面向列存的DBMS新的选择
Hadoop从诞生已经十三年了,Hadoop的供应商争先恐后的为Hadoop贡献各种开源插件,发明各种的解决方案技术栈,一方面确实帮助很多用户解决了问题,但另一方面因为繁杂的技术栈与高昂的维护成本,Hadoop也渐渐地失去了原本属于他的市场。对于用户来说,一套高性能,简单化,可扩展的数据库产品能够帮助他们解决业务痛点问题。越来越多的人将目光锁定在列存的分布式数据库上。
ClickHouse简介
ClickHouse是由俄罗斯的第一大搜索引擎Yandex公司开源的列存数据库。令人惊喜的是,ClickHouse相较于很多商业MPP数据库,比如Vertica,InfiniDB有着极大的性能提升。除了Yandex以外,越来越多的公司开始尝试使用ClickHouse等列存数据库。对于一般的分析业务,结构性较强且数据变更不频繁,可以考虑将需要进行关联的表打平成宽表,放入ClickHouse中。
相比传统的大数据解决方案,ClickHouse有以下的优点:
·配置丰富,只依赖与Zookeeper
·线性可扩展性,可以通过添加服务器扩展集群
·容错性高,不同分片间采用异步多主复制
·单表性能极佳,采用向量计算,支持采样和近似计算等优化手段
·功能强大支持多种表引擎
StarRocks简介
StarRocks是一款极速全场景MPP企业级数据库产品,具备水平在线扩缩容,金融级高可用,兼容MySQL协议和MySQL生态,提供全面向量化引擎与多种数据源联邦查询等重要特性。StarRocks致力于在全场景OLAP业务上为用户提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。
相比于传统的大数据解决方案,StarRocks有以下优点:
·不依赖于大数据生态,同时外表的联邦查询可以兼容大数据生态
·提供多种不同的模型,支持不同维度的数据建模
·支持在线弹性扩缩容,可以自动负载均衡
·支持高并发分析查询
·实时性好,支持数据秒级写入
·兼容MySQL 5.7协议和MySQL生态
StarRocks与ClickHouse的功能对比
StarRocks与ClickHouse有很多相似之处,比如说两者都可以提供极致的性能,也都不依赖于Hadoop生态,底层存储分片都提供了主主的复制高可用机制。但功能、性能与使用场景上也有差异。ClickHouse在更适用与大宽表的场景,TP的数据通过CDC工具的,可以考虑在Flink中将需要关联的表打平,以大宽表的形式写入ClickHouse。StarRocks对于join的能力更强,可以建立星型或者雪花模型应对维度数据的变更。
大宽表vs星型模型
ClickHouse:通过拼宽表避免聚合操作
