













前言
写这种文章的初衷就是,在开发的过程中不知道怎么去选择,各种模式不是太充分了解。现在花点时间去找资料研究对比了一番,所以出此篇。
此篇以先以了解flink组件开始,再以简单模式Local 和 Standlone 正式进入正题。本篇主要是以Yarn 方式下三种模式展开细讲,当然还有Kubernetes方式(本篇不细说)。
组件
在了解提交模式之前,先了解一下Flink组件与组件之间的协作关系。
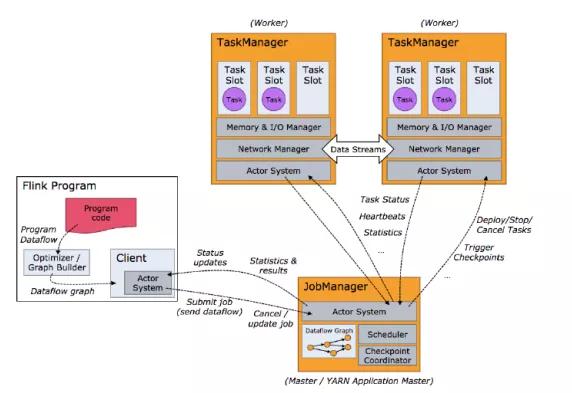
资源管理器(Resource Manager)
(1)主要负责管理任务管理器TaskManager的插槽slot。
(2) 当作业管理器JM申请插槽资源时, RM会将有空闲插槽的TM分配给JM。如果 RM没有足够的插槽来满足JM的请求。
(3)它还可以向资源提供平台发起会话,以提供启动 TM进程的容器。
作业管理器(JobManager)
(1) 控制一个应用程序执行的主进程,也就是说,每个应用程序 都会被一个不同的JM所控制执行。
(2) JM会先接收到要执行的应用程序,这个应用程序会包括:作业图(Job Graph)、逻辑数据流图( ogical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
(3) JM会把 Jobgraph转换成一个物理层面的 数据流图,这个图被叫做 “执行图”(Executiongraph),包含了所有可以并发执行的任务。Job Manager会向资源管理器( Resourcemanager)请求执行任务必要的资源,也就是 任务管理器(Taskmanager)上的插槽slot。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TM上。而在运行过程中JM会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
任务管理器(Taskmanager)
(1) Flink中的工作进程。通常在 Flink中会有多个TM运行, 每个TM都包含了一定数量的插槽slots。插槽的数量限制了TM能够执行的任务数量。
(2) 启动之后,TM会向资源管理器注册它的插槽;收到资源管理器的指令后, TM就会将一个或者多个插槽提供给JM调用。TM就可以向插槽分配任务tasks来执行了。
(3) 在执行过程中, 一个TM可以跟其它运行同一应用程序的TM交换数据。
分发器(Dispatcher)
(1)可以跨作业运行,它为应用提交提供了REST接口。
(2)当一个应用被提交执行时,分发器就会启动并将应用移交给JM。
(3)Dispatcher他会启动一个 WebUi,用来方便地 展示和监控作业执行的信息。
Local模式
JobManager 和 TaskManager 共用一个 JVM,只需要jdk支持,单节点运行,主要用来调试。
Standlone模式
