













这是一篇聊算法的文章,从一个小面试题开始,扩展到一系列基础算法,包含几个部分:
(1) 题目简介;
(2) 思路一:暴力法;
(3) 思路二:染色法;
(4) 思路三:链表法;
(5) 思路四:并查集法。
除了聊方案,重点分享思考过程。文章较长,可提前收藏。
第一部分:题目简介
问题提出:求微信群覆盖
微信有很多群,现进行如下抽象:
(1) 每个微信群由一个唯一的gid标识;
(2) 微信群内每个用户由一个唯一的uid标识;
(3) 一个用户可以加入多个群;
(4) 群可以抽象成一个由不重复uid组成的集合,例如:
- g1{u1, u2, u3}
- g2{u1, u4, u5}
可以看到,用户u1加入了g1与g2两个群。
画外音:
- gid和uid都是uint64;
- 集合内没有重复元素;
假设微信有M个群(M为亿级别),每个群内平均有N个用户(N为十级别).
现在要进行如下操作:
(1) 如果两个微信群中有相同的用户,则将两个微信群合并,并生成一个新微信群;
例如,上面的g1和g2就会合并成新的群:
g3{u1, u2, u3, u4, u5};
画外音:集合g1中包含u1,集合g2中包含u1,合并后的微信群g3也只包含一个u1。
(2) 不断的进行上述操作,直到剩下所有的微信群都不含相同的用户为止;
将上述操作称:求群的覆盖。
设计算法,求群的覆盖,并说明算法时间与空间复杂度。
画外音:你遇到过类似的面试题吗?
对于一个复杂的问题,思路肯定是“先解决,再优化”,大部分人不是神,很难一步到位。先用一种比较“笨”的方法解决,再看“笨方法”有什么痛点,优化各个痛点,不断升级方案。
第二部分:暴力法
拿到这个问题,很容易想到的思路是:
(1) 先初始化M个集合,用集合来表示微信群gid与用户uid的关系;
(2) 找到哪两个(哪些)集合需要合并;
(3) 接着,进行集合的合并;
(4) 迭代步骤二和步骤三,直至所有集合都没有相同元素,算法结束;
第一步,如何初始化集合?
set这种数据结构,大家用得很多,来表示集合:
(1) 新建M个set来表示M个微信群gid;
(2) 每个set插入N个元素来表示微信群中的用户uid;
set有两种最常见的实现方式,一种是树型set,一种是哈希型set。
假设有集合:
s={7, 2, 0, 14, 4, 12}
树型set的实现如下:
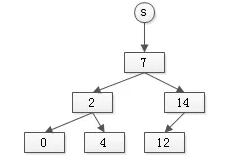
其特点是:
- 插入和查找的平均时间复杂度是O(lg(n));
- 能实现有序查找;
- 省空间;
哈希型set实现如下:
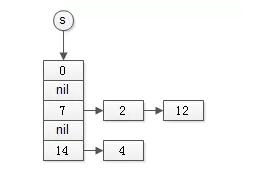
其特点是:
- 插入和查找的平均时间复杂度是O(1);
- 不能实现有序查找;
画外音:求群覆盖,哈希型实现的初始化更快,复杂度是O(M*N)。
第二步,如何判断两个(多个)集合要不要合并?
集合对set(i)和set(j),判断里面有没有重复元素,如果有,就需要合并,判重的伪代码是:
- // 对set(i)和set(j)进行元素判断并合并
- (1) foreach (element in set(i))
- (2) if (element in set(j))
- merge(set(i), set(j));
第一行(1)遍历第一个集合set(i)中的所有元素element;
画外音:这一步的时间复杂度是O(N)。
第二行(2)判断element是否在第二个集合set(j)中;
画外音:如果使用哈希型set,第二行(2)的平均时间复杂度是O(1)。
这一步的时间复杂度至少是O(N)*O(1)=O(N)。
第三步,如何合并集合?