不同于以点查为主的TP业务,在AP业务中,事实表和维度表的关联操作不可避免。ClickHouse与StarRocks最大的区别就在于对于join的处理上。ClickHouse虽然提供了join的语义,但使用上对大表关联的能力支撑较弱,复杂的关联查询经常会引起OOM。一般我们可以考虑在ETL的过程中就将事实表与维度表打平成宽表,避免在ClickHouse中进行复杂的查询。
目前有很多业务使用宽表来解决多远分析的问题,说明了宽表确有其独到之处:
·在ETL的过程中处理好宽表的字段,分析师无需关心底层的逻辑就可以实现数据的分析
·宽表能够包含更多的业务数据,看起来更直观一些
·宽表相当于单表查询,避免了多表之间的数据关联,性能更好
但同时,宽表在灵活性上也带来了一些困扰:
·宽表中的数据可能会因为join的过程中存在一对多的情况造成错误数据冗余
·宽表的结构维护麻烦,遇到维度数据变更的情况需要重跑宽表
·宽表需要根据业务预先定义,宽表可能无法满足临时新增的查询业务
StarRocks:通过星型模型适应维度变更
可以说,拼宽表的形式是以牺牲灵活性为代价,将join的操作前置,来加速业务的查询。但在一些灵活度要求较高的场景,比如订单的状态需要频繁改变,或者说业务人员的自助BI分析,宽表往往无法满足我们的需求。此时我们还需要使用更为灵活的星型或者雪花模型进行建模。对于星型/雪花模型的兼容度上,StarRocks的支撑要比ClickHouse好很多。
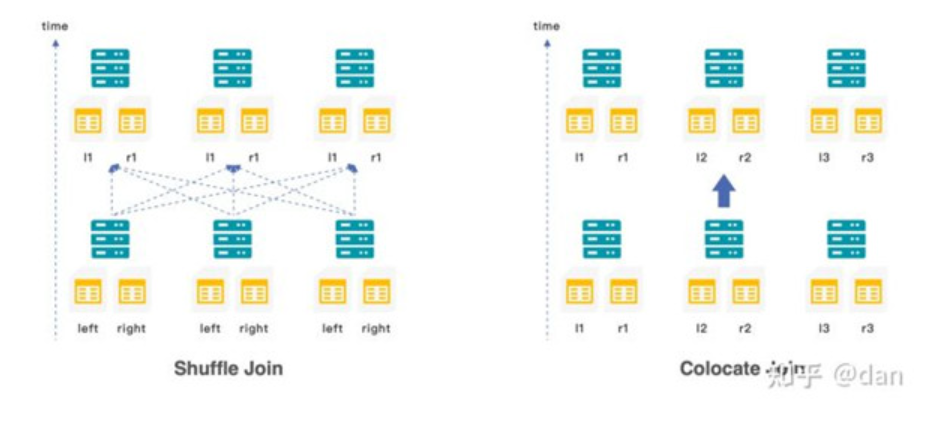
在StarRocks中提供了三种不同类型的join:
·当小表与大表关联时,可以使用boardcast join,小表会以广播的形式加载到不同节点的内存中
·当大表与大表关联式,可以使用shuffle join,两张表值相同的数据会shuffle到相同的机器上
·为了避免shuffle带来的网络与I/O的开销,也可以在创建表示就将需要关联的数据存储在同一个colocation group中,使用colocation join
目前大部分的MPP架构计算引擎,都采用基于规则的优化器(RBO)。为了更好的选择join的类型,StarRocks提供了基于代价的优化器(CBO)。用户在开发业务SQL的时候,不需要考虑驱动表与被驱动表的顺序,也不需要考虑应该使用哪一种join的类型,CBO会基于采集到的表的metric,自动的进行查询重写,优化join的顺序与类型。
高并发支撑
ClickHouse对高并发的支撑
