前言:
之前分享过一篇Linux开发coredump文件分析实战分享 ,今天再来分享一篇实战文章。
在我们嵌入式linux开发过程中,开发过程中我们经常会使用多进程、多线程开发。那么多线程使用过程中,我们大概率会遇到某线程长时间占用cpu,导致设备执行异常。
通常只有四五个线程,我们可以通过一个个线程调试捕捉到异常线程,如果你开发的设备上面运行了大概三四十个线程,我们一下子不好看到对应哪个线程出问题,也不好使用列举法进行搜索,这个时候我们需要配合一些工具进行监控以及检查我们执行的进程下面的线程。下面我就给大家介绍一下我自己工作中实际遇到的例子。
情节介绍:
在工作中,我遇到这样一个问题,我的设备跑机的时候发现,机器运行某些状态时候有些怪异,对于某些机制的处理响应不够及时,最后top检查,发现是我运行的某个进程中的某几个线程运行cpu占有率很高,导致其他的一些线程无法及时运行。
找到问题了,接下来我们就开始找对应的线程然后进行修改,前文提到,进程里面有一两个线程还好说,我们可以通过一些比较基础的方法,一个个线程进行log或者其他手段的信息输出,但是如果我们遇到单个进程里面有很多线程的时候,我们如何检查呢?
初步列一个使用的工具大纲:ps 组合命令、top组合命令、pstack、strace、ltrace、gdb attach
以上就是我使用到的一些命令和操作,接下来一一给大家进行分析和介绍:
首先给大家介绍每个工具和命令详细介绍,再用自己的一个小例子把这些工具进行组合使用说明。
工具和组合命令详细介绍
首先给详细的介绍一下这些工具说明书:
ps 的选项参数介绍:
ps命令大家在linux使用应该是很熟悉的,ps是Process Status的缩写,用来列出系统中当前运行的进程。使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等。ps命令所列出的进行是当前进程的快照,也就是并不是动态的,而是执行该命令时那一时刻进行的状态。
- ps 的参数非常多, 在此仅列出几个常用的参数并大略介绍含义
- -A 列出所有的进程
- -w 显示加宽可以显示较多的资讯
- -au 显示较详细的资讯
- -aux 显示所有包含其他使用者的行程
我一般都是使用 ps -aux进行查看后台运行的进程pid
下面再进行补充一下今天要使用到的ps组合命令
查看进程对应的线程
- ps -T -p 472 (472 此处为真实进程的pid大家自行替换)
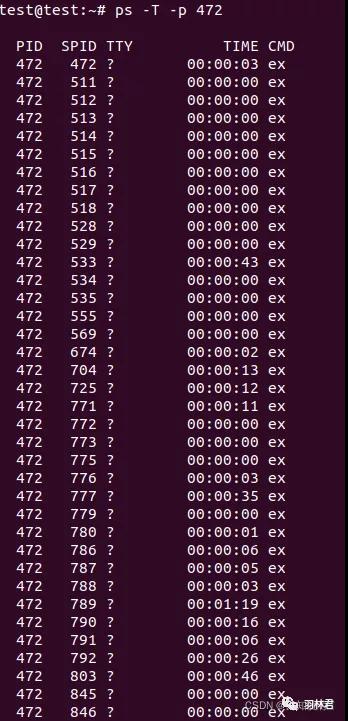
第一行是对应的进程ID,第二行是对应的线程ID
查看进程对应线程的执行时间
- ps -eLo pid,lwp,pcpu |grep 1780(1780 此处为真实进程的pid大家自行替换)
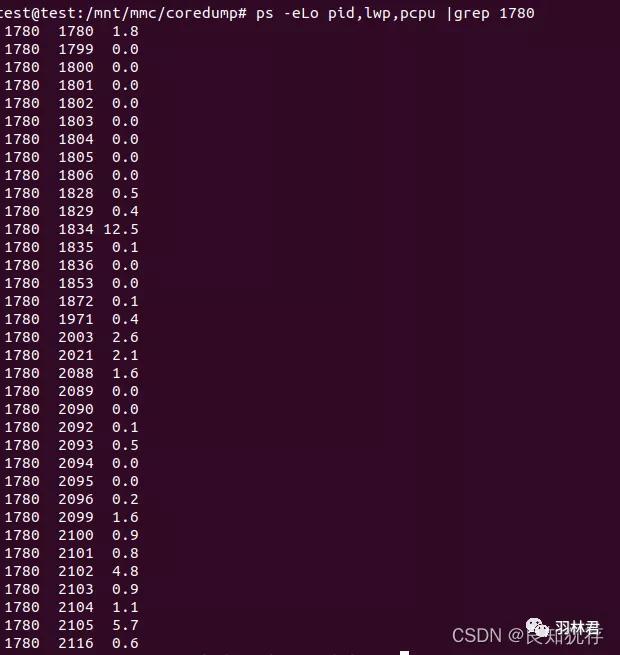
第一行是进程pid,第二行是进程里面线程对应的pid,第三行是该线程执行ms时间,通过线程执行时间长度,我们配合该线程的堆栈信息,线程频繁执行IO操作或者线程频繁执行的库函数来判断该线程是否错误占用cpu资源。
top组合命令介绍:
top命令也是大家熟悉的一个命令,可以显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等。同时也可以对指定进程发送一个信号。
- -b 批处理
- -c 显示完整的信息
- -I 忽略失效过程
- -s 保密模式
- -S 累积模式
- -i<时间> 设置间隔时间
- -u<用户名> 指定用户名
- -p<进程号> 指定进程
- -n<次数> 循环显示的次数
