前言
spring bean,其实经常用spring的开发人员来说,这个单词并不陌生,应该是相当熟悉,我们每天都会接触到各种的bean对象,之前也介绍了,spring提供了IOC来完成bean的创建,让我们大家不用new就可以直接拿到对象,使用对象了
我们来看一下spring bean的定义,spring官方文档对于bean的解释是:
- In Spring, the objects that form the backbone of your application
- and that are managed by the Spring IoC container are called beans.
- A bean is an object that is instantiated, assembled, and otherwise
- managed by a Spring IoC container.
翻译过来就是:
在 Spring 中,构成应用程序主干并由Spring IoC容器管理的对象称为bean。bean是一个由Spring IoC容器实例化、组装和管理的对象。
概念很简单明了,我们提取处关键的信息:
- bean是对象,一个或者多个不限定
- bean由Spring中一个叫IoC的东西管理
- 我们的应用程序由一个个bean构成
下面我们会从springbean的作用域、定义继承、前置和后置处理器、生命周期(加载过程)等几个方面来分析springbean,让大家对其更加熟悉,面试直接起飞
作用域
springbean的作用域分为下面这几种
1、singleton:单例作用域
2、prototype:每次从容器中调用Bean时,都会返回一个新的实例,即相当于执行一次new的实例化操作
3、request:每次HTTP请求调用Bean时,spring容器都会创建一个新的Bean
4、session:同一个Http Session共享一个Bean,不同的session使用不同的bean
5、globalSession:全局session共享一个Bean,仅用于WebApplication环境
singleton:单例作用域
singleton在 Spring 容器中仅存在一个 Bean 实例, Bean 以单例的形式存在。
Spring 以容器的方式,使得我们仅需配置,即可得到天然的单例模式。
一般情况下,无状态或者状态不可变的类适合使用单例模式来实现, 不过 Spring 利用 AOP 和 LocalThread 的能力,对非线程安全的变量(状态)进行了特殊处理,使的一些非线程安全的类(持有 Connection 的 DAO 类)变成了线程安全的类 。
因为 Spring 的超强能力,所以在实际应用中,大部分 Bean 都能以单例方式运行 ,这也是 bean 的默认作用域指定为 singleton 的原因 。
singleton 的 Bean 在同一个 Spring IoC 容器中只会一个实例。
prototype:每次从容器中调用Bean时,都会返回一个新的实例,即相当于执行一次new的实例化操作
prototype 作用域的 bean 会导致在每次对该 bean 请求(将其注入到另一个 bean 中,或者以程序的方式调用容器的 getBean() 方法)时都会创建一个新的 bean 实例。
Prototype 是原型类型,它在我们创建容器的时候并没有实例化,而是当我们获取bean的时候才会去创建一个对象,而且我们每次获取到的对象都不是同一个对象。
根据经验,对有状态的 bean 应该使用 prototype 作用域,而对无状态的bean则应该使用 singleton 作用域。
此外, Spring 容器将 prototype 的 bean 交给调用者后,就不再负责管理它的生命周期咯。
request:每次HTTP请求调用Bean时,spring容器都会创建一个新的Bean
