HashMap 的遍历方法有很多种,不同的 JDK 版本有不同的写法,其中 JDK 8 就提供了 3 种 HashMap 的遍历方法,并且一举打破了之前遍历方法“很臃肿”的尴尬。
1.JDK 8 之前的遍历
JDK 8 之前主要使用 EntrySet 和 KeySet 进行遍历,具体实现代码如下。
1.1 EntrySet 遍历
EntrySet 是早期 HashMap 遍历的主要方法,其实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- for (Map.Entry<String, String> entry : map.entrySet()) {
- System.out.println(entry.getKey() + ":" + entry.getValue());
- }
- }
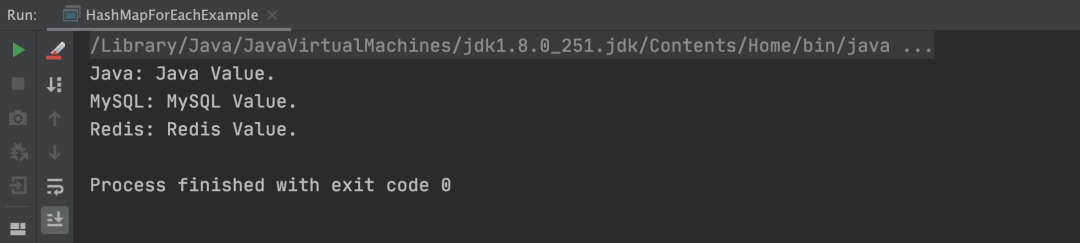
以上程序的执行结果,如下图所示:
1.2 KeySet 遍历
KeySet 的遍历方式是循环 Key 内容,再通过 map.get(key) 获取 Value 的值,具体实现如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- for (String key : map.keySet()) {
- System.out.println(key + ":" + map.get(key));
- }
- }
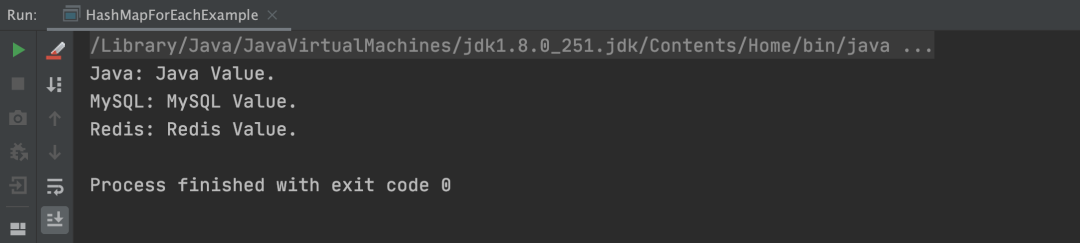
以上程序的执行结果,如下图所示:
KeySet 性能问题
通过以上代码,我们可以看出使用 KeySet 遍历,其性能是不如 EntrySet 的,因为 KeySet 其实循环了两遍集合,第一遍循环是循环 Key,而获取 Value 有需要使用 map.get(key),相当于有循环了一遍集合,所以 KeySet 循环不能建议使用,因为循环了两次,效率比较低。
1.3 EntrySet 迭代器遍历
EntrySet 和 KeySet 除了以上直接循环外,我们还可以使用它们的迭代器进行循环,如 EntrySet 的迭代器实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
- while (iterator.hasNext()) {
- Map.Entry<String, String> entry = iterator.next();
- System.out.println(entry.getKey() + ":" + entry.getValue());
- }
- }
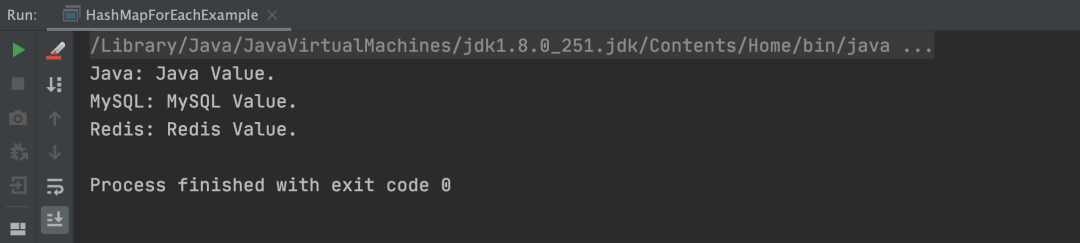
以上程序的执行结果,如下图所示:
1.4 KeySet 迭代器遍历
KeySet 也可以使用迭代器的方式进行遍历,实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- Iterator<String> iterator = map.keySet().iterator();
