













本文转载自微信公众号「有关SQL」,作者Lenis 。转载本文请联系有关SQL公众号。
前几天,我们 SQL 大数据玩家微信群里,有朋友发布了一条数据校验的题目。觉得有趣,也有必要总结下,所以检索了些论文,结合平时工作中的使用,综合起来讲讲,看看自己能不能把这方面讲清楚。
数据校验,常用在“数据搬运”的场景中。
比如,把数据从源头抽取到下游,抽取的过程中,可能还做了一系列的转换,没错这就是常说的ETL. 细心的小伙伴,一定会做好数据校验工作,即在源数据留下“指纹”。数据到了下游,对比下“指纹”,就能知道,有没有漏,有没有丢 ,或者有没有变异。
再比如,两个组同时抽取一个数据源头做分析,在最终结果上,需要对比一致性,这也是数据校验。之前待过一家公司,财务部和营运部拿的都是ERP 数据,一个组用 Python 算,一个组用 SQL, 最后两组算出来的利润和成本完全不一致。月结会上,这两组人就经常因为数据问题而吵架。
再举个例子,作为程序员,经常去 apache 下载一些开源软件,比如 spark。
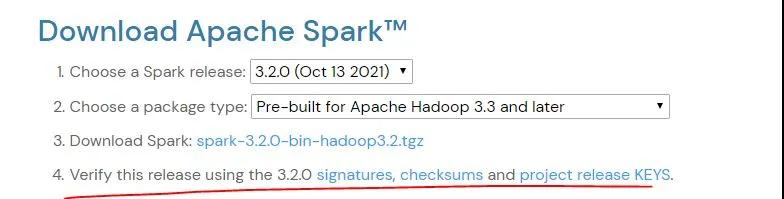
下载页面会有个 verify 的提示,意思也就是做下软件的数据校验,防止网络丢包,或者文件损坏,被调包等等现象发生。
要解决上面这些数据校验需求,我有三个方法:
- 第一,集合对比
- 第二,哈希
- 第三,随帧校验码
集合对比
这是小数据场景最合适的利刃。
举个例子,在数据仓库中,用户表一定不陌生。它的数量级不会很大,通常上万或者十万左右。对它做数据校验时,使用SQL的 Except 就可以了。
假设,有两张用户表,一张来自源数据库,user_source;一张是数据仓库表 user_target. 怎么判断两表的数据差异呢,最简单的方法用 except。
SELECT USER_ID,USER_NAME
FROM user_source
EXCEPT
SELECT USER_ID,USER_NAME
FROM user_target
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
我想,只要SQL 入门的朋友,都能写出来。但用在哪里,就考验平时对场景的理解了。这其中的细节,要躺平的坑,就不多说了,朋友们平时自己多积累了。
哈希
第一种方法,简单粗暴,见效很快。针对小数据量级,非常高效。但要处理起百万级数据,就会差点意思。
接下来要介绍的算法,更高效,它就是哈希。
数据库厂商都实现了自己的哈希(Hash)函数,通过查询文档,这不难掌握。比如:
SQL Server 有 Checksum, Binary_Checksum, HashBytes;
Oracle 有 Ora_Hash.
以下是 SQL Server T-SQL 的 checksum 用例
-- T-SQL Demo
SELECT user_id
, user_full_name
, checksum(user_id,user_full_name) AS row_checksum
FROM dbo.user_source
- 1.
- 2.
- 3.
- 4.
- 5.
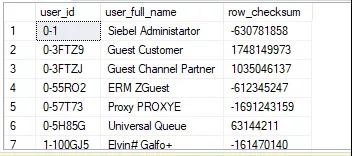
通过 checksum 计算出来的 row_checksum, 它是数值型。范围在正负 21亿左右,也就是 Integer 的范围值。超过这个数,一定会产生重复哈希值,这是它唯一的缺陷。
它的缺陷先放一边,来看它的优点。两个数据集比较时,只要一列,就替代了原先对比两列的操作。
由于数值型的存储空间小,一个 Integer 只需要 4个字节,因此作为索引也非常高效。这个例子中,我们更进一步,在两张表上,加入以 checksum 结果为字段的索引。
ALTER TABLE dbo.user_source ADD row_checksum INT
CREATE INDEX IDX_ROW_CHECKSUM ON dbo.user_source(row_checksum)
UPDATE SRC
SET row_checksum = checksum(user_id,user_full_name)
FROM dbo.user_source SRC
ALTER TABLE dbo.user_target ADD row_checksum INT
CREATE INDEX IDX_ROW_CHECKSUM_TG ON dbo.user_target(row_checksum)
UPDATE TG
SET row_checksum = checksum(user_id,user_full_name)
FROM dbo.user_target TG
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
如此,比较两表的差异,变得更简单,更快捷。
SELECT row_checksum
FROM dbo.user_source
EXCEPT
SELECT row_checksum
FROM dbo.user_target
- 1.
- 2.
- 3.
- 4.
- 5.
