












1.序篇
书接上回,上节说到了博主发现由于在 flink sql 中 lookup join 访问外部维表存在的性能问题。
由此诞生了一个想法,以 Redis 维表为例,Redis 支持 pipeline 批量访问模式,因此 flink sql lookup join 能不能按照 DataStream 方式一样,先攒一批数据 ,然后使用 Redis pipeline 批量访问外部存储。博主亲切的将这个功能称为 flink sql batch lookup join,本节就是讲述博主基于 flink 源码对此功能的实现。
废话不多说,咱们先直接上本文的目录和结论,小伙伴可以先看结论快速了解博主期望本文能给小伙伴们带来什么帮助:
- 直接来一个实战案例:博主以曝光用户日志流关联用户画像(年龄、性别)维表为例介绍 batch lookup join 具有的基本能力(怎么配置参数,怎么写 sql,最终效果咋样)。
- batch lookup join:主要介绍 batch lookup join 的功能是从 flink transformation 出发,确定要 batch lookup join 涉及改动的地方以及其实现思路、原理。也会教给大家一些改动源码来实现自己想要的一些功能的思路。
- 总结及展望:目前的 batch lookup join 实现其实不符合 sql 的原始语义,后续大家可以按照 sql 标准自己做一些实现
2.来一个实战案例
2.1.预期的输入、输出数据
来看看在具体场景下,对应输入值的输出值应该长啥样。
需求指标:使用曝光用户日志流(show_log)关联用户画像维表(user_profile)关联到用户的画像(性别,年龄段)数据。
来一波输入数据:
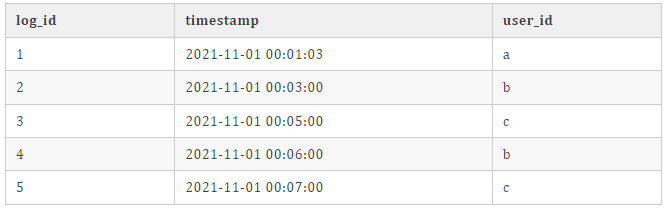
曝光用户日志流(show_log)数据(数据存储在 kafka 中):
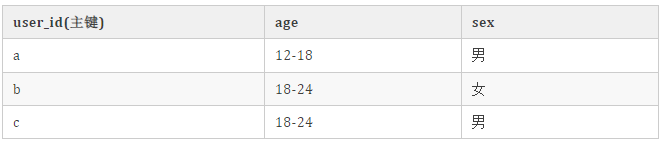
用户画像维表(user_profile)数据(数据存储在 redis 中):
注意:redis 中的数据结构存储是按照 key,value 去存储的。其中 key 为 user_id,value 为 age,sex 的 json。如下图所示:
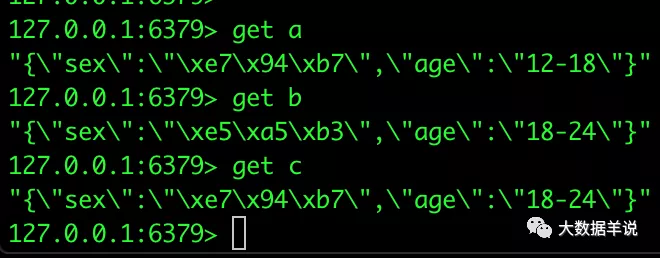
user_profile redis
预期输出数据如下:
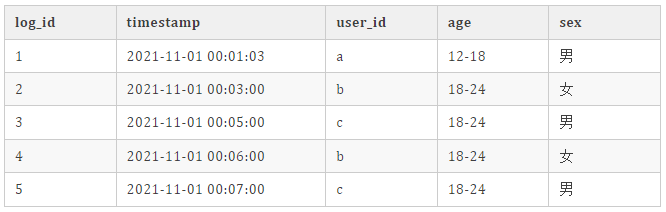
2.2.batch lookup join sql 代码
batch lookup join sql 代码和原来的 lookup join sql 代码一模一样。如下 sql。
- CREATE TABLE show_log (
- log_id BIGINT,
- `timestamp` as cast(CURRENT_TIMESTAMP as timestamp(3)),
- user_id STRING,
- proctime AS PROCTIME()
- )
- WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '10',
- 'fields.user_id.length' = '1',