集合对set(i)和set(j)如果需要合并,只要把一个集合中的元素插入到另一个集合中即可:
- // 对set(i)和set(j)进行集合合并
- merge(set(i), set(j)){
- (1) foreach (element in set(i))
- (2) set(j).insert(element);
- }
第一行(1)遍历第一个集合set(i)中的所有元素element;
画外音:这一步的时间复杂度是O(N)。
第二行(2)把element插入到集合set(j)中;
画外音:如果使用哈希型set,第二行(2)的平均时间复杂度是O(1)。
这一步的时间复杂度至少是O(N)*O(1)=O(N)。
第四步:迭代第二步与第三步,直至结束
对于M个集合,暴力针对所有集合对,进行重复元素判断并合并,用两个for循环可以暴力解决:
- (1)for(i = 1 to M)
- (2) for(j= i+1 to M)
- //对set(i)和set(j)进行元素判断并合并
- foreach (element in set(i))
- if (element in set(j))
- merge(set(i), set(j));
递归调用,两个for循环,复杂度是O(M*M)。
综上,如果这么解决群覆盖的问题,时间复杂度至少是:
- O(M*N) // 集合初始化的过程
- +
- O(M*M) // 两重for循环递归
- *
- O(N) // 判重
- *
- O(N) // 合并
画外音:实际复杂度要高于这个,随着集合的合并,集合元素会越来越多,判重和合并的成本会越来越高。
第三部分:染色法
总的来说,暴力法效率非常低,集合都是一个一个合并的,同一个元素在合并的过程中要遍历很多次。很容易想到一个优化点,能不能一次合并多个集合?
暴力法中,判断两个集合se<i>t和set<j>是否需要合并,思路是:遍历set中的所有element,看在set中是否存在,如果存在,说明存在交集,则需要合并。
哪些集合能够一次性合并?
当某些集合中包含同一个元素时,可以一次性合并。
怎么一次性发现,哪些集合包含同一个元素,并合并去重呢?
回顾一下工作中的类似需求:
M个文件,每个文件包含N个用户名,或者N个手机号,如何合并去重?
最常见的玩法是:
- cat file_1 file_2 … file_M | sort | uniq > result
这里的思路是什么?
(1) 把M*N个用户名/手机号输出;
(2) sort排序,排序之后相同的元素会相邻;
(3) uniq去重,相邻元素如果相同只保留一个;
“排序之后相同的元素会相邻”,就是一次性找出所有可合并集合的关键,这是染色法的核心。
举一个栗子:
假设有6个微信群,每个微信群有若干个用户:
- s1={1,0,5} s2={3,1} s3={2,9}
- s4={4,6} s5={4,7} s6={1,8}
假设使用树形set来表示集合。
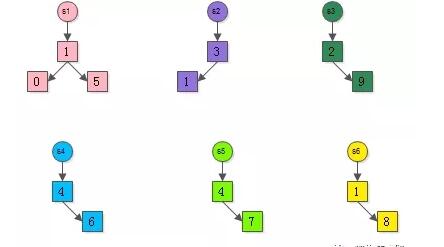
首先,给同一个集合中的所有元素染上相同的颜色,表示来自同一个集合。

然后,对所有的元素进行排序,会发现:
(1) 相同的元素一定相邻,并且一定来自不同的集合;
(2) 同一个颜色的元素被打散了;
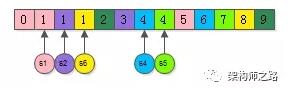
这些相邻且相同的元素,来自哪一个集合,这些集合就是需要合并的,如上图:
(1) 粉色的1来自集合s1,紫色的1来自集合s2,黄色的1来自集合s6,所以s1s2s6需要合并;
(2) 蓝色的4来自集合s4,青色的4来自集合s5,所以s4s5需要合并;
不用像暴力法遍历所有的集合对,而是一个排序动作,就能找到所有需要合并的集合。
画外音:暴力法一次处理2个集合,染色法一次可以合并N个集合。
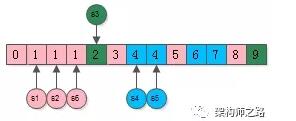
集合合并的过程,可以想象为,相同相邻元素所在集合,染成第一个元素的颜色:
(1) 紫色和黄色,染成粉色;
(2) 青色,染成蓝色;
最终,剩余三种颜色,也就是三个集合:
- s1={0,1,3,5,8}
- s3={2,9}
- s4={4,6,7}
神奇不神奇!!!