首先我们一般会直接使用top命令,查看进程信息,这里做一下多描述,因为后续使用strace工具还是使用ltrace工具,是从top命令的cpu信息区进行确定我们使用具体工具。
- test@test:~# top
- top - 02:32:07 up 17 min, 2 users, load average: 3.17, 3.26, 2.17
- Tasks: 165 total, 3 running, 162 sleeping, 0 stopped, 0 zombie
- %Cpu(s): 31.3 us, 7.0 sy, 0.0 ni, 60.9 id, 0.0 wa, 0.0 hi, 0.9 si, 0.0 st
- MiB Mem : 3845.3 total, 3424.3 free, 240.9 used, 180.1 buff/cache
- MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3566.7 avail Mem
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 461 root -96 -20 2432536 58472 18888 S 176.5 1.5 18:15.07 ex
- 375 root -2 0 0 0 0 S 5.9 0.0 0:04.23 RTW_RECV_THREAD
- 430 root 20 0 682204 22536 6880 S 5.9 0.6 0:55.69 python
- 16913 root 20 0 0 0 0 S 5.9 0.0 0:02.46 kworker/u12:0
- 22219 root 20 0 3300 2100 1628 R 5.9 0.1 0:00.02 top
- 1 root 20 0 1892 620 556 S 0.0 0.0 0:00.41 init
- 2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
- 3 root 20 0 0 0 0 S 0.0 0.0 0:00.14 ksoftirqd/0
- 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
- 7 root 20 0 0 0 0 R 0.0 0.0 0:02.24 rcu_sched
- 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
- 9 root rt 0 0 0 0 S 0.0 0.0 0:00.16 migration/0
- 10 root rt 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
top显示的统计信息:
top显示信息前五行是当前系统情况整体的统计信息区。这部分统计信息的解释参考文章《top命令》:
第一行,任务队列信息,同 uptime 命令的执行结果
- test@test:~# uptime
- 13:46:08 up 1:04, 1 user, load average: 0.00, 0.00, 0.00
具体参数说明情况如下:
- 02:32:07 — 当前系统时间
- up 17 min, — 系统已经运行了17分钟
- 2 users — 当前有2个用户终端登录系统
- load average: 3.17, 3.26, 2.17— load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