为了更深维度的挖掘数据的价值,就需要引入更多的分析师从不同的维度进行数据勘察。更多的使用者同时也带来了更高的QPS要求。对于互联网,金融等行业,几万员工,几十万员工很常见,高峰时期并发量在几千也并不少见。随着互联网化和场景化的趋势,业务逐渐向以用户为中心转型,分析的重点也从原有的宏观分析变成了用户维度的细粒度分析。传统的MPP数据库由于所有的节点都要参与运算,所以一个集群的并发能力与一个节点的并发能力相差无几。如果一定要提高并发量,可以考虑增加副本数的方式,但同时也增加了RPC的交互,对性能和物理成本的影响巨大。
在ClickHouse中,我们一般不建议做高并发的业务查询,对于三副本的集群,通常会将QPS控制在100以下。ClickHouse对高并发的业务并不友好,即使一个查询,也会用服务器一半的CPU去查询。一般来说,没有什么有效的手段可以直接提高ClickHouse的并发量,只能考虑通过将结果集写入MySQL中增加查询的并发度。
StarRocks对高并发的支撑
相较于ClickHouse,StarRocks可以支撑数千用户同时进行分析查询,在部分场景下,高并发能力能够达到万级。StarRocks在数据存储层,采用先分区再分桶的策略,增加了数据的指向性,利用前缀索引可以快读对数据进行过滤和查找,减少磁盘的I/O操作,提升查询性能。
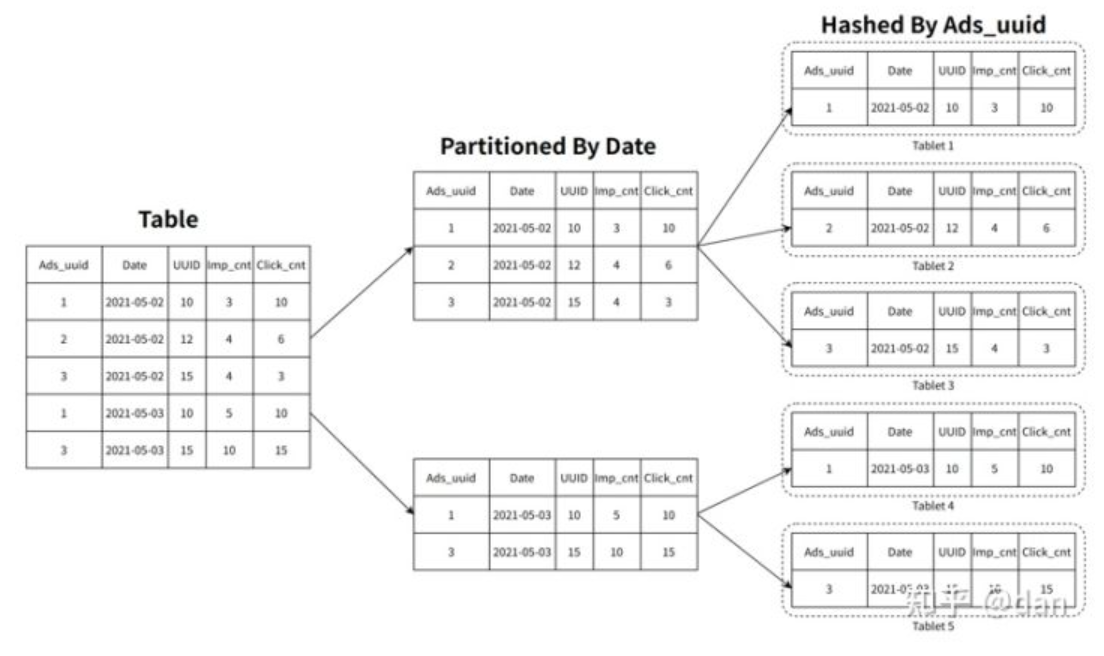
在建表的时候,分区分桶应该尽可能的覆盖到所带的查询语句,这样可以有效的利用分区分桶剪裁的功能,尽可能的减少数据的扫描量。此外,StarRocks也提供了MOLAP库的预聚合能力。对于一些复杂的分析类查询,可以通过创建物化视图进行预先聚合,原有几十亿的基表,可以通过预聚合RollUp操作变成几百或者几千行的表,查询时延迟会有显著下降,并发也会有显著提升。
数据的高频变更
ClickHouse中的数据更新
在OLAP数据库中,可变数据(Mutable data)通常是不受欢迎的。ClickHouse也是如此。早期的版本中并不支持UPDATE和DELETE操作。在1.15版本后,Clickhouse提供了MUTATION操作(通过ALTER TABLE语句)来实现数据的更新、删除,但这是一种“较重”的操作,它与标准SQL语法中的UPDATE、DELETE不同,是异步执行的,对于批量数据不频繁的更新或删除比较有用。除了MUTATION操作,Clickhouse还可以通过CollapsingMergeTree、VersionedCollapsingMergeTree、ReplacingMergeTree结合具体业务数据结构来实现数据的更新、删除,这三种方式都通过INSERT语句插入最新的数据,新数据会“抵消”或“替换”掉老数据,但是“抵消”或“替换”都是发生在数据文件后台Merge时,也就是说,在Merge之前,新数据和老数据会同时存在。