染色法有意思么?但仍有两个遗留问题:
(1) 粉色1,紫色1,黄色1,三个元素如何找到这三个元素所在的集合s1s2s6呢?
(2) s1s2s6三个集合如何快速合并?
画外音:假设总元素个数n=M*N,如果使用树形set,合并的复杂度为O(n*lg(n)),即O(M*N*lg(M*N))。
我们继续往下看。
第四部分:链表法
染色法遗留了两个问题:
- 步骤(2)中,如何通过元素快速定位集合?
- 步骤(3)中,如何快速合并集合?
我们继续聊聊这两个问题的优化思路。
问题一:如何由元素快速定位集合?
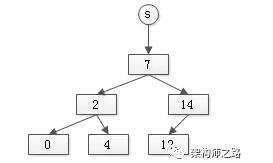
普通的集合,只能由集合根(root)定位元素,不能由元素逆向定位root,如何支持元素逆向定位root呢?
很容易想到,每个节点增加一个父指针即可。
更具体的:
- element{
- int data;
- element* left;
- element* right;
- }
升级为:
- element{
- element* parent; // 指向父节点
- int data;
- element* left;
- element* right;
- }
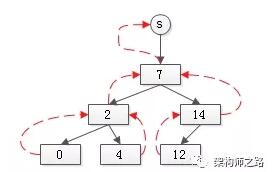
如上图:所有节点的parent都指向它的上级,而只有root->parent=NULL。
对于任意一个元素,找root的过程为:
- element* X_find_set_root(element* x){
- element* temp=x;
- while(temp->parent != NULL){
- temptemp= temp->parent;
- }
- return temp;
- }
很容易发现,由元素找集合根的时间复杂度是树的高度,即O(lg(n))。
有没有更快的方法呢?
进一步思考,为什么每个节点要指向父节点,直接指向根节点是不是也可以。
更具体的:
- element{
- int data;
- element* left;
- element* right;
- }
升级为:
- element{
- element* root; // 指向集合根
- int data;
- element* left;
- element* right;
- }
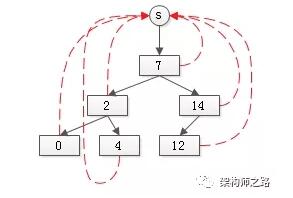
如上图:所有节点的parent都指向集合的根。
对于任意一个元素,找root的过程为:
- element* X_find_set_root(element* x){
- return x->root;
- }
很容易发现,升级后,由元素找集合根的时间复杂度是O(1)。
画外音:不能更快了吧。
另外,这种方式,能在O(1)的时间内,判断两个元素是否在同一个集合内:
- bool in_the_same_set(element* a, element* b){
- return (a->root == b->root);
- }
甚为方便。
画外音:两个元素的根相同,就在同一个集合内。
问题二:如何快速进行集合合并?
暴力法中提到过,集合合并的伪代码为:
- merge(set(i), set(j)){
- foreach(element in set(i))
- set(j).insert(element);
- }
把一个集合中的元素插入到另一个集合中即可。
假设set(i)的元素个数为n1,set(j)的元素个数为n2,其时间复杂度为O(n1*lg(n2))。
在“微信群覆盖”这个业务场景下,随着集合的不断合并,集合高度越来越高,合并会越来越慢,有没有更快的集合合并方式呢?
仔细回顾一下:
(1) 树形set的优点是,支持有序查找,省空间;
(2) 哈希型set的优点是,快速插入与查找;
而“微信群覆盖”场景对集合的频繁操作是:
(1) 由元素找集合根;
(2) 集合合并;
那么,为什么要用树形结构或者哈希型结构来表示集合呢?
画外音:优点完全没有利用上嘛。
让我们来看看,这个场景中,如果用链表来表示集合会怎么样,合并会不会更快?