- 'fields.log_id.min' = '1',
- 'fields.log_id.max' = '10'
- );
- CREATE TABLE user_profile (
- user_id STRING,
- age STRING,
- sex STRING
- ) WITH (
- 'connector' = 'redis',
- 'hostname' = '127.0.0.1',
- 'port' = '6379',
- 'format' = 'json',
- 'lookup.cache.max-rows' = '500',
- 'lookup.cache.ttl' = '3600',
- 'lookup.max-retries' = '1'
- );
- CREATE TABLE sink_table (
- log_id BIGINT,
- `timestamp` TIMESTAMP(3),
- user_id STRING,
- proctime TIMESTAMP(3),
- age STRING,
- sex STRING
- ) WITH (
- 'connector' = 'print'
- );
- -- lookup join 的 query 逻辑
- INSERT INTO sink_table
- SELECT
- s.log_id as log_id
- , s.`timestamp` as `timestamp`
- , s.user_id as user_id
- , s.proctime as proctime
- , u.sex as sex
- , u.age as age
- FROM show_log AS s
- LEFT JOIN user_profile FOR SYSTEM_TIME AS OF s.proctime AS u
- ON s.user_id = u.user_id
可以看到 lookup join 和 batch lookup join 的代码是完全相同的,唯一的不同之处在于,batch lookup join 需要设置 table config 参数,如下图所示:
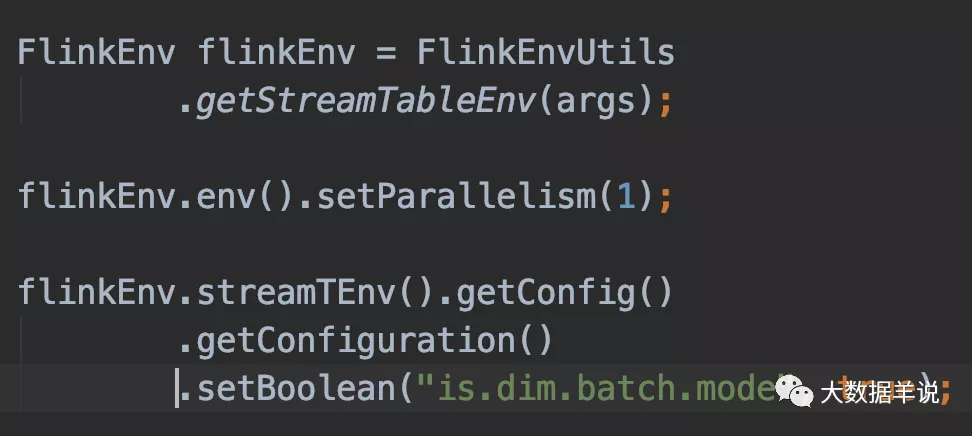
table config
2.2.batch lookup join 效果
将原生 lookup join 和 batch lookup join 的效果做个对比:
原生的 lookup join:每输入一条数据,访问外部维表获取到结果输出一条数据,如下图所示。
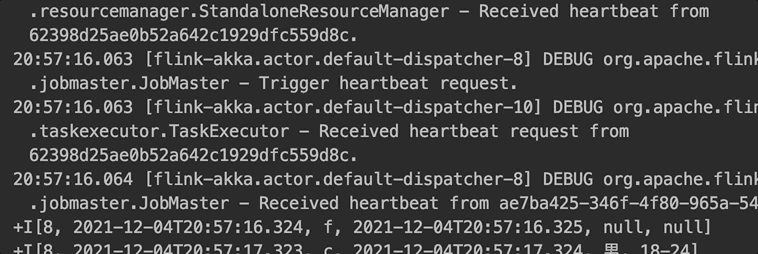
lookup join
博主实现的 batch lookup join:是每攒够 30 条数据或者每 5s(防止数据量少的情况下,长时间不输出数据) 就利用 redis pipeline 能力访问外部存储一次。然后批量输出结果,如下图所示。大大提高了吞吐。
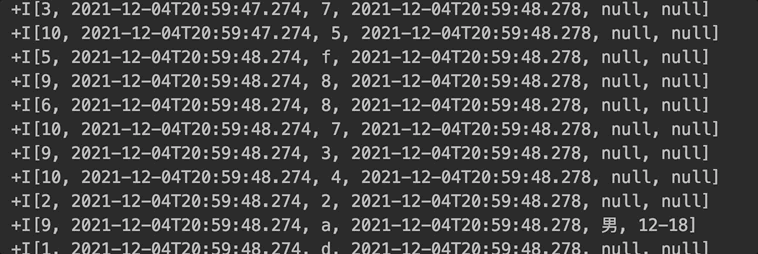
batch lookup join
3.batch lookup join 实现
3.1.怎么知道应该改哪部分源码?
博主将通过下面几个问题去交给大家怎么改源码去实现自己的功能。
改源码的有哪些比较好的思路?