针对与不同的业务场景,ClickHouse提供了不同的业务引擎来进行数据变更。
对于离线业务,可以考虑增量和全量两种方案:
增量同步方案中,使用ReplacingMergeTree引擎,先用Spark将上游数据同步到Hive,再由Spark消费Hive中的增量数据写入到ClickHouse中。由于只同步增量数据,对下游的压力较小。需要确保维度数据基本不变。
全量同步方案中,使用MergeTree引擎,通过Spark将上游数据定时同步到Hive中,truncate ClickHouse中的表,随后使用Spark消费Hive近几天的数据一起写入到ClickHouse中。由于是全量数据导入,对下游压力较大,但无需考虑维度变化的问题。
对于实时业务,可以采用VersionedCollapsingMergeTree和ReplacingMergeTree两种引擎:
使用VersionedCollapsingMergeTree引擎,先通过Spark将上游数据一次性同步到ClickHouse中,在通过Kafka消费增量数据,实时同步到ClickHouse中。但因为引入了MQ,需要保证exectly once语义,实时和离线数据连接点存在无法折叠现象。
使用ReplacingMergeTree引擎替换VersionedCollapsingMergeTree引擎,先通过Spark将上游存量数据一次性同步到ClickHouse中,在通过MQ将实时数据同步到ReplacingMergeTree引擎中,相比VersionedCollapsingMergeTree要更简单,且离线和实时数据连接点不存在异常。但此种方案无法保重没有重复数据。
StarRocks中的数据更新
相较于ClickHouse,StarRocks对于数据更新的操作更加简单。
StarRocks中提供了多种模型适配了更新操作,明细召回操作,聚合操作等业务需求。更新模型可以按照主键进行UPDATE/DELETE操作,通过存储和索引的优化可以在并发更新的同时高效的查询。在某些电商场景中,订单的状态需要频繁的更新,每天更新的订单量可能上亿。通过更新模型,可以很好的适配实时更新的需求。
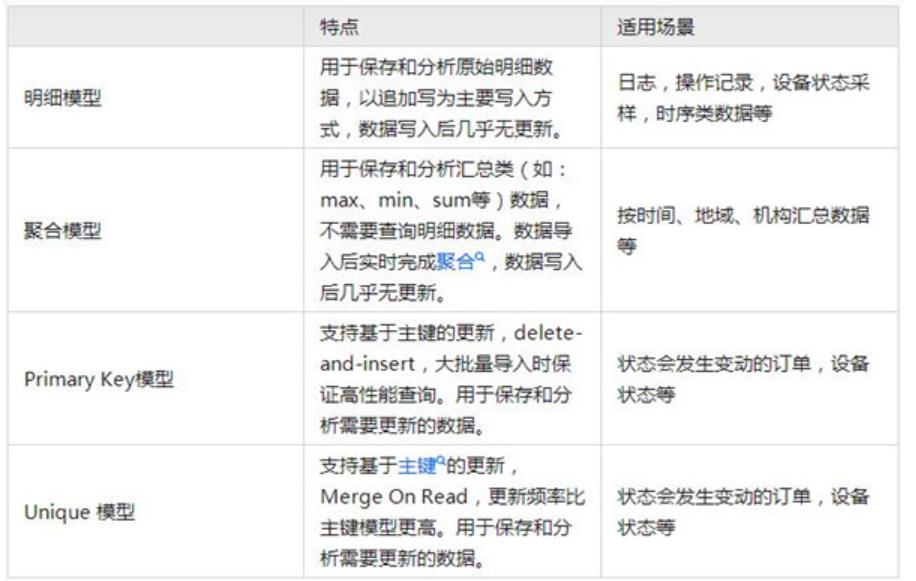
StarRocks 1.19版本之前,可以使用Unique模型进行按主键的更新操作,Unique模型使用的是Merge-on-Read策略,即在数据入库的时候会给每一个批次导入数据分配一个版本号,同一主键的数据可能有多个版本号,在查询的时候StarRocks会先做merge操作,返回一个版本号最新的数据。
