同一组协议。
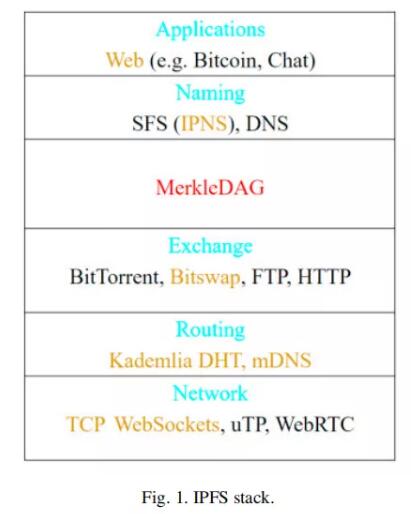
IPFS源于Juan Benet的分布式、去中心化、共享互联网的理念,自2014年出现以来,目前仍处于开发阶段。现在已有一些可用的实现(如Go和JavaScript),以及一套使用各种编程语言实现的工具、库和API(应用程序编程接口)。IPFS的一些主要特点有:数据持久性、点对点基本原理、完全去中心化、无中心点故障、在无互联网上行链路情况下具有本地连接。
- HTTP在日常基础使用中效率低下且昂贵;IPFS使以一种有效的方式使分发大量数据成为可能;
- 储存在互联网上的旧内容通常会和旧版本的文件一起被删除;IPFS有一种类似于Git的数据版本控制方法;
- 互联网用户依赖于管理其功能的集中设备,当没有连接到互联网骨干网时,他们无法与这些设备通信,也无法访问他们的个人数据;IPFS是各种弹性网络的引擎,无论是否有全球上行链路,这些网络都试图将尽可能提高其分散性。
Juan Benet发布的官方白皮书代表了他对协议架构和模块的观点。总的来说,IPFS的灵感来源于一些被塑造成单一、模块化协议的技术,IPFS利用了这些想法和经验。我们将简要介绍这些技术,以更好的理解IPFS。
从IPFS堆栈的最底层开始,网络层可以进行数据储存、信息交换及交换控制信息。传输本身可使用各种协议(如TCP、UTP、WebSocket、WebRTC等)以一种安全可靠的方式实现,而IPFS本身不绑定到某个特定的协议上。
向上进入到路由层,分布式哈希表(DHT)用于存储和管理系统内部的元数据。这些信息包含在给定的时间点上相互连接的节点的信息,并提供快速有效地查找数据的机制。Kademlia在路由层十分重要,它提供了在大型网络中查找元数据的有效方法、低协调成本,Coral DSHT通过查询最近的能够存储数据的节点来实现扩展,并提高数据被存储在更远位置的节点上的可能性。S/Kademlia通过强制节点创建用于生成身份和签名消息的PKI(公钥基础设施)密钥对,进一步增强了针对恶意攻击的安全性。对于本地定位的节点,使用组播DNS(域名系统)实现相互搜索。
交换层用于确保节点之间的块传输。
进一步到达堆栈上层,默克尔有向无环图(Merkle DAG)是协议的主要数据模型,很大程度上是受到Git数据结构的启发。数据树的节点是通过其内容加密寻址的对象,而它们之间的链接由对其他对象的哈希引用表示。每个数据都是由其不可变哈希引用唯一标识的(因此只存储一次,重复数据删除),系统能够使用校验和检测损坏的数据。
堆栈的最后一层是命名层。每个节点的唯一标识符是使用PKI密钥对以加密的方式在本地生成的。星际命名系统(IPNS)是一种用于识别可修改对象的策略。数据块具有不可变的哈希引用,因此一旦它们的内容改变,哈希引用就会改变。IPNS概念使用自认证文件系统方案,因此节点能够在自己唯一的节点标识符上发布数据。如果数据本身改变,哈希引用也会改变,但节点可能会将新的引用重新发布到相同的唯一节点标识符。IPNS还支持DNS来提供人类可读的地址。
处于最上层的是应用层,在这里,开发人员能够使用堆栈的底层功能设计和实现新的分布式、去中心化技术。
IPFS vs. 其他DFS
这一部分将讨论各种DFS(分布式文件系统)和HTTP(超文本传输协议)的各方面特性。