- 系统现在共有165个进程,其中处于运行中的有3个,162个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
- 31.3 us — 用户空间占用CPU的百分比。
- 7.0 sy — 内核空间占用CPU的百分比。
- 0.0 ni — 改变过优先级的进程占用CPU的百分比
- 60.9 id — 空闲CPU百分比
- 0.0 wa — IO等待占用CPU的百分比
- 0.0 hi — 硬中断(Hardware IRQ)占用CPU的百分比
- 0.9 si — 软中断(Software Interrupts)占用CPU的百分比
- 0.0 st 虚拟机管理程序为另一个处理器(从虚拟机中窃取)服务时,虚拟cpu进行非自愿等待所花费的时间
第四行,内存状态,具体信息如下:
- 3845.3 total — 物理内存总量(3.8GB)
- 3424.3 free — 空闲内存总量(3.2GB)
- 240.9 used — 使用中的内存总量(240.9MB)
- 180.1 buff/cache — 缓存的内存量 (180M)
第五行,swap交换分区信息,具体信息说明如下:
- 0.0 total — 交换区总量(0.0 GB)
- 0.0 free — 空闲交换区总量(0MB)
- 0.0 used — 使用的交换区总量(0MB)
- 3566.7 avail Mem — 可使用缓冲的交换区总量(3.5GB)
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
- PID — 进程id
- USER — 进程所有者
- PR — 进程优先级
- NI — nice值。负值表示高优先级,正值表示低优先级
- VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR — 共享内存大小,单位kb
- S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
- %CPU — 上次更新到现在的CPU时间占用百分比
- %MEM — 进程使用的物理内存百分比
- TIME+ — 进程使用的CPU时间总计,单位1/100秒
- COMMAND — 进程名称(命令名/命令行)
这是top的常规使用得到的信息,我们一般进行组合使用命令,我一般使用,
- top -Hp 461(461 此处为真实进程的pid大家自行替换)
通过-Hp命令,我可以查看指定进程的线程
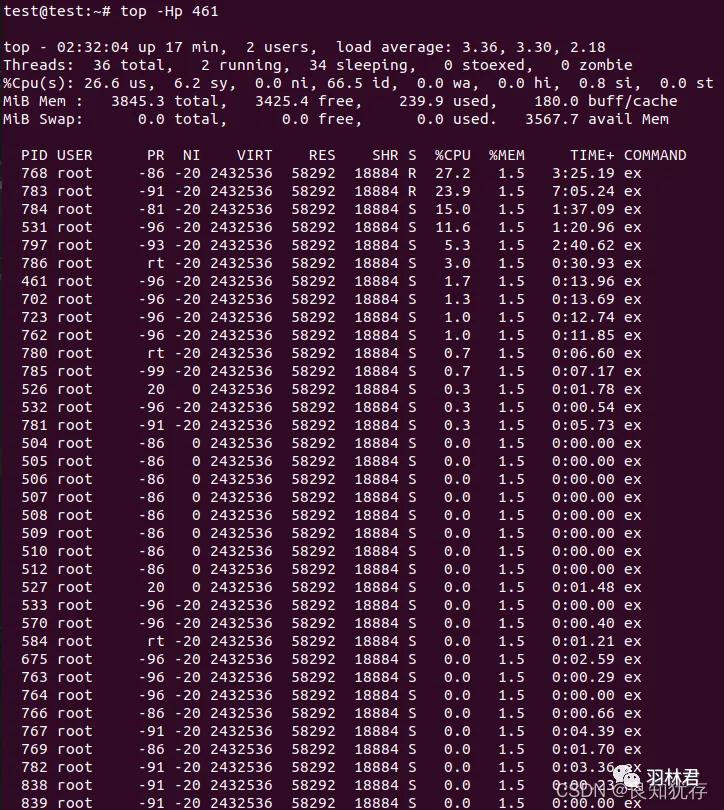
其中在统计信息的第三行中,可以看到cpu占用率主要是用户态。
那么我们应该最好使用ltrace进行用户态库函数的调用查询。当然strace也可以,但是由于内核使用占据cpu使用率不高,你追踪到的IO操作应该远少于用户态库函数调用。
pstack 的选项参数介绍:
pstack 是 Linux 系统下的一个命令行工具,此命令可以显示指定进程每个线程的堆栈快照,便于排查程序异常和性能评估,此命令允许使用的唯一选项是要检查的进程的 PID。要是要使用这个包大家需要在所使用的linux lib和斌目录里面增加该工具。
示例
- sudo pstack 16634(该pid为我自己测试电脑对应的进程 大家使用时候可以自行替换成自己对应的pid)

可以在一段时间内,多执行几次pstack,若发现代码栈总是停在同一个位置, 那个位置就需要重点关注,很可能就是出问题的地方;
ltrace 的选项参数介绍:
ltrace能够跟踪进程的库函数调用,它会显现出调用了哪个库函数,而strace则是跟踪进程的每个系统调用。ltrace跟踪进程调用库函数参数选项有什么?
