













人的适应能力是很可怕的!盲人尽管无法用眼睛看到世界,但通过练习,盲杖就是他的眼睛。那神经网络的眼睛如果只能看到混乱的世界,那它会习惯吗?Google Brain在NeurIPS 2021的spotlight paper最近就研究了这个问题,将输入图像随机打乱,发现强化学习得到的agent仍然能够正确决策!
人类的感官能力实际上是非常惊人的。
著名的神经科学家Paul Bach-y-Rita曾对使用盲杖的盲人进行了细致的观察和研究。
他发现,盲人在行走时会前后扫动盲杖,盲杖的尖端经由皮肤上的触觉感受体来告诉盲人路况信息。
Bach-y-Rita从而备受启发。
他认为盲杖可以看作是盲人和物体之间的「接口」,通过盲杖在手上的压力触感,能够反馈给盲人形成诸如房间摆设这样的空间信息。

因此,手上的皮肤及其触觉感受体,就像一个信息收集站,可以替代视网膜在大脑中形成图像。
你无需用眼睛看,也无需用耳朵听,真正的看和听都在大脑里!
这种适应性也被称为感官替代(sensory substitution),也是神经科学中非常著名的一个现象。
但一些困难的适应性也需要几周、几个月甚至几年的练习才能做到,例如调整习惯看东西的角度,学习骑反向(backwards)的自行车等等。

相比之下,大多数神经网络根本无法产生感官替代的现象。
例如,大多数强化学习(RL)模型要求模型的输入必须采用预先指定好的格式。这些格式限制了输入向量的长度是固定的,并已经事先确定好输入的每个元素的精确含义,例如指定位置的像素强度,状态信息,位置或速度等。
在一些流行的RL基准任务(如Ant或Cart-Pole)中,如果模型的输入发生变化,或者如果向模型提供了与手头任务无关的额外噪声输入,那么使用当前RL算法训练的agent 将无法继续使用。
针对这个问题,Google在NeurIPS 2021上发表了一篇焦点论文,探索了具有排列不变性(permutation invariant)的神经网络模型。
这种神经网络要求每个感觉神经元(接收来自环境的感官输入的神经元)必须能够根据输入信号的上下文来找到信号的真正含义,而非明确地指定一个固定的含义。实验结果表明,这些没有预先指定的agent有能力对含有额外冗余或噪声信息以及损坏的、不完整的观察输入进行处理。

https://arxiv.org/abs/2109.02869
Permutation Invariant指的是特征之间没有空间位置关系,即使输入的顺序发生变化也不会影响输出结果。如在多层感知机中,改变像素的位置对最后的结果没有影响,但对卷积网络而言,特征之间则有空间位置关系。
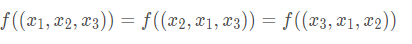
除了适应状态观测环境中的感官替代,研究还表明,这些agent还可以适应复杂视觉观测环境中的感官替代。
例如在CarRacing游戏,当输入图像的流不断地被reshuffle时,尽管人眼已经看不出来画面,但AI仍然可以做出正确的行动。

