一 导读
一段描述性的文字、配上风格参考和局部的画面信息,AI有可能快速、准确的“脑补”出完整的图像吗?在深度学习顶会NeurIPS 2021上,阿里巴巴达摩院智能计算实验室提出了一种全新的多模态预训练架构,M6-UFC 来统一任意数量的多模态控制用于灵活的条件图像生成。实验表明,M6-UFC 可应用于服装设计、促进智能制造的发展和个性化服装定制。
在犀牛智能制造的业务中,M6为淘宝运动时尚品牌设计“元生款”服装,帮助降低人力投入、时间成本和整个设计流程的碳排放。根据估算,通过M6先制作初始样本,并结合犀牛环保面料如天然纤维材质的研发应用,就能在设计-生产这件印花T恤的过程中减少30%以上的碳排放。利用M6模型和犀牛智造,现在卖出一件服装大约能减排0.35千克二氧化碳;卖出50件就相当于种下一棵树。
二 文章框架
1 AI的想象力?
告诉你一些信息,你能想象整件衣服是什么样子吗?
比如:要和下面↓↓领子一模一样:

这个图案设计很好看,想要一件类似的:

再比如, 一件 “真丝纱网拼接A字连衣裙”。
下面揭晓答案:
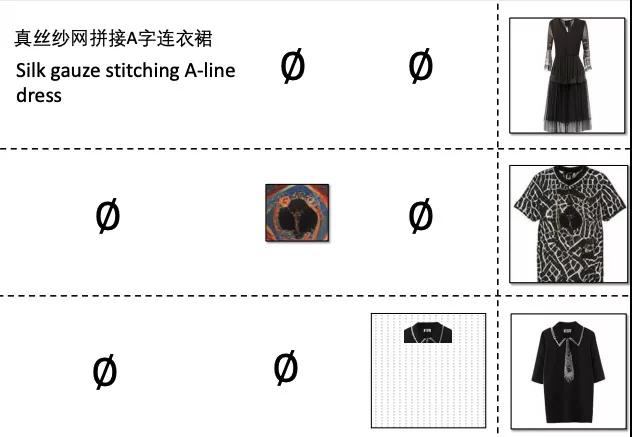
其实,这些设计都是由一个神经网络完成。各种衣服想怎么组合,就怎么组合,例如下图的西装+印花t恤,短裙+衬衣 等等;花纹,颜色,材质都可以都可以很好的融合。
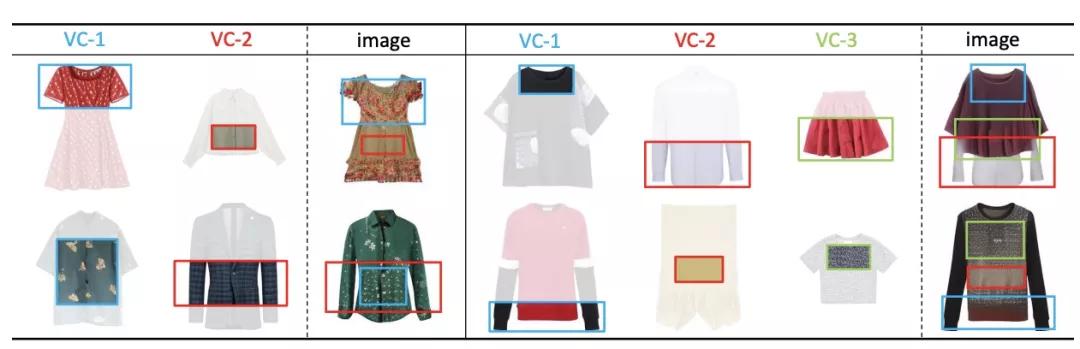
不用担心撞衫,同样的控制信号,想生成多少款就生成多少款:

2 一个多模态控制下的图像生成模型
以上的这些都来自一个叫M6-UFC的模型,可以使用任意数量的文本、图像作为控制信号,生成高质量的图像,还能对细节进行保留和编辑。
研究出自阿里巴巴达摩院和清华大学,相关论文已被NeurIPS 2021接收。