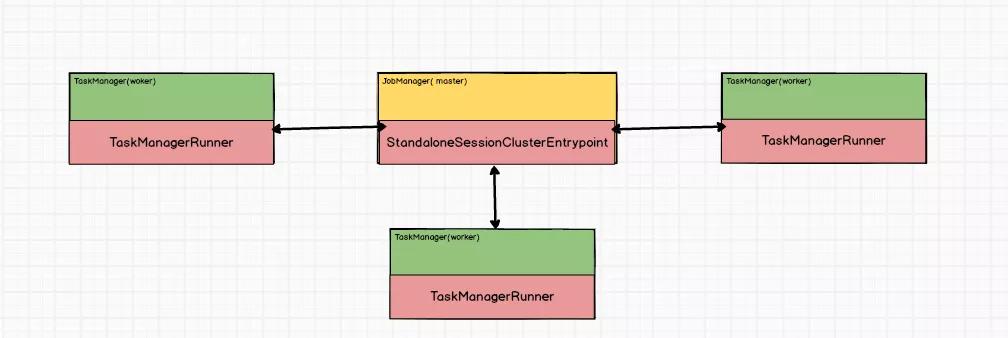
Standlone 是Flink自带的一个分布式集群,它不依赖其他的资源调度框架、不依赖yarn 等。
充当Master角色的是JobManager。
充当Slave/Worker角色是TaskManager
配置与启动
(1)conf 目录下有两个文件:masters 和 workers 指定地址。
(2)需要配置 conf/flink-conf.yaml 的自行配置。
(3)分发各个机器。
(4)启动集群 bin/start-cluster.sh
(5)提交任务 flink run
Yarn 模式
首先认识下提交流程
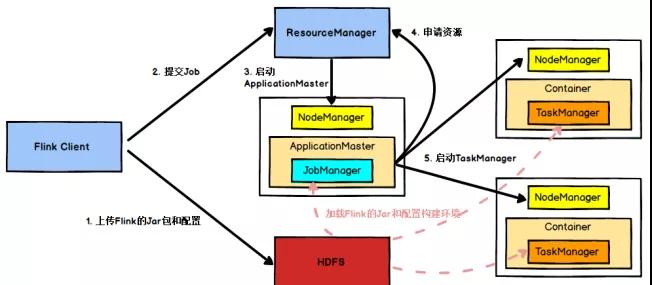
(1)提交App之前,先上传Flink的Jar包和配置到HDFS,以便JobManager和TaskManager共享HDFS的数据。
(2)客户端向ResourceManager提交Job,ResouceManager接到请求后,先分配container资源,然后通知NodeManager启动ApplicationMaster。
(3)ApplicationMaster会加载HDFS的配置,启动对应的JobManager,然后JobManager会分析当前的作业图,将它转化成执行图(包含了所有可以并发执行的任务),从而知道当前需要的具体资源。
(4)接着,JobManager会向ResourceManager申请资源,ResouceManager接到请求后,继续分配container资源,然后通知ApplictaionMaster启动更多的TaskManager(先分配好container资源,再启动TaskManager)。container在启动TaskManager时也会从HDFS加载数据。
(5)TaskManager启动后,会向JobManager发送心跳包。JobManager向TaskManager分配任务。
Session Mode
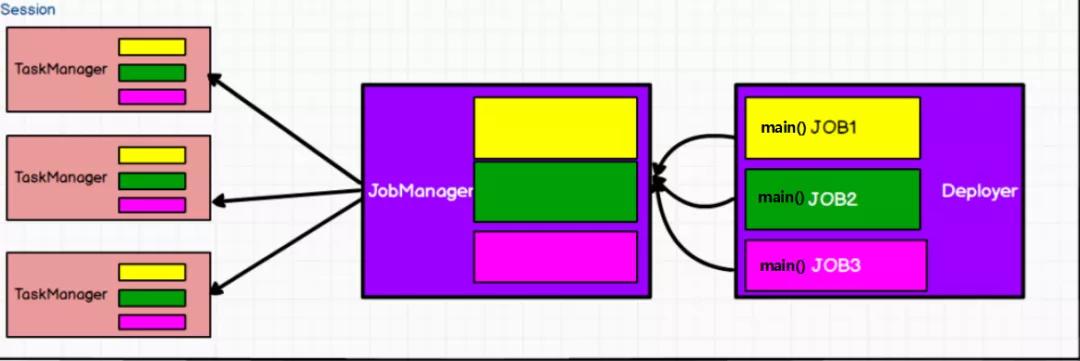
Session模式提前初始化好一个集群,然后向这个集群提交应用。所有应用都在同一个集群中执行,共享资源。这里JobManager仅有一个。提交到这个集群的作业可以直接运行。如图所示
Session模式共享Dispatcher 和 ResourceManager,作业共享集群资源。
Session多个作业之间又不是隔离的,如果有一个TaskManager挂掉,它上面承载着的所有作业也会失败。同样来说,启动的Job任务越多,JobManager的负载也就越大。
所以,Session模式适合生命周期短资源消耗低的场景。
提交
./bin/flink run -t yarn-session \
-Dyarn.application.id=application_XXXX_YY \
./examples/streaming/TopSpeedWindowing.jar
- 1.
- 2.
- 3.