NFS(Network File System,网络文件系统)是SUN公司在1984年开发的基于RPC(远程过程调用)协议的开放协议,其基于UDP/IP协议的应用,主要特性是具有一个控制中心,NFS 允许在多个用户之间共享公共文件系统,并提供数据集中的优势,来最小化所需的存储空间。
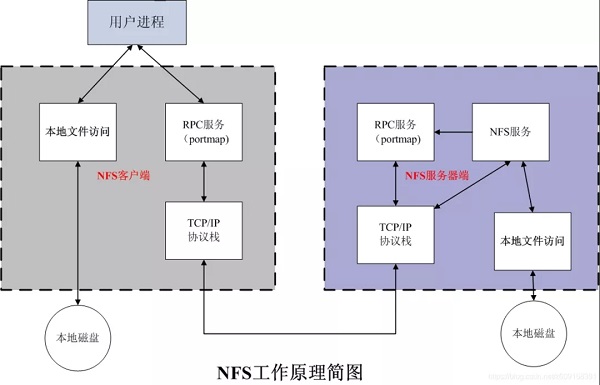
将早期的NFS与IPFS进行比较,我们可以看出,NFS使用服务器和幂等的、无状态的行为在系统中进行数据同步,而IPFS架构可以不依赖于服务器,因为其哈希引用生成的数据可以在其协议用户间共享。IPFS在节点自动状态下以同步/异步方式处理写操作,其用户只要获得数据标识符,就可以通过元数据交换和搜索在网络中共享数据。
AFS(Andrew File System,安德鲁文件系统)是由Carnegie Mellon大学在20世纪80年代和IBM公司联合设计的一个分布式文件系统,它的主要功能是用于管理分布在网络不同节点上的文件,其使用一组受信任的服务器为客户端提供同类的、地址透明的文件名称空间,主要目标是实现可扩展性,尤其关注客户端和服务器之间协议的设计。文件在本地磁盘上整体进行储存和缓存,客户端想要访问一个文件时,将从服务器获取文件,在本地缓存,然后服务器设置回调(用于之后通知客户端文件被修改)。IPFS机制同样可以用于实现类似的回调和缓存系统,同时保持不集中(单点故障)的优势。
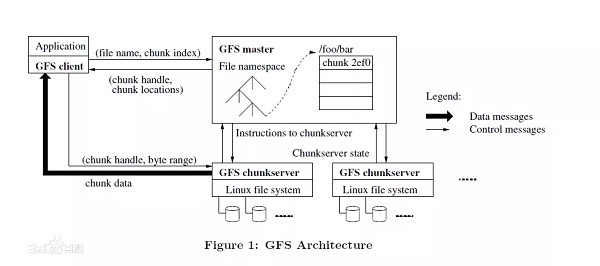
GFS(Google File System,谷歌文件系统)是谷歌为了存储海量搜索数据而设计的专用分布式文件系统,专注于可扩展性、基础性能和低价硬件。谷歌希望提供一种附加而不是重写的数据分发方法,从而构建一个可自我持续的文件系统:具有监督恢复、使用主块架构存储跨多个服务器备份的大量数据的可能性。GFS的设计与IPFS有一些相似之处,它使用多个块服务器、数据块和替换机器来应对崩溃情况。与IPFS相比,GFS的信息仍然在中心区域管理,由主服务器协调,而IPFS的数据基本上是存储在网络中。
HTTP(超文本传输协议)是全球范围内用于Web上下文中数据交换的最流行的协议之一。它遵循经典的客户端-服务器模型架构,服务器通常位于互联网之外,而客户端则是浏览器。整个机制依赖于客户端和服务器之间的请求(数据)-响应(数据/状态)交互。其特点是简单、可扩展、无状态,具有控制中心。HTTP目前仍运行良好,但问题逐渐出现:如果资源被删除、损坏或被其提供者关闭,该怎么处理?
上述文件系统/协议中使用的所有技术都带来了保证数据分布的创新机制:AFS的回调、NFS的幂等性和崩溃时的简单重试、GFS的可扩展性和低价硬件设计、HTTP的简单性和长寿命,但它们都依赖于同一个控制中心。
总结
如今的实际应用中,大多数技术都是基于经典的客户端-服务器模型。此模型自互联网诞生以来,目前仍能基本满足客户的需求。开发人员和工程师需要着重关注的是优化应用程序以最小化计算时间和响应速度,并全面改善我们目前的互联网系统。IPFS试图通过改变数据分布、存储和管理的整个视角,同时保持对可能使用的其他协议的开放接口,来解决互联网的问题。尽管目前IPFS还有很大的改进空间,但其能否成为新一代互联网协议也犹未可知。