在此之前,大多数的图像生成编辑方法,通常只使用一种控制信号。例如,在图像inpainting和outpainting任务,会给定图像的一部分,在风格迁移任务中,会给一张风格图像,在文本生成图像中,会给一段描述图片的话。
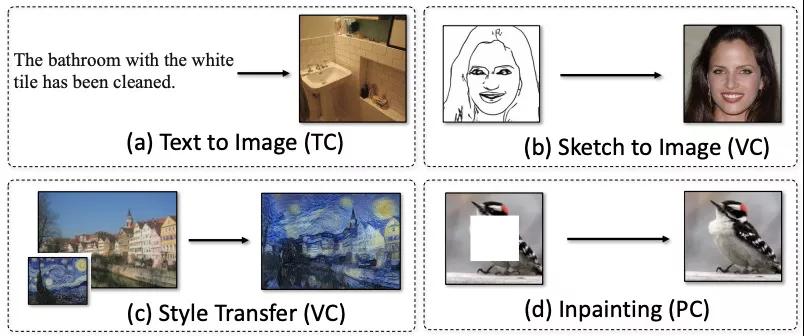
M6-UFC作为一种全新的方法,第一次将多种控制信号统一起来,并可以对任意数量的控制信号进行组合来生成图像。
例如在下面这张图中,就同时输入了文本“翻领垫肩橙色带口袋西装大衣”,图像“翻领”和要保留的部分“米色宽松下摆”:
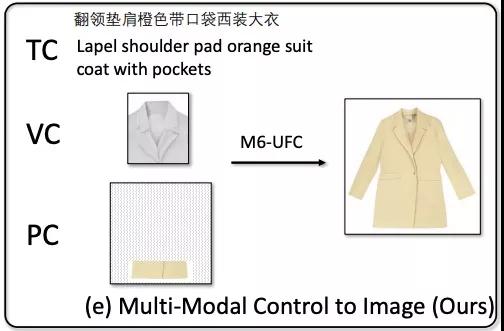
而M6-UFC会根据控制信号,生成满足所有要求的图像。
M6-UFC的核心思想在于非自回归的训练框架,兼容了之前架构(例如 DALL·E,VQGAN)不兼容的图像控制和保留控制信号。
非自回归生成的好处不止于此,还大大提高了生成速度,并增强了图像的整体一致性。
模型的输入是一个24层的M6(一种Transformer模型),它的输入分为四部分:第一部分是两个特殊的评测token [REL]和[FDL],用于评测控制信号与生成图像的相关性,以及生成图像的真实性,用于后续的PNAG算法;第二部分是文本控制输入,即任意长度的单词序列;第三部分是视觉控制输入,这里我们将视觉控制的图像通过第一阶段的codebook转化成了一个code序列,而我们进一步支持多个视觉控制,用[SEP]将多个控制的code序列划分开;最后一部分是待生成的图像,它同样被转化为一个code序列,而在训练或者NAR生成中,这个code序列被部分或者全部mask。
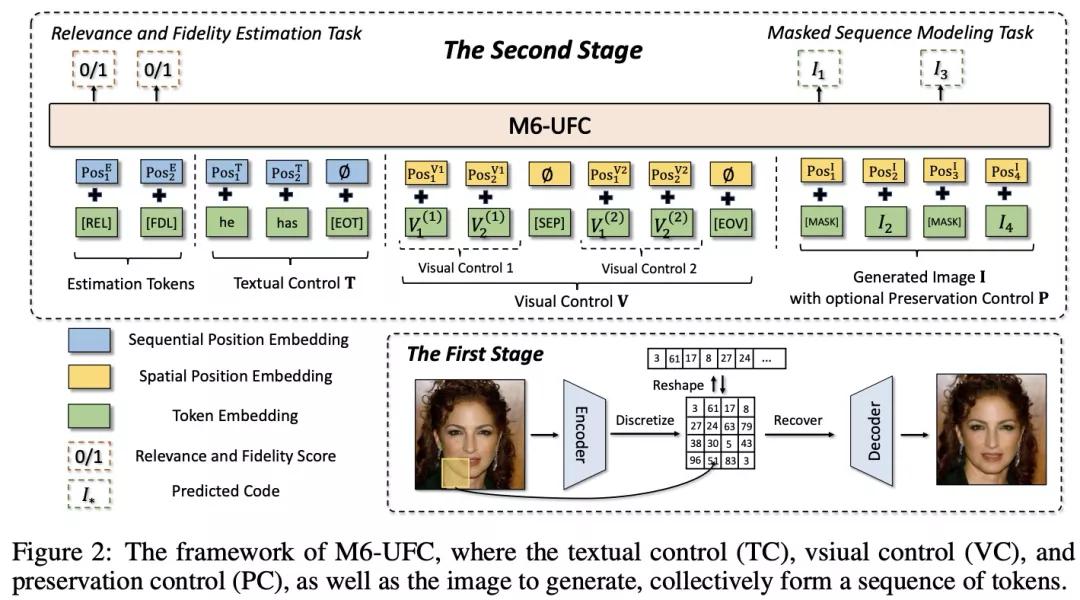
3 训练过程
研究人员设计了三个任务来训练模型,主任务为Masked Sequence Modeling(MSM),同时有两个评测任务 Relevance Estimation和Fidelity Estimation。
任务一:Masked Sequence Modeling
这个任务相似于BERT中的masked language modeling。作为图像领域最早运用离散code来做MLM训练的模型之一,M6-UFC和同期的工作BEIT相比,其mask策略更加完善因此也能支持更复杂的控制类型。M6-UFC中有如下四种策略:1. 随机决定mask的code数量,然后随机采样需要mask的位置;2. 全部mask;3. 随机选择图像中任意大小的box区域,然后对该区域进行mask;4. 随机选择图像中任意大小的box区域,然后对该区域外的部分进行mask。
在此之上,M6-UFC还将mask策略进一步拓展到了多种控制模态, 对于文本控制(TC)和视觉控制(VC)进行四种组合(保留控制被自然地包含在mask的训练过程中):两者兼有,只有一种,或者两者皆无。因为数据集中没有提供视觉控制-目标图像对,而只有文本-图像对,研究者们截取目标图像中的一个或者多个区域来作为训练过程中的数据额控制。
任务二:Relevance Estimation
将token [REL]的特征输入到一个线性分类器进行二元分类,判断控制信号和当前生成图像的相关性。这里的负样本通过将两个训练样例的控制信号进行互换。
任务三:Fidelity Estimation
将token [FDL]的特征输入到一个线性分类器进行二元分类,判断生成图像是不是真实的。由于数据集中不存在”不真实“的负样本,我们在训练几个epoch后用M6-UFC进行text-to-image生成,把合成的图像作为负样本。
在模型推导阶段,研究人员提出了一种渐进式的非自回归生成方法PNAG。在每一次迭代中,在mask阶段都产生5个不同的输入样例,然后在predict阶段产生5个生成图像,以及这5张图的relevance和fidelity分数。选择relevance和fidelity分数最高的(以1:1的比例加权)图像作为下一步的输入图像。PNAG算法可以给用两个评测器指导非自回归迭代的生成方向,而不是”无意识“地进行迭代。
随着迭代的进行,图像与文本的相关性和图像质量会越来越高。红框的是具有最高分的图像,也就是最终结果,这和我们人眼的认知基本相符,如下图所示:

