












讲真,我今年的双十一有点“背”,负责的Kafka集群出了一些幺蛾子,但正是这些幺蛾子,让我这个双十一过的非常充实,也让我意识到如果不体系化学习Kafka,是无法做到生产集群及时预警,将故障扼杀在摇篮中,因此也下定决心研读Kafka的内核。
本文就先来分享一个让我始料未及的故障:Kafka生产环境大面积丢失消息。
首先要阐述的是消息丢失并不是因为断电,而且集群的副本数量为3,消息发送端设置的acks=-1(all)。
这样严苛的设置,那为什么还会出现消息丢失呢?请听笔者慢慢道来。
1、故障现象
故障发生时,接到多个项目组反馈说消费组的位点被重置到几天前了,截图如下:

从上面的消费组延迟监控曲线上来看,一瞬间积压数从零直接飙升,初步怀疑是位点被重置了。
那位点为什么会被重置呢?
什么?你这篇文章不是说要讲Kafka为什么会丢消息吗?怎么你又扯说消费组位点被重置呢?标题党!!!
NO、NO、NO,各位看官,绝对不是文不对题,请带着这个疑问,与我共同探究吧。
2、问题分析
遇到问题,莫慌,讲道理,基于MQ的应用,消费端一般都会实现幂等,也就是消息可以重复被处理,并且不会影响业务,故解决的方式就是请项目组先评估一下,先人工将位点设置到出现问题的前30分钟左右,快速止血。
一波操作猛如虎,接下来就得好好分析问题产生的原因。
通过查看当时Kafka服务端的日志(server.log),可以看到如下日志:

上面的日志被修改的“面目全非”,其关键日志如下:
- Member consumer-1-XX in group consumerGroupName has failed, removing it from the group
- Preparing to rebalance group XXXX on heartbeat expiration
上面的日志指向性非常明显:由于心跳检测过期,消费组协调器将消费者从消费组中移除,重而触发重平衡。
消费组重平衡:当主题分区数量或消费者数量发生变化后,消费者之间需要对分区进行重新分配,实现消费端端负载均衡。
消息消费者在重平衡期间消费会全部暂停,当消费者重新完成分区的负载均衡后,继续从服务端拉起消息,此时消费端并不知道从哪个位置开始,故需要从服务端查询位点,使得消费者能从上次消费的位点继续消费。
现在出现消费位点被重置到最早位点,可以理解为位点丢失?那为什么会丢失位点呢?
无外乎如下两个原因:
- 服务端丢失位点,导致客户端无法查询到位点
- 客户端主动向服务端提交了-1,导致位点丢失
目前我们公司使用的Kafka版本为2.2.x,消费组的位点是存储在一个系统主题(__consumer_offsets)中,无论是服务器级别还是Topic级别,参数unclean.leader.election.enable都是设置为false,表示只有ISR集合中的副本才能参与Leader选举,这样就能严格保证位点消息并不会丢失或回到历史某一个位点。
查看客户端提交位点的API,发现用于封装客户端位点的实体类会对位点进行校验,代码截图如下:
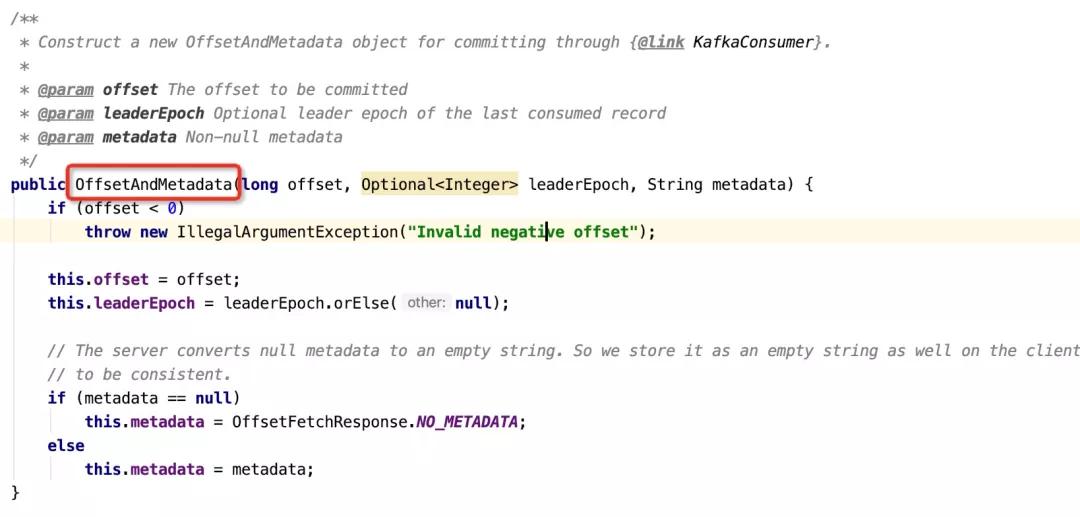
如果传入的位点为-1,直接会抛出异常,故客户端并没有机会向服务端提交-1的位点,那位点为什么会丢失呢?