论文的作者Yujin Tang于2007年获得上海交通大学计算机专业学士学位,后于2010年获得早稻田大学硕士学位,主要专注于强化学习和机器人学的研究,并热衷于将相关技术应用于现实世界的问题。
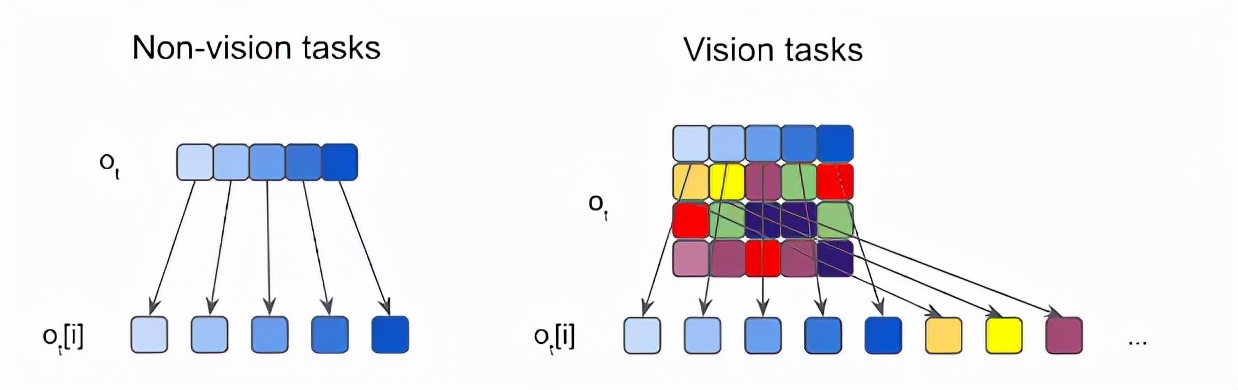
文中提出的研究方法在每个时间步中从环境中进行观察,并将观察的每个元素馈送成明确(distinct)但相同的(identiccal)神经网络,也称为感觉神经元(sensory neurons),网络之间彼此没有固定的关系。
每个感觉神经元仅通过其特定的感觉输入通道与时间信息进行集成。因为每个感觉神经元只能接收整个图片的一小部分,所以他们需要通过互相通信来自组织(self-organize)信息结构以便进行全局且连贯(coherent)的决策行为。
在实验中,研究人员也通过训练的方式促使神经元使用广播消息(broadcast messages)来互相沟通。
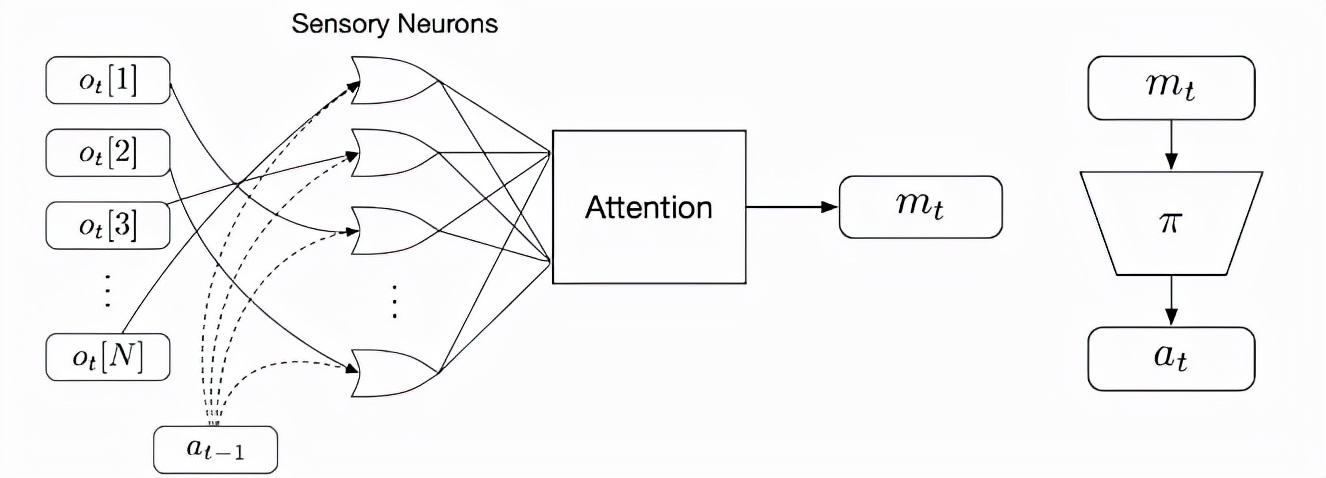
在接收局部信息时,每个感觉神经元在每个时间步骤中也需要连续广播输出消息。使用类似于在Transformer 架构中用到的注意力机制,就能够将这些消息整合并组合到输出矢量中,并称之为全局潜码。
然后,策略网络使用全局潜码来生成agent 的下一步与环境交互的行动(action)。行动结束后,通信循环将关闭。
你可能还有一个问题,为什么这个系统的输入排列变化对模型输出没有影响?
因为每个感觉神经元都是同一个(identical)神经网络,它们并不局限于处理来自某一特定感觉输入的信息,实际上每个感觉神经元的输入都没有定义。
相反,每个神经元必须通过关注其他感觉神经元接收到的输入来找到自己输入信号的含义。
这个操作也会促进agent将整个输入作为一个未排序的集合进行处理,从而使系统对其输入保持不变。
此外,训练后的agent可以根据实际需要,使用多个感觉神经元来处理任意长度的输入。
实验结果上,研究人员在简单的状态观测环境中证明了这种方法的鲁棒性和灵活性。
在常见的Ant locomotion任务中的agent总共需要接收28个输入,其中包含位置和速度信息等。研究人员多次打乱输入向量的顺序,实验仍然表明训练后的agent能够快速适应不同排列的输入,并且仍然能够在游戏中始终保持向前移动。
在cart-pole实验中,agent的目标是摆动安装在手推车中心的手推车杆,并使其保持向上平衡。
通常情况下,agent只能看到五个输入,但研究人员修改了实验环境来提供15个混合输入信号,其中10个是纯噪声,剩下的是环境的实际观察结果。
结果表明,agent仍然能够高效地执行任务,这也展现了该系统处理大量带噪声输入的能力,并且agent可以只使用它认为有用的信息通道。
研究人员还将这种方法应用于高维视觉环境,其中模型输入是图像的像素流。实验主要研究了基于视觉的RL环境的screen-shuffled版本,其中每个观察帧被划分为一个patch网格,看起来就像一个迷宫一样,agent必须以shuffed order的方式处理patch以确定要下一步要采取的动作。

实验中,研究人员给agent一个随机的屏幕上的patch样本,然后游戏的其余部分保持不变。
结果发现模型仍然可以在这些固定的随机位置分辨出70%的patch,并且仍然能够在对阵内置的Atari对手时不落下风。
有趣的是,如果研究人员随后向agent 透露额外的信息,即允许它获取更多的图像patch,即使没有额外的训练,它的性能也会提高。
当agent接收到所有patch时,即便按随机顺序,它也能100%对阵内置AI时获得胜利。
并且这些操作虽然在训练过程中增加了一些学习难度,但也会有带来额外的好处,例如提高了模型的泛化性,即便更换了新的图像取代了训练时的环境背景,agent依然可以正常运行。
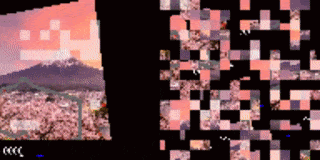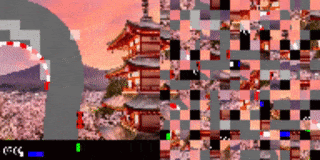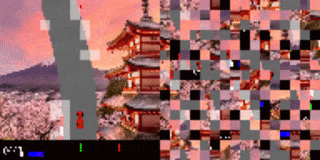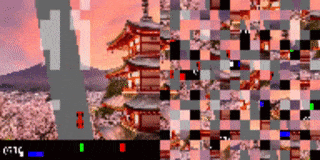
作者认为,由于不限制输入并且能过滤大量噪声,这种permutation invariant 神经网络将会极大促进强化学习的发展。


