- while (iterator.hasNext()) {
- String key = iterator.next();
- System.out.println(key + ":" + map.get(key));
- }
- }
以上程序的执行结果,如下图所示:图片虽然 KeySet 循环方式不推荐使用,但还是有必要了解一下的。
1.5 迭代器的作用
既然能直接遍历,那为什么还要用迭代器呢?通过以下例子我们就知道了。
不使用迭代器删除
如果不使用迭代器,假如我们在遍历 EntrySet 时,在遍历代码中删除元素,代码的实现如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- for (Map.Entry<String, String> entry : map.entrySet()) {
- if ("Java".equals(entry.getKey())) {
- // 删除此项
- map.remove(entry.getKey());
- continue;
- }
- System.out.println(entry.getKey() + ":" + entry.getValue());
- }
- }
以上程序的执行结果,如下图所示:
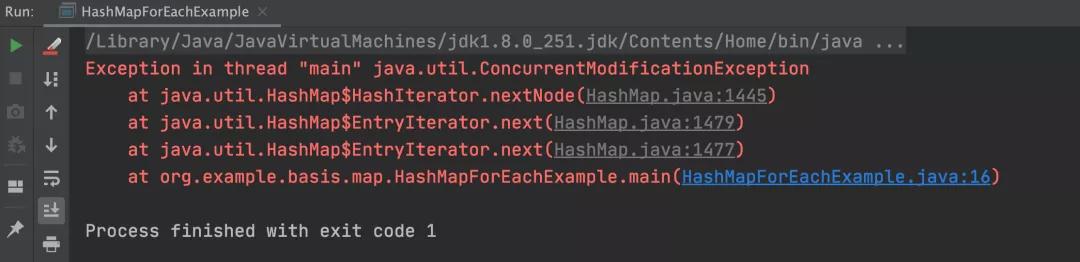
可以看到,如果在遍历的代码中动态删除元素,非迭代器的方式就会报错。
使用迭代器删除
接下来,我们使用迭代器循环 EntrySet,并且在循环中动态删除元素,实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
- while (iterator.hasNext()) {
- Map.Entry<String, String> entry = iterator.next();
- if ("Java".equals(entry.getKey())) {
- // 删除此项
- iterator.remove();
- continue;
- }
- System.out.println(entry.getKey() + ":" + entry.getValue());
- }
- }
以上程序的执行结果,如下图所示:图片从上述结果可以看出,使用迭代器的优点是可以在循环的时候,动态的删除集合中的元素。而上面非迭代器的方式则不能在循环的过程中删除元素(程序会报错)。
2.JDK 8 之后的遍历
在 JDK 8 之后 HashMap 的遍历就变得方便很多了,JDK 8 中包含了以下 3 种遍历方法:
- 使用 Lambda 遍历
- 使用 Stream 单线程遍历
- 使用 Stream 多线程遍历
我们分别来看。
2.1 Lambda 遍历
使用 Lambda 表达式的遍历方法实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- map.forEach((key, value) -> {
- System.out.println(key + ":" + value);
- });