每次 http 请求都会创建一个新的 Bean , 仅用于 WebApplicationContext 环境。request 作用域的 Bean 对应一个 HTTP 请求和生命周期 。
每次 HTTP 请求调用 Bean 时, Spring 容器就会创建一个新的 Bean ;请求处理完毕,就会销毁这个 Bean。
session:同一个Http Session共享一个Bean,不同的session使用不同的bean
同一个 http Session 共享一个 Bean ,不同的 http Session 使用不同的 Bean,仅用于 WebApplicationContext 环境。
Bean 的作用于横跨整个 HTTP Session。Session 中的所有 HTTP 请求会共享同一个 Bean. 只有当 HTTP Session 结束后,Bean实例才会被销毁 。
globalSession:全局session共享一个Bean,仅用于WebApplication环境
globalSession同一个全局 Session 共享一个 bean,用于 Porlet,仅用于 WebApplication 环境。
globalSession 的作用域类似于 session 作用域, 不过仅在 Portlet 的 Web 应用中使用 。Portlet 定义了全局 Session,它被组成 Portlet Web 应用的所有子 Portlet 共享。如果不在 Portlet 的 Web 应用下,globalSession 等价于 session
定义继承和前置后置处理器
定义继承:bean定义可以包含很多的配置信息,包含构造函数的参数、属性值,容器的具体信息例如初始化方法,静态工厂方法名等
子Bean可以继承父Bean的配置数据,当然也可以去重写其中的值,或者添加值,Springbean的定义继承和Java的类继承无关,但是呢,道理是一样的,我们可以定义一个父Bean来作为模板,然后多个子Bean就可以从父Bean中继承所需的配置
接下来我们看前置处理器和后置处理器,顾名思义,前置,指的是实例化对象之前的处理。后置,指的是实例化对象之后的处理。
前置处理器
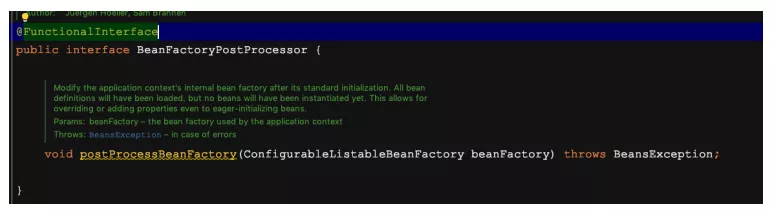
在Spring中的前置处理器的接口是BeanFactoryPostProcess,这个机制允许我们在实例化相应的对象之前,对注册到容器中的BeanDefinition存储信息进行相应的修改
拿到了Provider的信息之后就可以通过监听触发 Protocol# refer 了,具体调用哪个 protocol 还是得看 URL的协议的,我们看下这个内部DubboProtocol的refer
可以根据这个机制对Bean增加其它信息,修改Bean定义的某些属性值。想自定义前置处理器需要实现BeanFactoryPostProcess接口。当一个容器存在多种前置处理的时候,可以让前置处理器的实现类同时继承Ordered接口,顾名思义,就是用来排序的,可以实现优先级。
Spring容器提供了数种现成的前置处理器,常见的如:
PropertyPlaceholderConfigurer:允许在xml文件中使用占位符。将占位符代表的资源单独配置到简单的Properties文件中加载
PropertyOverrideConfigurer:不同于PropertyPlaceholderConfigurer的是,该类用于处理容器中的默认值覆为新值的场景
CustomEditorConfigurer:此前的两个前置处理器处理的均是BeanDefinition.通过把BeanDefinition的数据修改达到目的。CustomEditorConfigurer没有对BeanDefinition做任何变动。负责的是将后期会用到的信息注册到容器之中。例如将类型转换器注册到BeanDefinition中。供BeanDefinition将获取到的String类型参数转换为需要的类型。