4 测试结果
真实效果如何?
研究人员在标准数据集上与传统的GAN-based方法进行比较,发现在FID和LPIPS上都取得了当前最好的效果。

之后,研究人员将M6-UFC和VQGAN进行详细的比较,在自动评测上基本取得更好的效果,人工评测上更是大幅领先。
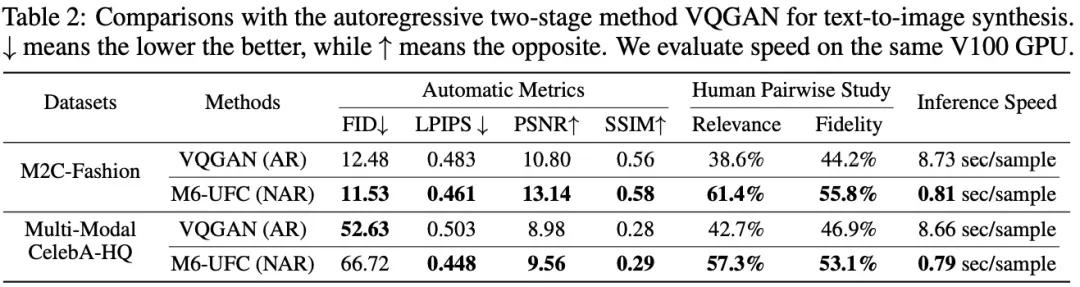
与此同时,M6-UFC所花的时间不到VQGAN的10%!
再来看看生成的图像,一个反事实例子中(男式牛仔风格的蕾丝裙),VQGAN生成了一条正常的牛仔裤,而UFC-BERT生成了一件现实不存在的服饰,一条具有蕾丝下摆,男士裤裆设计的牛仔裙。