ltrace 的选项参数介绍:
- -c 统计库函数每次调用的时间,最后程序退出时打印摘要。
- -C 解码低級别名称(内核级)为用户级名称。
- -d 打印调试信息。
- -e expr 输出过滤器,通过表达式,可以过滤掉你不想要的输出。
- -e printf 表示只查看printf函数调。
- -e!printf 表示查看除printf函数以外的所有函数调用。
- -f 跟踪子进程。
- -o flename 将ltrace的输出写入文件filename。
- -p pid 指定要跟踪的进程pid。
- -r 输出每一个调用的相对时间。
- -S 显示系统调用。
- -t 在输出中的每一行前加上时间信息。
- -tt 在输出中的每一行前加上时间信息,精确到微秒。
- -ttt 在输出中的每一行前加上时间信息,精确到微秒,而且时间表示为UNIX时间戳。
- -T 显示每次调用所花费的时间。
strace 的选项参数介绍:
strace常用来跟踪进程执行时的系统调用和所接收的信号。在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
- -f 跟踪目标进程,以及目标进程创建的所有子进程
- -t 在输出中的每一行前加上时间信息(-tt 表示微秒级)
- -T 显示每个系统调用所耗的时间
通过观察系统调用我们可以确认当前程序的行为,分析其消耗的时间、返回值是否正常。可以过滤指定的线程号,确认当前线程的行为是否符合预期,如果执行命令后完全没有输出,那么可以怀疑是否由于网络、IO等原因导致阻塞,或程序产生死锁。
pstree 的选项参数介绍:
