本文转载自微信公众号「前端万有引力」,作者一川 。转载本文请联系前端万有引力公众号。
1写在前面
浏览器引擎是如何编译、执行JS代码的呢?
本文将分析浏览器引起对JS代码的编译情况,并结合实际开发经验,重新理解底层的编译解析机制,将有助于理解前端开发在跨端中的应用以及一套代码生成多端的底层逻辑。那么:
- Javascript代码被执行分为几个阶段呢?
- AST到底是做什么用的?
2V8引擎
我们知道程序语言分为编译型语言和解释型语言,他们各自的特点是:
- 编译型语言:在代码执行前编译器直接将对应的代码转换为机器码。如C++
- 解释型语言:先将代码转换为编译型代码,再转为机器码,其是在运行时转换的。如:Python、Javascript
为了提高运行效率,很多浏览器厂商在不断努力,在现代浏览器中Chrome的v8引擎是最出类拔萃的,引入了Java虚拟机和C++编译器的众多技术。也正因此,Node.js也是基于V8引擎开发的。
那么v8引擎执行JS代码需要经历哪些阶段,如下:
- Parse阶段:v8引擎负责将JS代码转换为AST(抽象语法树)
- Ignition阶段:解释器将AST转换为字节码,解析执行字节码,同时为下阶段优化编译提供需要的信息
- TurboFan阶段:编译器利用上个阶段收集的信息,将字节码优化为可以执行的机器码
- Orinoco阶段:垃圾回收阶段,将程序中不再使用的内存空间进行回收
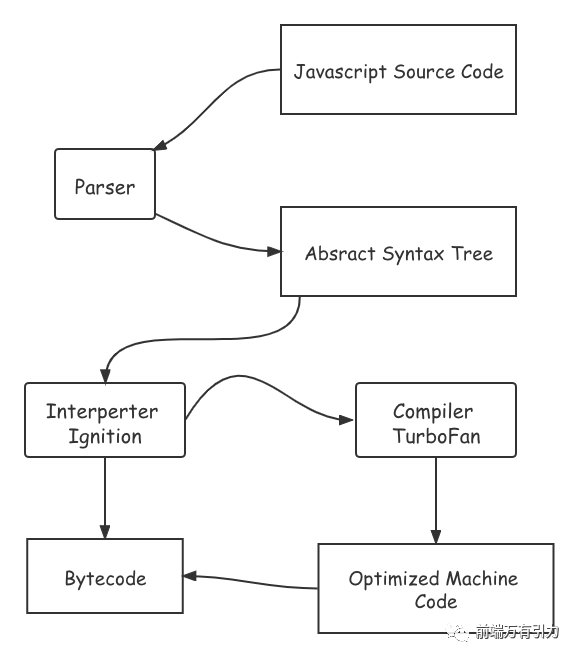
编译、执行流程图
AST
在计算机科学中,抽象语法树(abstract syntax tree 或者缩写为 AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。
在开发生产中,我们经常使用eslint和babel这些工具都和AST有联系,v8引擎就是通过编译器将源代码解析为AST的。常见的应用场景有:
- JS反编译,语法解析
- Babel编译ES6语法
- 代码高亮
- 关键字匹配
- 代码压缩
生成AST有两个关键:词法分析和语法分析 语法分析:这个阶段会将源代码拆分成最小的、不可再分的词法单元,称为token,代码中的空格在JS中是直接忽略的。词法单元之间都是独立的,也即在该阶段我们并不关心每一行代码是通过什么方式组合在一起的。

语法分析:这个过程是将词法单元转换成一个由元素逐级嵌套所组成的待料了程序语法结构的树,被称为抽象语法树。将上一阶段生成的 token 列表转换为如下图右侧所示的 AST,根据这个数据结构大致可以看出转换之前源代码的基本构造。

简而言之,词法分析阶段就是将代码拆解成独立的、不可再分的tokens,而语法分析阶段就是将拆分后的tokens进行解析,根据其在整个代码上下文中的作用和联系,去除多余的token形成抽象语法树。
浏览器还不支持es6语法,需要将其转换为es5语法,这个过程需要借助babel来实现。将es6源码解析成AST,再将es6语法的抽象语法树转为es5的抽象语法树,最后利用它来生成es5的源代码。
生成字节码
Ignition阶段就是将AST转换为字节码,但是之前的v8版本不会经历此过程,最早只是直接通过AST转成机器码,后面的版本才开始对其进行改进。将AST直接转为机器码是存在问题的,因为:
- 直接转换会带来内存占用过大的问题。因为将抽象语法树全部生成了机器码,而机器码相比字节码占用的内存更多
- 某些JS使用场景使用解释器更为合适。解析成字节码,有些代码没必要解析成机器码,进而可以减少占用大量的内存空间
V8引擎重新引进Ignition解释器,将抽象语法树转换成字节码后,内存占用显著降低,同时可以使用JIT编译器做进一步优化。
字节码是介于AST和机器码之间的代码,需要将其转换为机器码后才能执行,字节码可以理解为机器码的一种抽象。
解释器在得到AST后,会按需进行解释和执行,也就是说如果某个函数没有被调用,则不会去解释执行它。
解释器创建了调用栈来记录函数的调用流程,每调用一个函数,解释器就会把该函数添加进调用栈。解释器会为被添加进入的函数创建一个栈帧,这个栈帧是用来保存函数的局部变量以及执行语句,因此会立即执行这个栈帧。如果正在执行的函数还调用了其他函数,那么新函数也将会被添加进调用栈并执行,一旦这个函数执行结束,对应的栈帧就会被立即销毁。查看调用栈的方式有两种:调用函数console.log()打印到控制台,利用浏览器开发者工具进行断点调试。
生成机器码
如果发现一段代码被重复执行多次的情况,生成的字节码以及分析数据会传给TurboFan编译器,它会根据分析数据的情况生成优化好的机器码。
TurboFan编译器是JIT优化的编译器,TurboFan的编译线程和生成字节码不会在同一个线程上,这样可以和Ignition解释器相互配合着使用,不受另外一方的影响。由Ignition解释器收集的分析数据被TurboFan编译器使用,主要是通过一种推测优化的技术,生成已经优化的机器码进行执行。
优化后的机器码作用与缓存很类似,当解释器再次遇到相同的内容时,就可以直接执行优化后的机器码。当然优化后的代码有可能会无法运行(比如函数参数类型改变),那么会再次反优化为字节码交给解释器。
3参考文章
《Javascript核心原理精讲》
《前端也要懂编译:AST 从入门到上手指南》
《编译原理》
4写在最后
当前市面上比较主流的JS引擎编译过程大部分类似,主要原因可能是在某些地方加入了特定的优化,但是其核心思路和v8大体差不多。AST是比较重要的知识点,深入了解之后有助于自己实现前端工具。对此可以通过多研究一些前端工具,来提升自己的业务开发效率和编程能力。