- s1={7,3,1,4}
- s2={1,6}
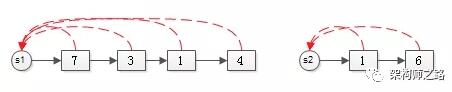
如上图,分别用链表来表示这两个集合。可以看到,为了满足“快速由元素定位集合根”的需求,每个元素仍然会指向根。
s1和s2如果要合并,需要做两件事:
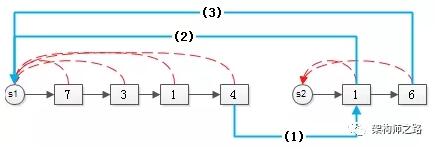
- 集合1的尾巴,链向集合2的头(蓝线1);
- 集合2的所有元素,指向集合1的根(蓝线2,3);
合并完的效果是:

变成了一个更大的集合。
假设set(1)的元素个数为n1,set(2)的元素个数为n2,整个合并的过程的时间复杂度是O(n2)。
画外音:时间耗在set(2)中的元素变化。
咦,我们发现:
(1) 将短的链表,接到长的链表上;
(2) 将长的链表,接到短的链表上;
所使用的时间是不一样的。
为了让时间更快,一律使用更快的方式:“元素少的链表”主动接入到“元素多的链表”的尾巴后面。这样,改变的元素个数能更少一些,这个优化被称作“加权合并”。
对于M个微信群,平均每个微信群N个用户的场景,用链表的方式表示集合,按照“加权合并”的方式合并集合,最坏的情况下,时间复杂度是O(M*N)。
画外音:假设所有的集合都要合并,共M次,每次都要改变N个元素的根指向,故为O(M*N)。
于是,对于“M个群,每个群N个用户,微信群求覆盖”问题,使用“染色法”加上“链表法”,核心思路三步骤:
(1) 全部元素全局排序;
(2) 全局排序后,不同集合中的相同元素,一定是相邻的,通过相同相邻的元素,一次性找到所有需要合并的集合;
(3) 合并这些集合,算法完成;
其中:
- 步骤(1),全局排序,时间复杂度O(M*N);
- 步骤(2),染色思路,能够迅猛定位哪些集合需要合并,每个元素增加一个属性指向集合根,实现O(1)级别的元素定位集合;
- 步骤(3),使用链表表示集合,使用加权合并的方式来合并集合,合并的时间复杂度也是O(M*N);
总时间复杂度是:
- O(M*N) //排序
- +
- O(1) //由元素找到需要合并的集合
- *
- O(M*N) //集合合并
神奇不神奇!!!
神奇不止一种,还有其他方法吗?我们接着往下看。
第五部分:并查集法
分离集合(disjoint set)是一种经典的数据结构,它有三类操作:
- Make-set(a):生成一个只有一个元素a的集合;
- Union(X, Y):合并两个集合X和Y;
- Find-set(a):查找元素a所在集合,即通过元素找集合;
这种数据结构特别适合用来解决这类集合合并与查找的问题,又称为并查集。
能不能利用并查集来解决求“微信群覆盖”问题呢?
一、并查集的链表实现
链表法里基本聊过,为了保证知识的系统性,这里再稍微回顾一下。

如上图,并查集可以用链表来实现。
链表实现的并查集,Find-set(a)的时间复杂度是多少?
集合里的每个元素,都指向“集合的句柄”,这样可以使得“查找元素a所在集合S”,即Find-set(a)操作在O(1)的时间内完成。
链表实现的并查集,Union(X, Y)的时间复杂度是多少?
假设有集合:
- S1={7,3,1,4}
- S2={1,6}
合并S1和S2两个集合,需要做两件事情:
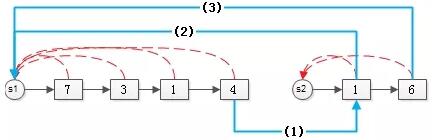
(1) 第一个集合的尾元素,链向第二个集合的头元素(蓝线1);
(2) 第二个集合的所有元素,指向第一个集合的句柄(蓝线2,3);
合并完的效果是:
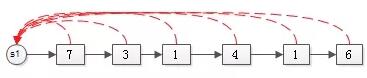
变成了一个更大的集合S1。
集合合并时,将短的链表,往长的链表上接,这样变动的元素更少,这个优化叫做“加权合并”。
画外音:实现的过程中,集合句柄要存储元素个数,头元素,尾元素等属性,以方便上述操作进行。
假设每个集合的平均元素个数是n,Union(X, Y)操作的时间复杂度是O(n)。
能不能Find-set(a)与Union(X, Y)都在O(1)的时间内完成呢?