后置处理器
在Spring中的后置处理器是BeanPostProcessor接口
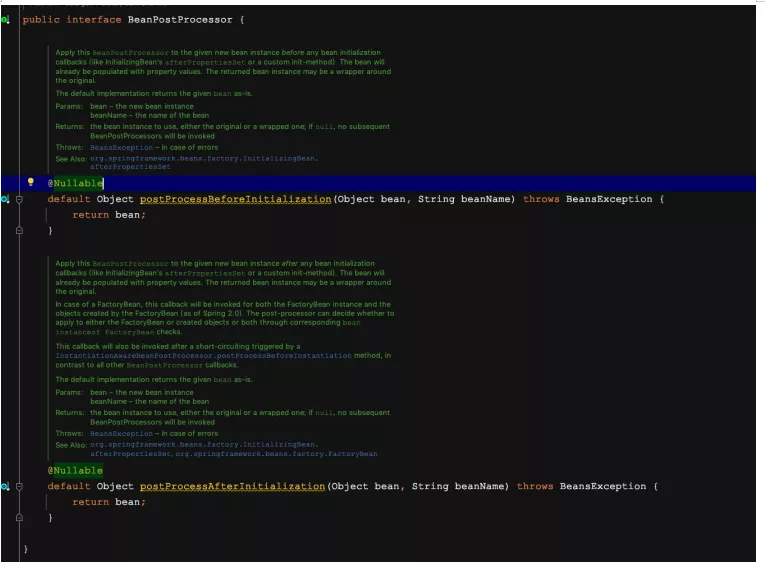
在Spring中的后置处理器是BeanPostProcessor接口
可以看到有两个方法BeanBeforePostProcessor和BeanAfterPostProcessor,我们根据方法名也能猜出个大概,大概就是一个是前面执行的,一个是后面执行的咯
可是问题来了,我们上面不是看了一个前置处理器了吗,为什么这里又来了一个before,那这个before和after是针对于什么来说的呢
这里的before和after是相对于对象的初始化来说的,上面的前置处理器和后置处理器是针对于对象的实例化,两者的范围是不一样的
实例化就是我们常说的,创建一个Bean的过程,即调用Bean的构造函数;而初始化的过程则是一个赋值的过程,即调用Bean的setter,设置Bean的属性的过程
生命周期(加载过程)
springbean的生命周期,也就是加载过程,这应该也是和spring的循环依赖一样,也是属于面试常问的一个点了,不知道大家被问到过没,反正我是被问到过,spring的话题本来就是面试非常爱问的一点,IOC和AOP这是经常问的,也是属于最基础的
稍微涉及到源码的部分,都会问到循环依赖的三级缓存怎么工作的,为什么不用两级缓存,bean的生命周期等问题
废话少说了,多学学数据结构和算法,多学学spring,通吃
我们来看下springbean的生命周期流程,可以分为几个阶段
1、实例化过程
2、后置处理和放入缓存(这一步是为了循环依赖)
3、初始化过程(属性赋值)
4、销毁过程
主要的逻辑是在doCreateBean()方法,其实源码的注释也很清晰,大家可以多去读读源码,真的很不错,大家没事的时候其实不用刷太多无用的博客,当然我这是有用的,关注还是很重要的!毕竟关注了不迷路,当你下次找工作,还在为不知道该复习什么的时候,或者不知道该复习哪些知识点的时候,我这个号啊,是真香
重要的是重要的是重要的是!我还会把所有相关的技术文章都给汇总起来,放到了GitHub上,大家可以随时阅读
公众号一关注,时常读几篇技术文章,还可以阅读以下灵魂文章;GitHub地址一收藏,下次面试再也不愁,offer轻松拿到手,直接起飞
我把这个源码给贴出来,其实有点多,大家不用去细读,读个大概的流程就可以了
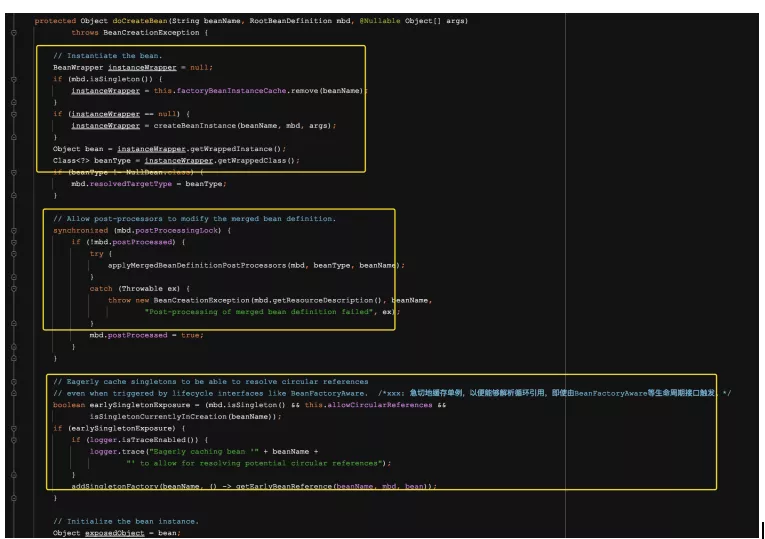
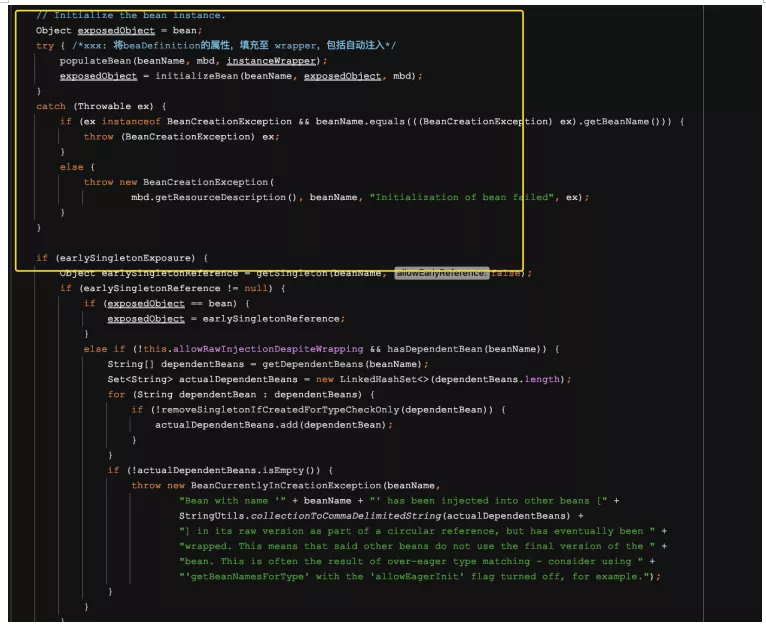
这一个方法真的很长,也是主要流程,简单看一下
首先就是实例化Bean,然后呢,就是和我们上面所说的后置处理器有关了,允许后置处理器去修改相应的属性,接着是把这个实例Bean直接放入到缓存中,而且是很急切的放入到缓存中去了!
相信大家看够我上一篇的spring循环依赖的同学应该都很熟悉,知道为啥这里要急切的放入到缓存中了,没错,就是为了解决spring中的循环依赖的问题的
接着就是属性的设置和初始化过程了,这一阶段主要是进行属性的赋值咯,这里有的小伙伴有一个误解,认为这一块会为属性分配内存空间,不是的。分配内存的操作是在实例化Bean的过程中,这个过程JVM就已经完成了内存空间的分配了
最后一步就是销毁咯,这一步实在也没啥好说的了
好了,这应该就是要说的所有了,关于bean想了解更详细的可以去读源码,真的很建议大家读读关键地方的源码,很多小伙伴对于读源码也是很头疼的,教大家一个好法子,大家在读源码的时候,可以先找准其中的关键地方,怎么找?谷歌,百度!
找到关键的地方,然后一步步的去研究源码的设计流程和某些地方的细节,千万不要把每一个细节都要认真读懂,真的没啥必要,浪费时间,抓住重点,去读那些关键的地方
下次准备跳槽的时候再也不用担心该复习什么了啊!