自StarRocks 1.19版本之后发布了主键模型,能够通过主键进行更新和删除的操作,更友好的支持实时/频繁更新的需求。相较于Unique模型中Merge-on-Read的模式,主键模型中使用的是Delete-and-Insert的更新策略,性能会有三倍左右的提升。对于前端的TP库通过CDC实时同步到StarRocks的场景,建议使用主键模型。
集群的维护
相比于单实例的数据库,任何一款分布式数据库维护的成本都要成倍的增长。一方面是节点增多,发生故障的几率变高。对于这种情况,我们需要一套良好的自动failover机制。另一方便随着数据量的增长,要能做到在线弹性扩缩容,保证集群的稳定性与可用性。
ClickHouse中的节点扩容与重分布
与一般的分布式数据库或者Hadoop生态不同,HDFS可以根据集群节点的增减自动的通过balance来调节数据均衡。但是ClickHouse集群不能自动感知集群拓扑的变化,所以就不能自动balance数据。当集群数据较大时,新增集群节点可能会给数据负载均衡带来极大的运维成本。
一般来说,新增集群节点我们通常有三种方案:
·如果业务允许,可以给集群中的表设置TTL,长时间保留的数据会逐渐被清理到,新增的数据会自动选择新节点,最后会达到负载均衡。
·在集群中建立临时表,将原表中的数据复制到临时表,再删除原表。当数据量较大时,或者表的数量过多时,维护成本较高。同时无法应对实时数据变更。
·通过配置权重的方式,将新写入的数据引导到新的节点。权重维护成本较高。
无论上述的哪一种方案,从时间成本,硬件资源,实时性等方面考虑,ClickHouse都不是非常适合在线做节点扩缩容及数据充分布。同时,由于ClickHouse中无法做到自动探测节点拓扑变化,我们可能需要再CMDB中写入一套数据重分布的逻辑。所以我们需要尽可能的提前预估好数据量及节点的数量。
StarRocks中的在线弹性扩缩容
与HDFS一样,当StarRocks集群感知到集群拓扑发生变化的时候,可以做到在线的弹性扩缩容。避免了增加节点对业务的侵入。
StarRocks中的数据采用先分区再分桶的机制进行存储。数据分桶后,会根据分桶键做hash运算,结果一致的数据被划分到同一数据分片中,我们称之为tablet。Tablet是StarRocks中数据冗余的最小单位,通常我们会默认数据以三副本的形式存储,节点中通过Quorum协议进行复制。当某个节点发生宕机时,在其他可用的节点上会自动补齐丢失的tablet,做到无感知的failover。
在新增节点时,也会有FE自动的进行调度,将已有节点中的tablet自动的调度到扩容的节点上,做到自动的数据片均衡。为了避免tablet迁移时对业务的性能影响,可以尽量选择在业务低峰期进行节点的扩缩容,或者可以动态调整调度参数,通过参数控制tablet调度的速度,尽可能的减少对业务的影响。