可以,这就引发了并查集的第二种实现方法。
二、并查集的有根树实现
什么是有根树,和普通的树有什么不同?
常用的set,就是用普通的二叉树实现的,其元素的数据结构是:
- element{
- int data;
- element* left;
- element* right;
- }
通过左指针与右指针,父亲节点指向儿子节点。
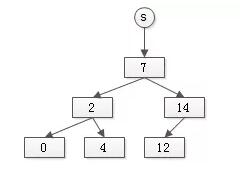
而有根树,其元素的数据结构是:
- element{
- int data;
- element* parent;
- }
通过儿子节点,指向父亲节点。
假设有集合:
- S1={7,3,1,4}
- S2={1,6}
通过如果通过有根树表示,可能是这样的:
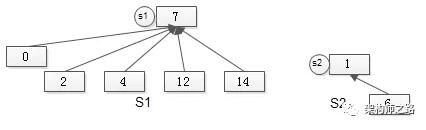
所有的元素,都通过parent指针指向集合句柄,所有元素的Find-set(a)的时间复杂度也是O(1)。
画外音:假设集合的首个元素,代表集合句柄。
有根树实现的并查集,Union(X, Y)的过程如何?时间复杂度是多少?
通过有根树实现并查集,集合合并时,直接将一个集合句柄,指向另一个集合即可。
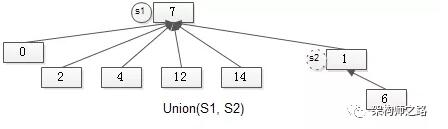
如上图所示,S2的句柄,指向S1的句柄,集合合并完成:S2消亡,S1变为了更大的集合。
容易知道,集合合并的时间复杂度为O(1)。
会发现,集合合并之后,有根树的高度变高了,与“加权合并”的优化思路类似,总是把节点数少的有根树,指向节点数多的有根树(更确切的说,是高度矮的树,指向高度高的树),这个优化叫做“按秩合并”。
新的问题来了,集合合并之后,不是所有元素的Find-set(a)操作都是O(1)了,怎么办?
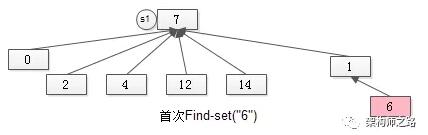
如图S1与S2合并后的新S1,首次“通过元素6来找新S1的句柄”,不能在O(1)的时间内完成了,需要两次操作。
但为了让未来“通过元素6来找新S1的句柄”的操作能够在O(1)的时间内完成,在首次进行Find-set(“6”)时,就要将元素6“寻根”路径上的所有元素,都指向集合句柄,如下图。
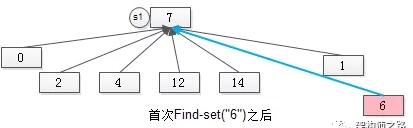
某个元素如果不直接指向集合句柄,首次Find-set(a)操作的过程中,会将该路径上的所有元素都直接指向句柄,这个优化叫做“路径压缩”。
画外音:路径上的元素第二次执行Find-set(a)时,时间复杂度就是O(1)了。
实施“路径压缩”优化之后,Find-set的平均时间复杂度仍是O(1)。
稍微总结一下。
通过链表实现并查集:
(1) Find-set的时间复杂度,是O(1)常数时间;
(2) Union的时间复杂度,是集合平均元素个数,即线性时间;
画外音:别忘了“加权合并”优化。
通过有根树实现并查集:
(1) Union的时间复杂度,是O(1)常数时间;
(2) Find-set的时间复杂度,通过“按秩合并”与“路径压缩”优化后,平均时间复杂度也是O(1);
即,使用并查集,非常适合解决“微信群覆盖”问题。
知其然,知其所以然,思路往往比结果更重要。
算法,其实还是挺有意思的。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】

