结论:首先就是参考类似模块的实现(不会写,但是我会抄啊!),比如本文要实现 batch lookup join,必然要参考原生的 lookup join 去实现。
大家在改 flink 源码时,因为 flink 源码的模块太多了,项目非常庞大,往往第一步碰到的问题不是怎么去实现这个功能,而是应该在什么地方去改才能实现!
结论:一个 flink 的任务(DataStream\Table\SQL)所有的精华精华精华都集中在 transformation 中!!!只要是涉及到算子实现的东西,小伙伴萌就可以到 transformation 中去寻找。可以将断点打在每一个 operator 的构造器或者 open 方法中就可以看到其实在哪一步构造和初始化的。这样就能顺着调用栈往前回溯而确定要改哪部分代码了。
3.2.lookup join 原理
3.2.1.transformation
在实现batch lookup join 之前,当然要从原生的 lookup join 的实现开始入手,看看 flink 官方大大是怎么实现的,具体 transformation 如下图所示:
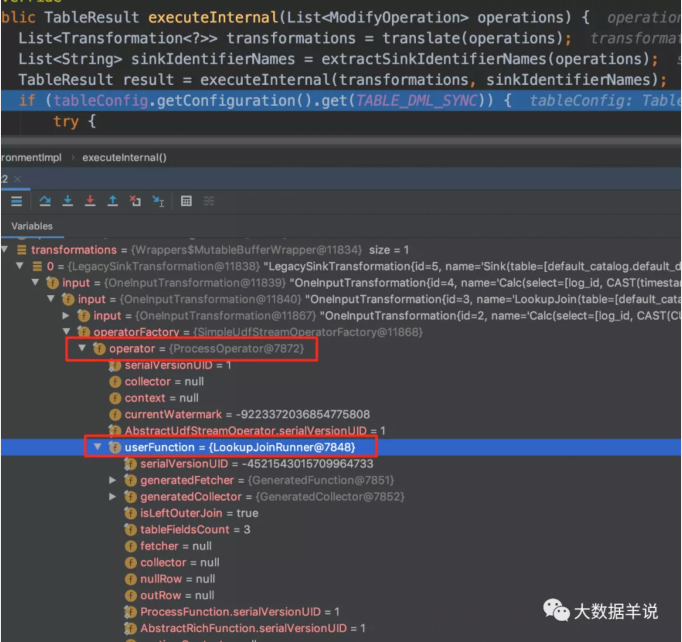
transformation
具体的实现逻辑承载在 org.apache.flink.streaming.api.operators.ProcessOperator,org.apache.flink.table.runtime.operators.join.lookup.LookupJoinRunner 中。
3.2.2.LookupJoinRunner
LookupJoinRunner 中的数据处理逻辑集中在 processElement 中。