命令将所有进程以树状图显示,树状图将会以 pid (如果有指定) 或是以 init 这个基本进程为根 (root),如果有指定使用者 id,则树状图会只显示该使用者所拥有的进程。要是要使用这个包大家需要在所使用的linux lib和斌目录里面增加该工具。
- -A: 各进程树之间的连接以ASCII码字符来连接
- -U:各进程树之间的连接以utf8字符来连接,某些终端可能会有错误
- -p:同时列出每个进程的PID
- -u: 同时列出每个进程的所属账号名称:
pstree -up 输出进程和子进程树形数据
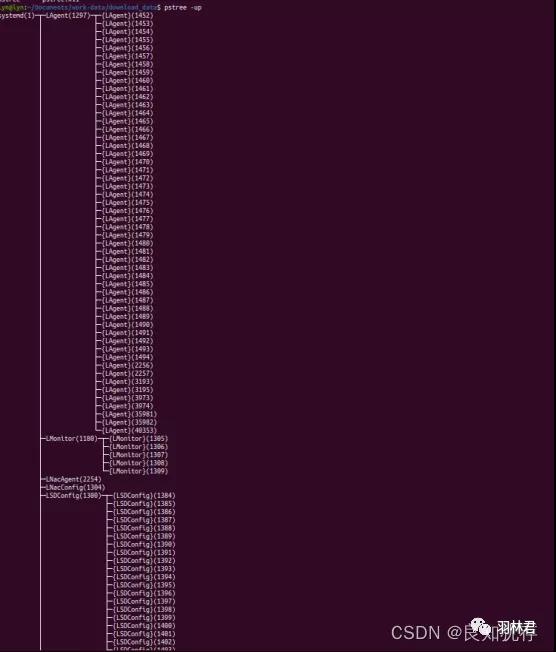
kill <sig> <pid>和coredump文件查看线程堆栈:
因为有些时候我们使用的linux环境下面不一定有很全的工具,例如上面所提到的pstack查看对应的线程,会有其他的一些命令和工具替代,这里我就给大家介绍两种我使用的方法,用来查看我实际的堆栈和对应的pid线程信息。
- kill -11 461
对应的进程就会 出现Segmentation fault (core dumped)
而我们设置了coredump文件的产生,产生条件里面有段错误信号,所以我发送了11信号给该进程。
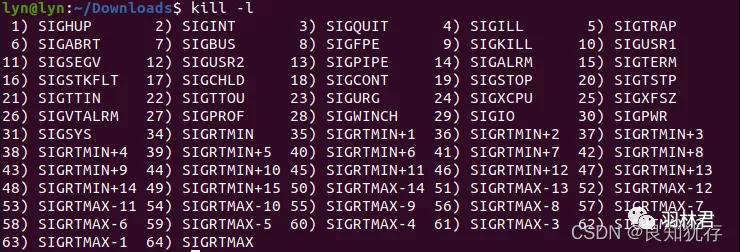
如果大家对于自己需要的信号不知道对应的数字,可以用 kill -l 命令查询。
至于通过coredump查看对应的堆栈信息,我之前的这篇文章写的比较全面了,这里就不再过多赘述了,大家可以点击这篇文章进行查看Linux开发coredump文件分析实战分享。
除了使用kill命令杀死指定进程,我们也可以通过top组合命令来杀死进程:首先使用top进入top显示的信息,其次假如我们选择好了 461这个进程准备杀死:
先输入 k 进入top的kill选项