随帧校验码
这类方法最原始。在通信领域中,经常会遇到它。在两个终端传输数据时,人们早就意识到通信是不可靠的,因此发明了很多方法,来校验数据的一致性。
CRC 就是其中一种,随着时间的沉淀,它越来越多的被硬件级实现,或者在协议级集成。但是软件上,依然可以用来做检验数据的操作。
CRC: Cyclic Redundancy Check 循环冗余校验
https://en.wikipedia.org/wiki/Cyclic_redundancy_check
CRC 校验的原理,简单画下,是这样的:
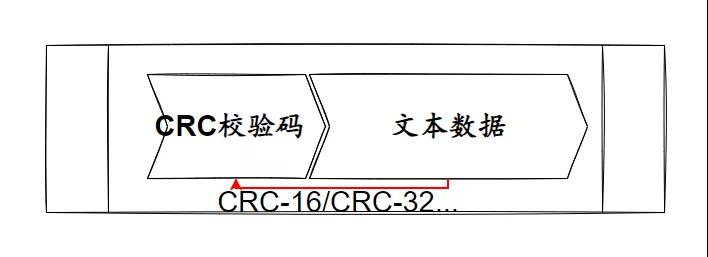
发送端,在要传输的【文本数据】帧上,利用 CRC 函数,算出【CRC校验码】,并把这串数字附在【文本数据】帧上。
数据接收方,基于同样的 CRC 函数,输入【文本数据】,生成新的校验数字,和附带的 CRC 校验码,做对比。若有差异,说明数据有变动。
当然,原理上,CRC 并不简单。需要一系列多项式运算,在这里不展开了。
从 stackoverflow 看到,有人用 SQL 实现了 CRC,感受下:
Declare @input as varchar(1000)
Set @input='This is the CRC test'
Declare @CRCtable as varchar(3080) --Location of Edit
Declare @Index as int
Declare @crc as BIGINT
Declare @length as INT
Declare @i as INT
Declare @tblval as BIGINT
Declare @CTindex as int
Declare @ans as varchar(25)
Set @CRCtable='0000000000, 1996959894, 3993919788, 2567524794, 0124634137, 1886057615, 3915621685, 2657392035, 0249268274, 2044508324, 3772115230, 2547177864, 0162941995, 2125561021, 3887607047, 2428444049, 0498536548, 1789927666, 4089016648, 2227061214, 0450548861, 1843258603, 4107580753, 2211677639, 0325883990, 1684777152, 4251122042, 2321926636, 0335633487, 1661365465, 4195302755, 2366115317, 0997073096, 1281953886, 3579855332, 2724688242, 1006888145, 1258607687, 3524101629, 2768942443, 0901097722, 1119000684, 3686517206, 2898065728, 0853044451, 1172266101, 3705015759, 2882616665, 0651767980, 1373503546, 3369554304, 3218104598, 0565507253, 1454621731, 3485111705, 3099436303, 0671266974, 1594198024, 3322730930, 2970347812, 0795835527, 1483230225, 3244367275, 3060149565, 1994146192, 0031158534, 2563907772, 4023717930, 1907459465, 0112637215, 2680153253, 3904427059, 2013776290, 0251722036, 2517215374, 3775830040, 2137656763, 0141376813, 2439277719, 3865271297, 1802195444, 0476864866, 2238001368, 4066508878, 1812370925, 0453092731, 2181625025, 4111451223, 1706088902, 0314042704, 2344532202, 4240017532, 1658658271, 0366619977, 2362670323, 4224994405, 1303535960, 0984961486, 2747007092, 3569037538, 1256170817, 1037604311, 2765210733, 3554079995, 1131014506, 0879679996, 2909243462, 3663771856, 1141124467, 0855842277, 2852801631, 3708648649, 1342533948, 0654459306, 3188396048, 3373015174, 1466479909, 0544179635, 3110523913, 3462522015, 1591671054, 0702138776, 2966460450, 3352799412, 1504918807, 0783551873, 3082640443, 3233442989, 3988292384, 2596254646, 0062317068, 1957810842, 3939845945, 2647816111, 0081470997, 1943803523, 3814918930, 2489596804, 0225274430, 2053790376, 3826175755, 2466906013, 0167816743, 2097651377, 4027552580, 2265490386, 0503444072, 1762050814, 4150417245, 2154129355, 0426522225, 1852507879, 4275313526, 2312317920, 0282753626, 1742555852, 4189708143, 2394877945, 0397917763, 1622183637, 3604390888, 2714866558, 0953729732, 1340076626, 3518719985, 2797360999, 1068828381, 1219638859, 3624741850, 2936675148, 0906185462, 1090812512, 3747672003, 2825379669, 0829329135, 1181335161, 3412177804, 3160834842, 