为了进一步探究,我们不得不将目光投向消费组在初次时是如何获取位点,从源码的角度去分析,从而寻找关键日志,并对日志文件进行对照,尝试得到问题的解。
2.1 客户端位点查找机制
为了探究客户端的位点获取机制,笔者详细阅读了消费者在启动时的流程,具体入口为KafkaConsumer的poll方法,其详细流程图如下所示:
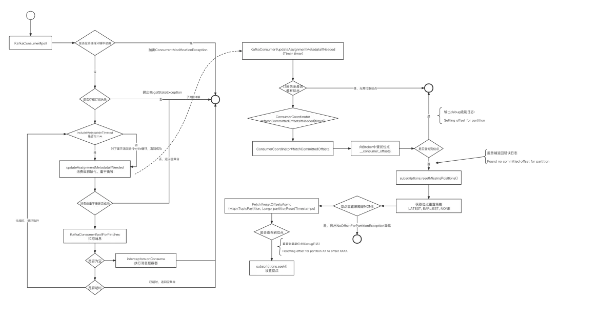
上述的核心要点说明如下:
- 在消费者(KafkaConsumer)的poll方法消息时会调用updateAssignmentMetadataIfNeeded方法,该方法主要执行消费组初始化、消费组重平衡、获取消费位点等与元数据相关工作。
- 如果当前消费组订阅的分区(重平衡后分配的分区)都存在位点,则返回true,说明无需更新位点。
- 如果当前存在分配的分区没有正确的位点(例如一次重平衡后新增加的分区),此时需要向服务端发送查找位点请求,服务端查询__consumer_offsets主题,返回位点信息。
- 如果查询到位点,输出DEBUG级别日志(Setting offset for partition),输出从服务端查询到的位点;如果未查询到位点,同样会输出DEBUG级别日志(Found no committed offset for partition)。
- 如果没有查询到位点,则需要根据消费组配置的位点重置策略,其具体配置参数:auto.offset.reset,其可选值:
- latest 最新位点
- earliest 最早位点
- none 不重置位点
- 如果重置位点选择的是none,则会抛出NoOffsetForPartitionException异常。
- 如果重置位点选择的是latest、earliest,则消费者将从查询到的位点开始消费,并输出DEBUG级别日志(Resetting offset for partition XX to offset XXXX.)
- 非常遗憾,消费者的位点查找机制,Kafka客户端打印的过程日志是DEBUG级别,这在生产环境基本是不会输出的,给我排查问题(找到足够的证据)带来了不便。
这里不得不吐槽一下Kafka输出日志的策略:位点的变更是一个非常关键的状态变更,而且输出这些日志的频率不会很大,日志级别应该使用INFO,而不是DEBUG。
Kafka的日志是Debug,故当时是无法找到证据进行辅助说明,只能排查出为什么会因为心跳超时而触发重平衡。
温馨提示:关于心跳为什么会超时,从而触发重平衡原因,将会在后续的故障分析相关的文章中详细阐述。
找到重平衡触发原因后,在测试环境进行压测并加以重现,同时将客户端日志级别设置为debug,从而查找证据,功夫不负有心人,完美的找到了上文中提到的三条日志:
- Setting offset for partition 第一次查询时找到了位点,并且不为-1,也不是最早位点。
- Found no committed offset for partition 后面反复进行重平衡,反复查询日志,竟然后面无法正确查询到位点,而是返回没有找到位点(返回-1)。
- Resetting offset for partition XX to offset XXXX. 根据重置策略进行了位点重置。
从上面的日志分析,也可以明确地出结论,服务端是有存储消费组的位点的,不然不会出现第一条日志,成功找到了一个有效的位点,只是在后续重平衡过程中,多次需要查询位点时,反而返回了-1,那服务端在什么情况下返回-1呢?
Broker服务端处理心跳包的入口是kafkaApis的handleOffsetFetchRequest方法,找到获取位点的关键代码,如下所示:
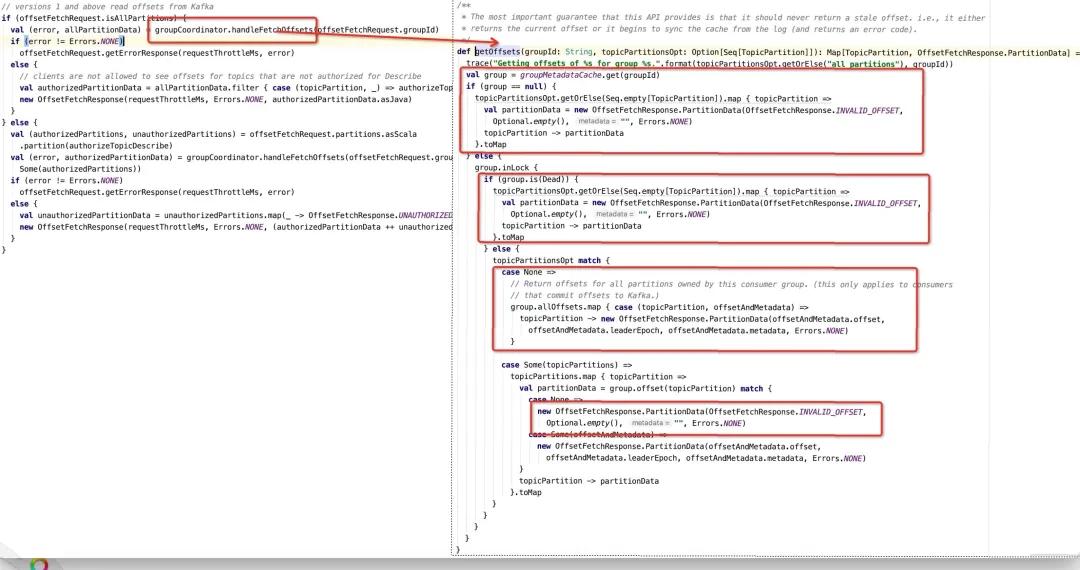
从上面来看,服务端返回INVALID_OFFSET = -1L的情况如下:
- 消费组元信息管理器中的缓存(内存)中并不存在该消费组,将返回-1,那又在什么情况下服务端会没有正在使用的消费组元信息呢?