- PID to signal/kill [default pid = 1451]
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 461 root -96 -20 2081464 28672 17756 S 21.7 1.4 0:07.05 exc
再按照提示输入 指定pid 461
- PID to signal/kill [default pid = 1451] 461
使用enter 之后,按照提示输入信号,我选择了 11( 段错误信号)
- Send pid 461 signal [15/sigterm] 11
这个操作等同于 kill -11 461
gdb attach <pid>实时调试:
这个是gdb中实时调试的工具,指定进程实时调试,但是实际中遇到大型代码,调试起来太卡了,所以基本不用它实时调试,我是用来它来进行实时看一些堆栈信息以及查看线程id和实际代码的匹配。操作也是比较简单,从上面我们可以获知你运行的进程的pid,你用gdb attach指定pid就可以进行调试了。进入之后的操作命令就是gdb调试的命令。
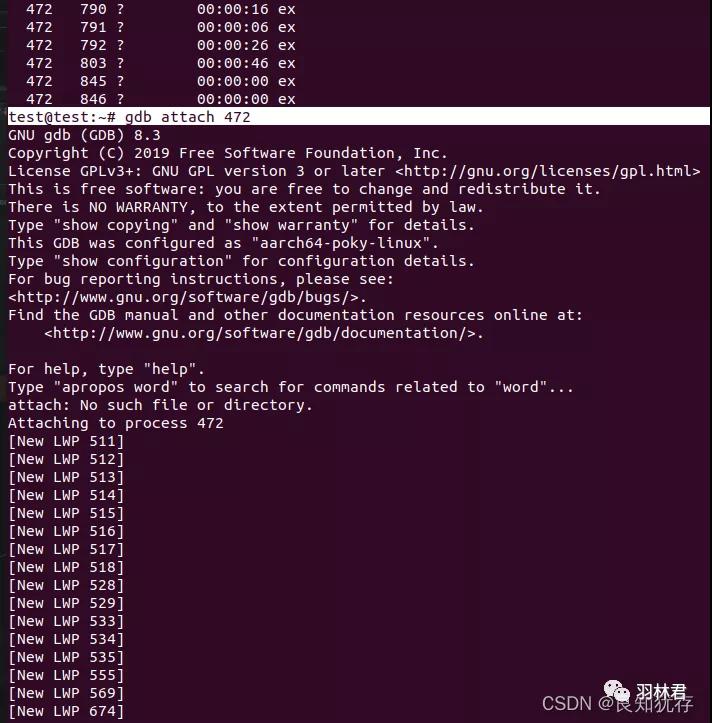
大家可以看到gdb attach一进来就在最前面显示对应的lwp线程pid,这个pid和我们用top命令和ps命令以及strace、ltrace打印的pid信息是一致的。通过相同的pid我们就可以知道该进程或者线程下执行的具体操作了。
输入gdb命令 thread apply all bt ,我们就可以看到对应线程的堆栈,通过堆栈的信息,我们就可以反向查找代码了。下面是一个截取,展示的是lwp 790(线程pid==790)的一个堆栈信息,通过#3 我们可以知道该线程代码在even_manager.cpp的40行