- }
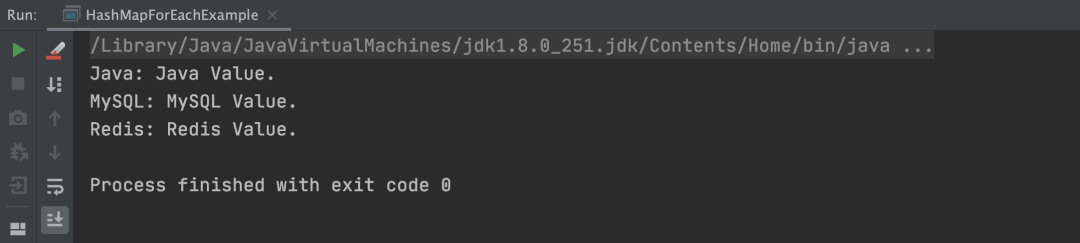
以上程序的执行结果,如下图所示:
2.2 Stream 单线程遍历
Stream 遍历是先得到 map 集合的 EntrySet,然后再执行 forEach 循环,实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- map.entrySet().stream().forEach((entry) -> {
- System.out.println(entry.getKey() + ":" + entry.getValue());
- });
- }
以上程序的执行结果,如下图所示:图片
2.3 Stream 多线程遍历
Stream 多线程的遍历方式和上一种遍历方式类似,只是多执行了一个 parallel 并发执行的方法,此方法会根据当前的硬件配置生成对应的线程数,然后再进行遍历操作,实现代码如下:
- public static void main(String[] args) {
- // 创建并赋值 hashmap
- HashMap<String, String> map = new HashMap() {{
- put("Java", " Java Value.");
- put("MySQL", " MySQL Value.");
- put("Redis", " Redis Value.");
- }};
- // 循环遍历
- map.entrySet().stream().parallel().forEach((entry) -> {
- System.out.println(entry.getKey() + ":" + entry.getValue());
- });
- }
以上程序的执行结果,如下图所示:
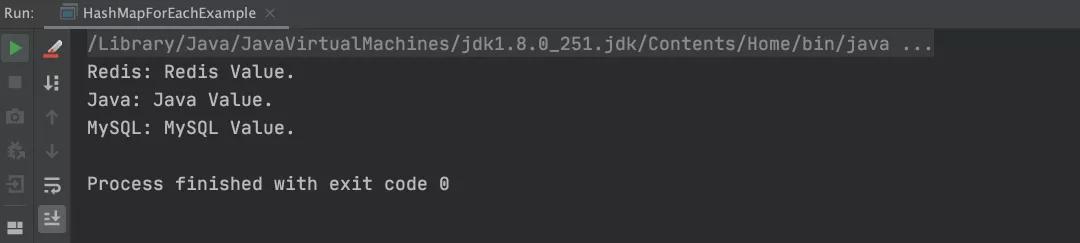
注意上述图片的执行结果,可以看出当前执行结果和之前的所有遍历结果都不一样(打印元素的顺序不一样),因为程序是并发执行的,所以没有办法保证元素的执行顺序和打印顺序,这就是并发编程的特点。
推荐使用哪种遍历方式?
不同的场景推荐使用的遍历方式是不同的,例如,如果是 JDK 8 之后的开发环境,推荐使用 Stream 的遍历方式,因为它足够简洁;而如果在遍历的过程中需要动态的删除元素,那么推荐使用迭代器的遍历方式;如果在遍历的时候,比较在意程序的执行效率,那么推荐使用 Stream 多线程遍历的方式,因为它足够快。所以这个问题的答案是不固定的,我们需要知道每种遍历方法的优缺点,再根据不同的场景灵活变通。
总结
本文介绍了 7 种 HashMap 的遍历方式,其中 JDK 8 之前主要使用 EntrySet 和 KeySet 的遍历方式,而 KeySet 的遍历方式性能比较低,一般不推荐使用。然而在 JDK 8 之后遍历方式就有了新的选择,可以使用比较简洁的 Lambda 遍历,也可以使用性能比较高的 Stream 多线程遍历。
本文转载自微信公众号「Java面试真题解析」,可以通过以下二维码关注。转载本文请联系Java面试真题解析公众号。