Per-Job Cluster Mode
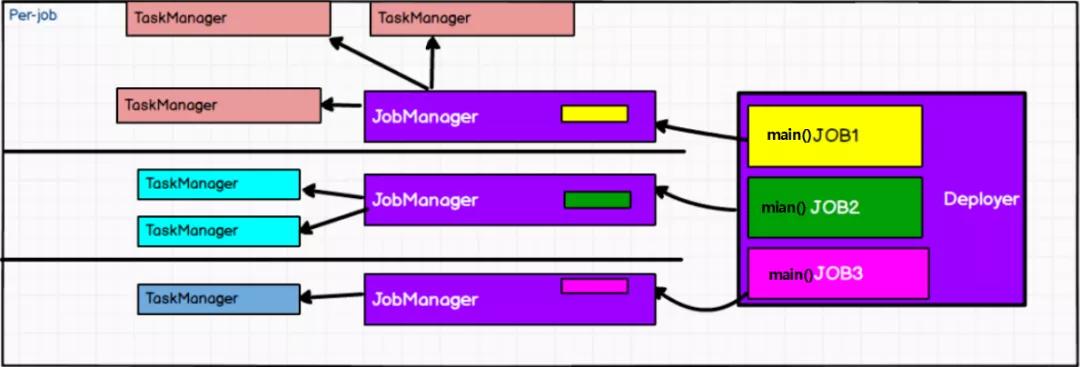
在Per-Job模式下,每个提交到YARN上的作业会有单独的Flink集群,拥有专属的JobManager和TaskManager。也即:一个作业一个集群,作业之间相互隔离。
以Per-Job模式提交作业的启动延迟可能会较高,因为不需要共享集群,所以在PipelineExecutor中执行作业提交的时候,创建集群并将JobGraph以及所需要的文件等一同提交给Yarn集群,进行一系列的初始化动作,这个时候需要些时间。提交任务的时候会把本地flink的所有jar包先上传到hdfs上相应的临时目录,这个也会带来大量的网络的开销。
优点就是作业之间的资源完全隔离,一个作业的TaskManager失败不会影响其他作业的运行,JobManager的负载也是分散开来的,不存在单点问题。当作业运行完成,与它关联的集群也就被销毁,资源被释放。
所以,Per-Job模式一般用来部署那些长时间运行的作业。
提交
/bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
- 1.
「其他操作」
# List running job on the cluster
./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
# Cancel running job
./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
- 1.
- 2.
- 3.
- 4.
Application Mode
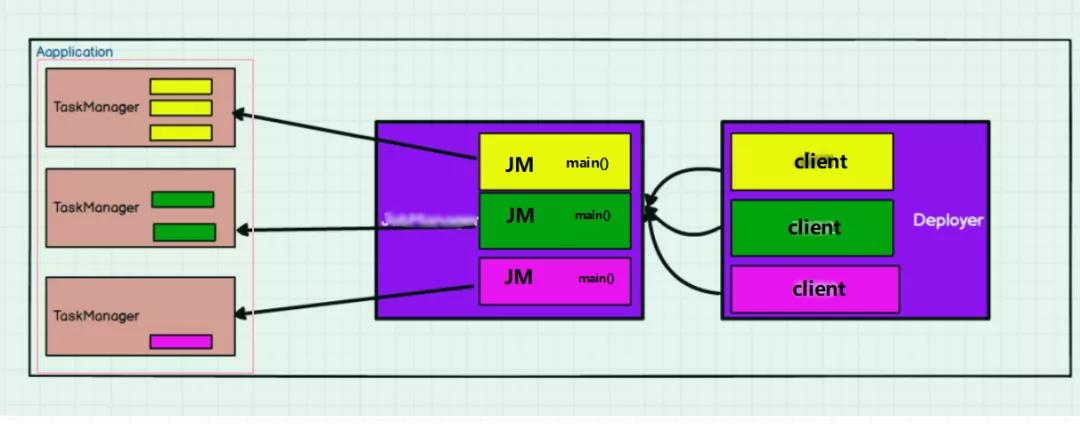
Application 模式尝试去将per-job 模式的资源隔离性和轻量级,可扩展的应用提交进程相结合。为了实现这个目的,它会每个Job 创建一个集群,但是 应用的main()将被在JobManager 执行。
Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在这种体系结构中Application模式在不同应用之间提供了资源隔离和负载平衡保证
在JobManager 中执行main()方法,可以节省所需的CPU周期。还有个好处就是,由于每个应用程序有一个JobManager,因此可以更平均地分散网络负载。
提交
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
- 1.
「其他操作」
# List running job on the cluster
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
# Cancel running job
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
- 1.
- 2.
- 3.
- 4.
Application mode中的多个job,实际在代码上的表现就是能够允许在一个Application里面调用多次execute/executeAsyc方法。但是execute方法会被阻塞,也就是只有一个job完成之后才能继续下一个job的execute,但是可以通过executeAsync进行异步非阻塞执行。
Yarn 模式总结
| 模式 | 生命周期 | 资源隔离 | 优点 | 缺点 | main方法 |
|---|---|---|---|---|---|
| Session | 关闭会话,才会停止 | 共用JM和TM | 预先启动,启动作业不再启动。资源充分共享 | 资源隔离比较差,TM不容易扩展 | 在客户端执行 |
| Per-job | Job停止,集群停止 | 单个Job独享JM和TM | 充分隔离,资源根据job按需申请 | job启动慢,每个job需要启动一个JobManager | 在客户端执行 |
| Application | 当Application全部执行完,集群才会停止 | Application使用一套JM和TM | Client负载低,Application之间实现资源隔离,Application内实现资源共享 | 对per-job模式和session模式的优化部署模式(优点) | 在Cluster中 |
