实战中的组合使用
通过上面的命令介绍,我们也知道了在linux下我们可以用到哪些工具可以分析我们的异常进程和线程,下面我就通过一个我自己实际遇到的情况,给大家实际介绍一下这些工具的组合使用情况。
首先,我先使用top命令查看我cpu使用情况
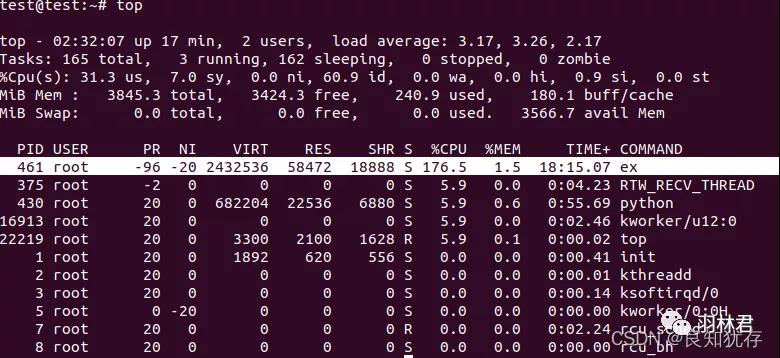
这一看,ex进程竟然占用了176%的cpu(我的设备是多核设备),也就是差不多两个核的cpu被占满了。此时可以看到主要占用的cpu资源是用户态的资源,所以推荐使用ltrace查看,但是我这边目前设备里面没有这个包,所以直接使用了strace查看。
接下来我就想知道到底该进程下的哪个线程,以及线程对应的是哪部分代码,频繁执行了什么操作。
所以我先使用了 top -Hp 461 查看我对应该进程下所有的线程执行所占cpu的百分比。
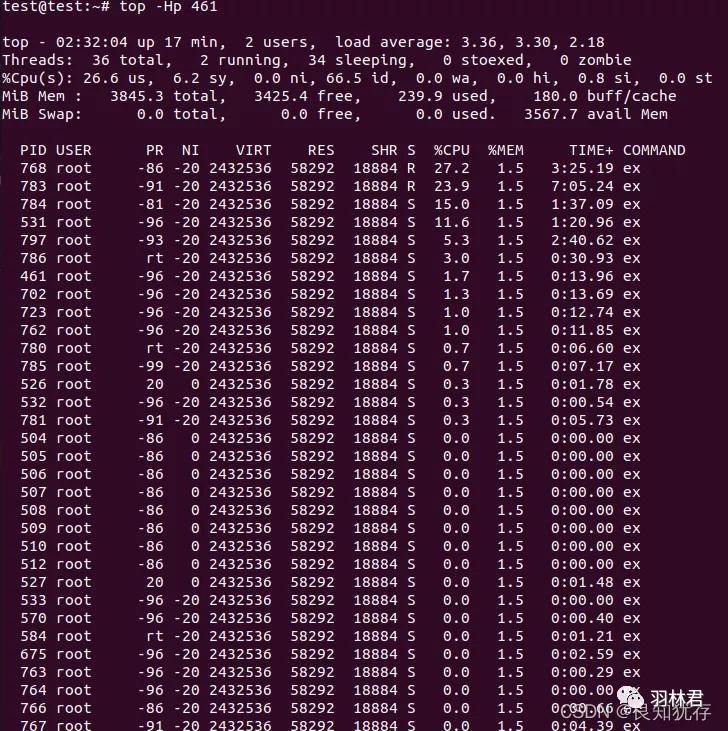
也可以使用 ps -T -p 461 查看进程对应的线程pid信息
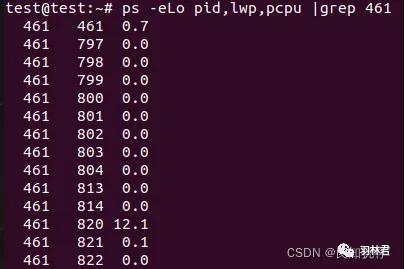
ps -eLo pid,lwp,pcpu |grep 461 查看线程执行消耗的时间
strace -p 461 -f进行查看该进程下执行了内核交互函数最多执行的部分
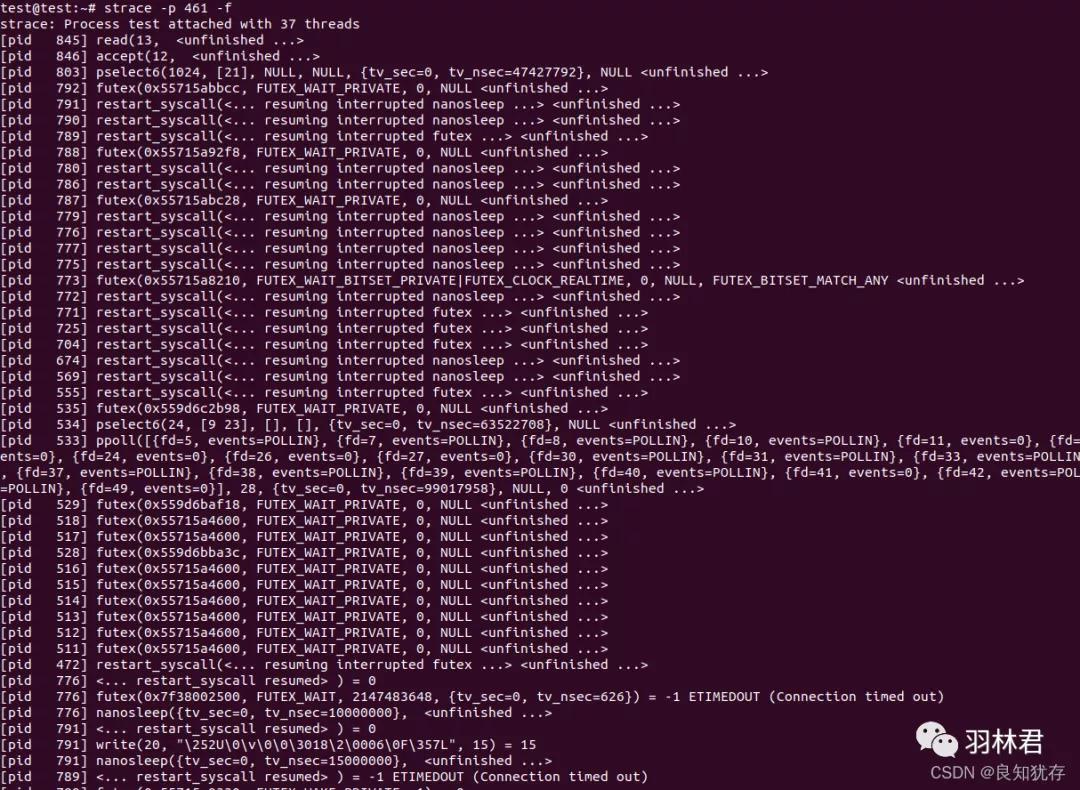
最左边的部分就是对应的执行IO函数下的线程PID,我们同时可以直接指定线程pid进行查询线程的操作,例如我们看到线程845在读fd为13的一个设备,我们可以单独strace -p 845.