- __consumer_offsets主题的分区发生Leader选举,当前Broker中拥有的分区变更为follower后,与该分区对应的消费组的元信息将被移除。为什么会这样呢?这里背后的原因是Kafka中的消费组在Broker端需要选举出一个组协调器,用于协调消费组的重平衡,选举算法就是将消费组的名称取hashcode,得到的值与 consumer_offsets主题的分区数取模得到一个分区数,然后该分区的Leader节点所在的Broker为该消费组的组协调器,故分区Leader发生变化,与之关联的消费组的组协调器需要重新选举。
- 删除消费组时将器移出。
- 消费组的状态为GroupState.Dead 消费组状态变更为Dead,通常有如下几种情况:
- 消费组被删除
- __consumer_offsets分区leader发生变化,触发位点重新加载,要先将消费组状态变更为Dead,然后新的分区Leader所在机器上会加载新的位点,然后引导消费组重平衡。
服务端中并没有存储该消费组的位点信息,说明该消费组还未提交过位点
那上面的情况,对于一个正在运行许久的消费组来说,上述这些情况会发生吗?查找服务端相关日志,可以明确看到大量__consumer_offsets相关分区发生leader选举,容易触发上述第一种情况,这样消费组发起的Offset Fetch请求是有可能返回-1,从而会引导消费组根据重置策略进行位点重置。

查看文章开头部分,消费组设置的重置策略选的是earliest,消费组在一瞬间消费积压从0飙升到几个亿,就能解释的通了。
看到这里,大家是不是会突然“后背发凉”,如果消费组配置的位点重置策略(auto.offset.reset)为latest,是不是很容易引起消息丢失,即一部分消费被跳过而不被消费,示意图说明如下:
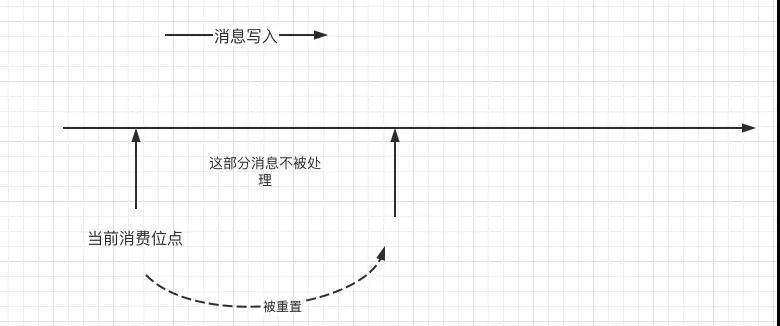
本文就说到这里了,关于Kafka集群为什么会出现大量__consumer_offsets进行Leader选举,后续文章会一一展开,敬请持续关注我。
3、感想
讲真,由于Kafka服务端使用的编程语言为scala,笔者并没有尝试去看Kafka的源码,只是详细剖析了Kafka的消息发送、消息消费机制,本以为可以轻松驾驭公司各个项目关于Kafka使用层面的问题,但事实上也是如此,对项目组的咨询我应对起来得心应手,但一旦服务端出现问题,还是会有点茫然,当然我们有一套完备的集群问题出现应急方案,但一旦出现问题,尽管你能快速恢复,但故障一旦发生,损失就无法避免,故我们还是要对自己负责的内容研究透,提前做好巡检、根据体系化的知识提前规避故障的发生。
正例如大部分朋友应该知道kafka在后续版本中的消费位点是存储在系统主题__consumer_offsets中,但又有多少人知道,这个主题的分区一旦出现Leader选举,伴随而来的是一大堆消费组全部发生重平衡,导致消费组停止消费呢?
故笔者将下定决心,好好阅读一下kafka服务端相关源码,成体系化理解Kafka,在工作中更好的驾驭Kafka,《Kafka原理与实战》专栏在路上,有兴趣的朋友可以点击文章前的标签加以关注。
最后,期待您的点赞,您的点赞也是我最大的动力,我们下回见。