使用文本控制(TC)和保留控制(PC):
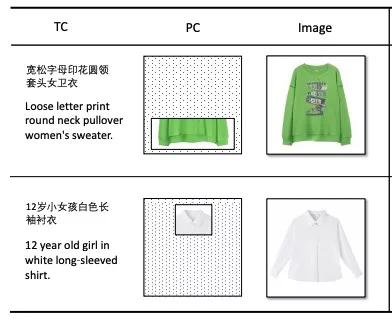
使用文本控制(TC)和视觉控制(VC)

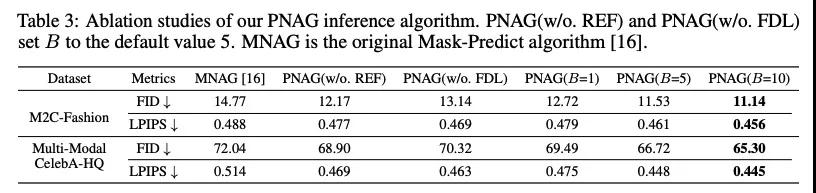
文章也讨论了PNAG算法的有效性,产生三个消解模型,其中PNAG(w/o. REL)去掉了相关性评测器,PNAG(w/o. FDL)去掉了真实性评测器,而MNAG是原始的Mask-Predict算法。同时,在PNAG中,并行迭代的数量B也是个重要的超参数,默认为5,研究者们将其也设置为1和10进行实验。消解结果如下,可以发现两个评测器都对图像生成的质量有很大帮助,而B设置的越大,PNAG迭代时搜索的空间越来,图像质量也就越好。
5 前景与展望
本文介绍了一种新架构 M6-UFC,以统一任意数量的多模态控制,以实现灵活的条件图像生成。UFC的编辑能力,大大提升了图像在少样本情况下的生成拓展性和创造力,通过自动图像生成来打造全新款式。实验表明,M6-UFC可以应用于服装设计。因此,这项研究可以推动智能制造的发展,促进个性化服装定制,帮助服装设计师提高效率。
AI不仅仅有理解和匹配能力,更加有创新创造的能力。而这样的能力,也慢慢趋近于人类的认知能力,我们从以往的事物中学习和理解,并在新的场景下自由组合和创造。我们相信这样的能力不仅会给消费者带去耳目一新的体验,也能通过平台给商家带去全新的赋能体验。
关于M6
M6是阿里巴巴智能计算实验室推出的超大规模预训练模型。M6团队相继提出百亿、千亿、万亿和十万亿参数规模的超大规模预训练模型M6。除了首先通过扩展稠密模型观察到和Neural scaling law一致的现象,后续M6团队开始研究超大规模MoE模型,是在全球范围继谷歌后首个在此领域深入探索的团队。随后打造了第一个基于稀疏专家模型的多模态预训练模型-千亿参数M6,用非常高效的方式完成如此大规模的多模态预训练模型的训练。完成第一步之后,M6团队在此前研究的基础上,开始思考如何让MoE模型变得更加强大的同时,也能更加低碳、环保。最终,在今年5月,在相比千亿M6显著提效的同时,万亿参数M6-T仅用480张GPU耗时3天即训练完成。10月,M6再次突破业界极限,通过更细粒度的CPU offload、共享-解除算法等创新技术,让收敛效率进一步提升7倍,这使得模型规模扩大10倍的情况下,能耗未显著增加。
除了深入探索大模型研发的技术,M6团队同时也高度关注大模型的落地应用和服务。针对不同的业务场景,团队将M6模型和各类单模态和跨模态的下游任务,包括理解类和生成类任务深度结合,推出了服务化组件,日均实现上亿调用,得到了业务方的认可和积极的意见反馈。同时团队将M6模型的生成和理解能力,落地到服饰制造、智能文案生产、金融领域对话与问答等应用场景中,将技术能力转化为工业落地价值。
数据库常见问题排查
开发者经常会遇到些数据库的问题,觉得无从下手,这严重影响了开发效率,也影响了开发者对数据库的热情。如何避免这样的窘境,如何降低数据库使用门槛以及运维的成本,如何在较短的时间内用云数据库的技术和理念来武装自己,提升自己。本课程通过实际的场景以及最佳实践出发,带给大家一些数据库问题的通用解决思路和方法,大家会发现数据库不再是一个黑盒,相反它看得见,摸得着,也能够轻松玩得转。点击阅读原文查看详情。