ClickHouse与StarRocks的性能对比
单表SSB性能测试
由于ClickHouse join能力有限,无法完成TPCH的测试,这里使用SSB 100G的单表进行测试。
测试环境
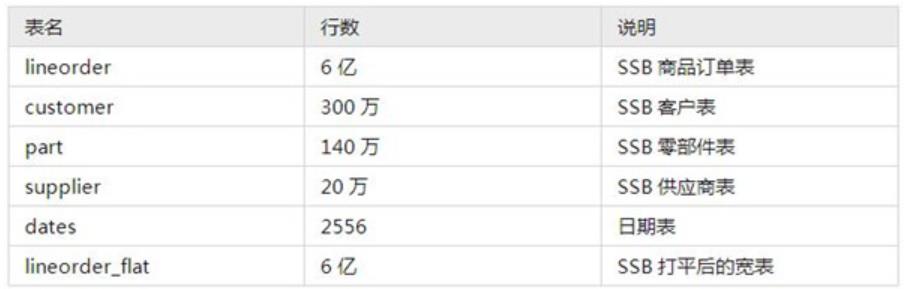
测试数据
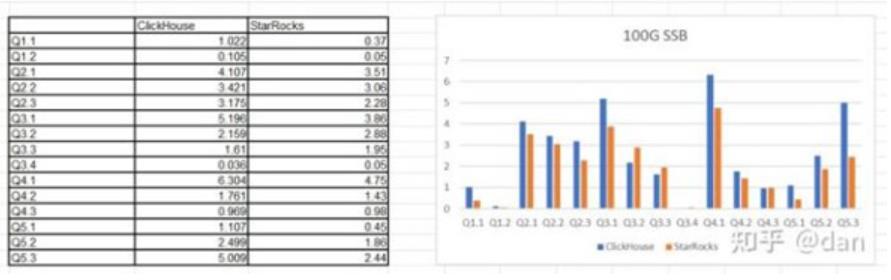
测试结果
从测试结果中可以看出来,14个测试中,有9个SQL,StarRocks在性能上要超过ClickHouse。
多表TPCH性能测试
ClickHouse不擅长多表关联的场景,对于TPCH测试机,很多查询无法跑出,或者OOM,目前只进行了StarRocks的TPCH测试。
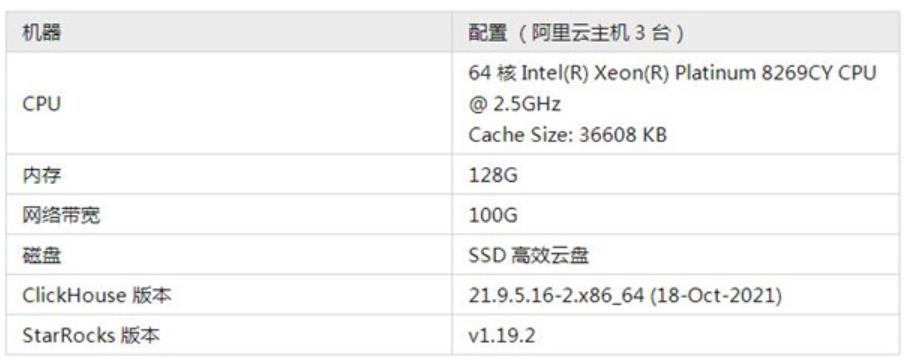
测试环境
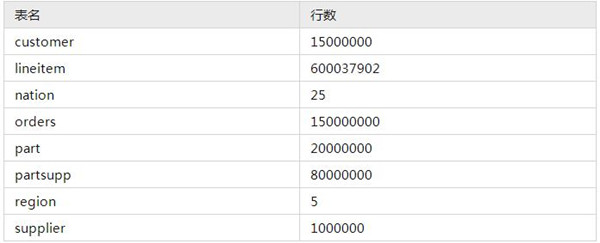
测试数据
选用TPCH 100G测试集。
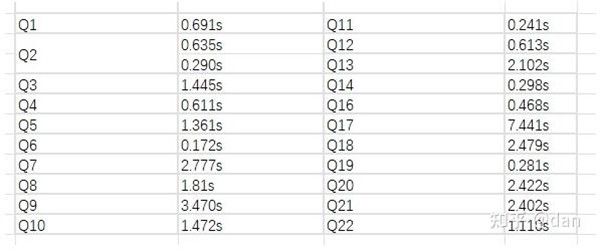
测试结果
导入性能测试
无论是ClickHouse还是StarRocks,我们都可以使用DataX进行全量数据的导入,增量部分通过CDC工具写入到MQ中在经过下游数据库消费即可。
数据集
导入测试选取了ClickHouse Native Format数据集。1个xz格式压缩文件大概85GB左右,解压后原始文件1.4T,31亿条数据,文件格式为CSV
导入方式
ClickHouse中采用的HDFS外表的形式。ClickHouse中分布式表只能选择一个integer列作为Sharding Key,观察数据发现技术都很低,因此使用rand()分布形式。
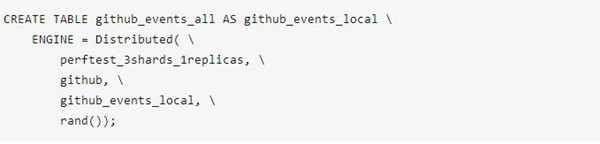
HDFS外表定义如下:
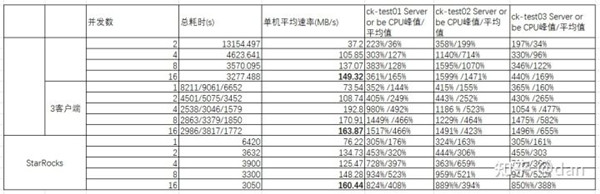
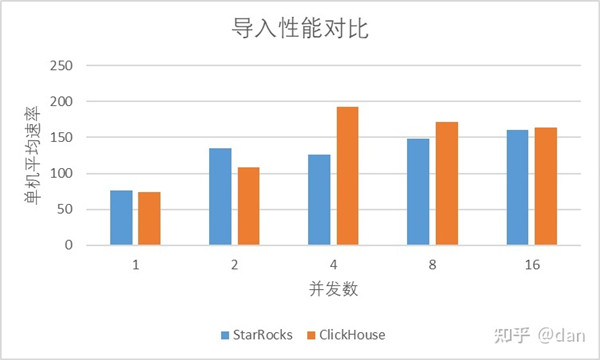
导入结果
可以看出,在使用github数据集进行导入的时候,基本上StarRocks和ClickHouse导入的性能相差不多。
结论
ClickHouse与StarRocks都是很优秀的关系新OLAP数据库。两者有着很多的相似之处,对于分析类查询都提供了极致的性能,都不依赖于Hadoop生态圈。从本次的选型对比中,可以看出在一些场景下,StarRocks相较于ClickHouse有更好的表现。一般来说,ClickHouse适合于维度变化较少的拼宽表的场景,StarRocks不仅在单表的测试中有着更出色的表现,在多表关联的场景具有更大的优势。