本来应该是strace、ltrace、pstack配合使用,但是我使用的设备上没有ltrace和pstack,所以我使用gdb attach直接调试进程,查看对应的线程堆栈信息,用来确认top组合命令的出的线程pid信息和实际代码进行映射。
gdb attach 461 实时调试查看线程堆栈信息用来匹配实际的代码部分
进入之后直接使用 thread apply all bt 查看对应的线程堆栈信息,通过堆栈信息,我们就可以知道对应的代码部分
每一个堆栈信息的最上面有显示 lwp
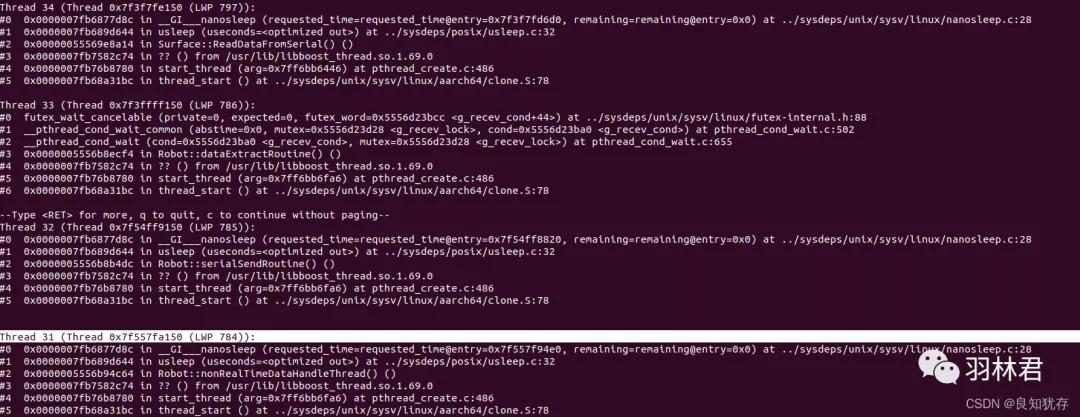
这时候我们就知道了该进程下有哪些线程,那我们还需要知道该线程对应的是代码哪一部分代码,以及线程具体执行了哪些操作。
strace和gdb attach命令等从开发初始来说是好的技术,但是实际使用中,由于代码复杂性,以及c受限与cpu,在我strace和gdb attach使用中,这些工具因为要一直监控进程,会很占用你cpu资源,甚至gdb attach开始调试,机器直接运行非常缓慢,远程ssh登录都卡住了。所以只能用一些消耗资源少的操作进行查看信息,就像内存分析中的mtrace和valgrind,一启动使用,机器直接卡停。所以很多时候工具虽好,但是实际只能辅助一些而已,更重要我们要规范写代码。
结语
这就是我分享我在工作中使用的一些linux线程监控的操作,如果大家有更好的想法和需求,也欢迎大家加我好友交流分享哈。
作者:良知犹存,白天努力工作,晚上原创公号号主。公众号内容除了技术还有些人生感悟,一个认真输出内容的职场老司机,也是一个技术之外丰富生活的人,摄影、音乐 and 篮球。关注我,与我一起同行。