0628085408, 1382605366, 3423369109, 3138078467, 0570562233, 1426400815, 3317316542, 2998733608, 0733239954, 1555261956, 3268935591, 3050360625, 0752459403, 1541320221, 2607071920, 3965973030, 1969922972, 0040735498, 2617837225, 3943577151, 1913087877, 0083908371, 2512341634, 3803740692, 2075208622, 0213261112, 2463272603, 3855990285, 2094854071, 0198958881, 2262029012, 4057260610, 1759359992, 0534414190, 2176718541, 4139329115, 1873836001, 0414664567, 2282248934, 4279200368, 1711684554, 0285281116, 2405801727, 4167216745, 1634467795, 0376229701, 2685067896, 3608007406, 1308918612, 0956543938, 2808555105, 3495958263, 1231636301, 1047427035, 2932959818, 3654703836, 1088359270, 0936918000, 2847714899, 3736837829, 1202900863, 0817233897, 3183342108, 3401237130, 1404277552, 0615818150, 3134207493, 3453421203, 1423857449, 0601450431, 3009837614, 3294710456, 1567103746, 0711928724, 3020668471, 3272380065, 1510334235, 0755167117, '
Set @crc = 0xFFFFFFFF
Set @length = LEN(@input)
Set @i = 1
While @i <= @length
Begin
Set @index = ((@crc & 0xff) ^ ASCII(SUBSTRING(@input, @i, 1)))
Set @CTindex = (@index * 12) + 1
Set @ans=substring(@CRCtable,@CTindex,10 )
Set @tblval = convert(bigint,@ans)
Set @crc = (@crc / 256) ^ @tblval
Set @i = @i + 1
End
Set @crc = ~@crc
SELECT @crc as CRC32, CONVERT(VARBINARY(4), @crc) as CRC32Hex
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
摘自:https://stackoverflow.com/questions/331157/does-sql-server-checksum-calculate-a-crc-if-not-how-can-i-get-ms-sql-to-calcula
这么做,当然是可以的,但代价偏高。
前面讲 checksum 时,提到它的缺陷。在超大的数据量下,它计算出来的哈希值,会有重合。这,是算法界常遇到的问题。即,不同的值,可能有相同的哈希值。CRC 也逃不掉。
因此,下面介绍防撞率更高的一种方法,MD5。
MD5: Message-Digest Algorithm
https://baike.baidu.com/item/MD5/212708?fr=aladdin
下面是一个例子,分别用 CRC32/MD5 对天池竞赛公开的数据集,做了比较。两者都可以完美地识别出相同的记录数,采用同样的参数格式,对需要进行对比的列,计算出校验码。
use Demo
select
user_id,
item_id,
behavior_type,
item_category,
md5(concat(user_id, item_id, behavior_type, item_category)) as row_md5,
crc32(concat(user_id, item_id, behavior_type, item_category)) as row_crc32
from
tianchi_mobile__user tmu
order by
user_id asc ,
item_id asc
limit 10 ;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
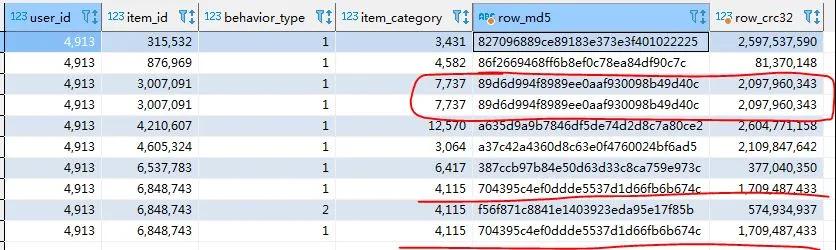
CRC32 计算出的是整数型校验码,而MD5计算出来的是十六进制的字符串。由此可见,MD5 能容错的数据范围更大,防撞率更高。
无论是通过 CRC 还是 MD5算法,总有概率上产出两个相同的值。因此我们并不能仅仅凭借最后两个输出值相等,就判定两个输入值就一定相等。但反推是成立的,只要两个输出值不等,它们的输入值就一定不等。
SQL Server 也有这样的解决方案,比如 hashbytes. 由于 checksum返回的是 int 数据类型,因此在处理小数据量时,速度会有优势。但防撞率不高。
如果数据量极大,超过22亿,那么很难逃过重合的命运。此时SQL Server 提供了 hashbytes 来生成重合率更小的 hash 值, 除了 MD5外,还能生成 SHA128, SHA512 这样支持更宽范围数据的标准。
花絮
我很想讲讲,最近写文章的心得。就像这篇文章一样,写作尤其写一个不熟悉的领域,其实要花很大的功夫。
从开始布局思考,搜集论文资料,看懂 CRC/MD5/SHA 的原理,到最终构思文章结构,用自认为还算通俗的文字写出来。期间对心理的考验特别大。这就像我的对面是个大怪兽,除了几十倍大于我,我还找不出任何攻击点。
我唯一能依靠的,就是死抠细节,写下来一个个遇到的小问题,翻阅各种手头资料,比如微信读书,极客时间,还有知网论文等,去求证,去看别人写的例子。以求能完美回答我自己提出的问题。
最后还要修改文章结构,力求文字表述清爽,言简意赅,流畅阅读。
在最终出篇前,加梗,加料,反复修改。多少次,面对精心写完的段落,也是哽咽地删掉。不得不说,写作就像磨咖啡豆一样,使劲碾压自己,才能绽放香气。最终成杯的那一刻,苦尽甘来!一切都是值得的