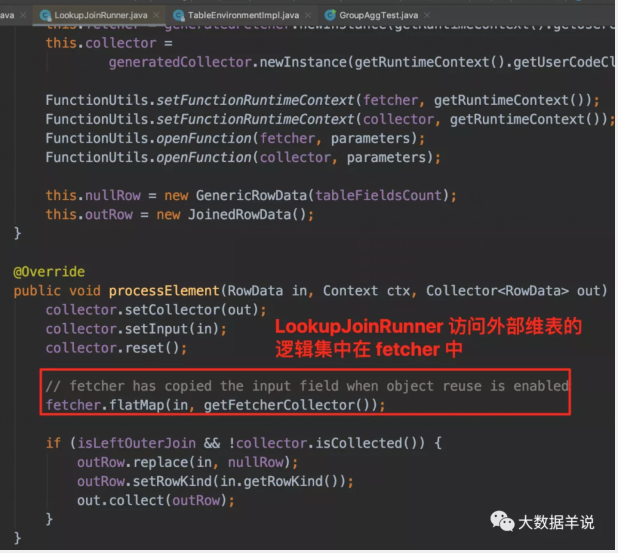
LookupJoinRunner
可以看到上图,LookupJoinRunner 又内嵌了一层 fetcher 来实现具体的 lookup 逻辑。
- 其中 fetcher:就是根据 flink sql lookup join 逻辑生成的 lookup join 的代码实例;
- 其中 collector:collector 的主要功能就是将原始数据 RowData 和 lookup 到的 RowData 的数据合并为 JoinedRowData 结果,然后输出。
接下来详细看看 fetcher 和 collector。
3.2.3.fetcher
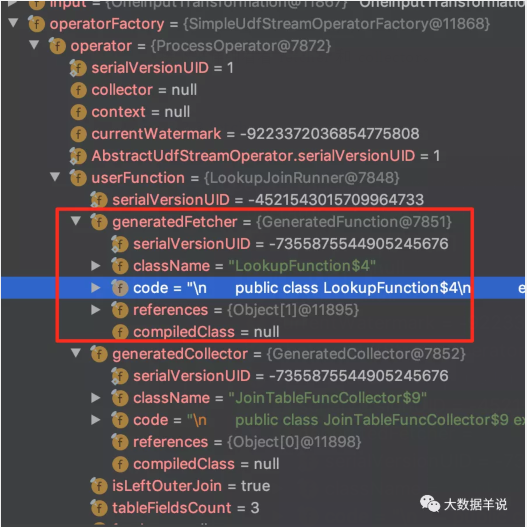
transformation fetcher
把这个 fetcher 的代码 copy 出来瞅瞅。
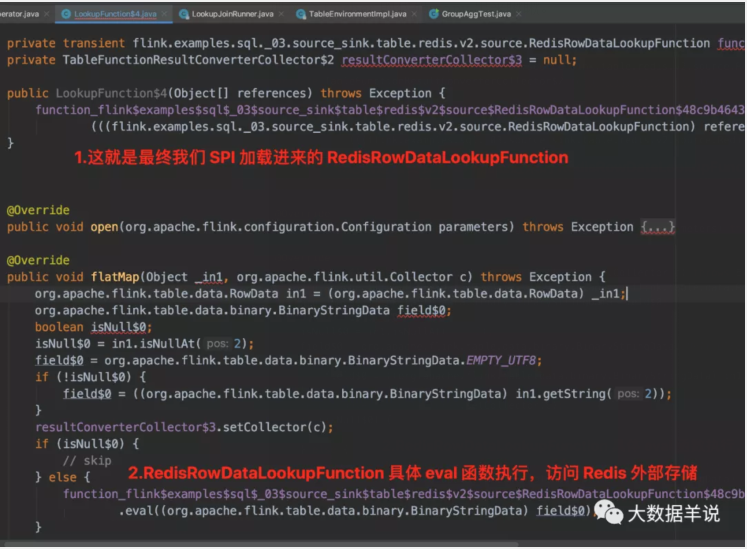
fetcher
fetcher 内嵌了 RedisRowDataLookupFunction 来作为最终访问外部维表的函数。
3.2.4.RedisRowDataLookupFunction
访问 redis 获取到数据。
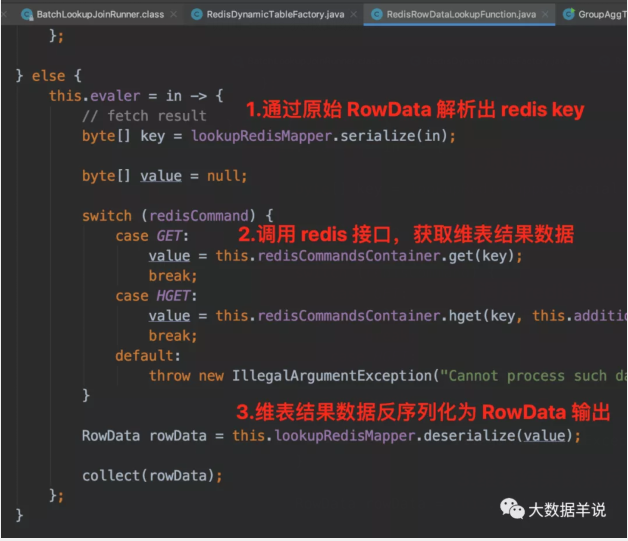
RedisRowDataLookupFunction
3.2.5.collector
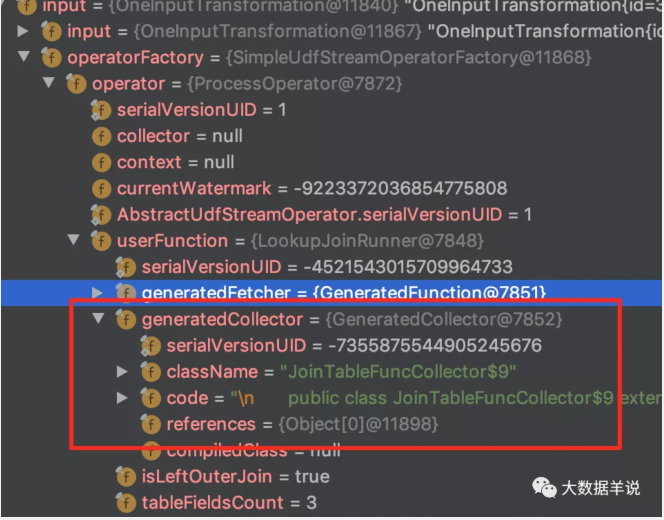
transformation collector
把这个 collector 的代码 copy 出来瞅瞅。
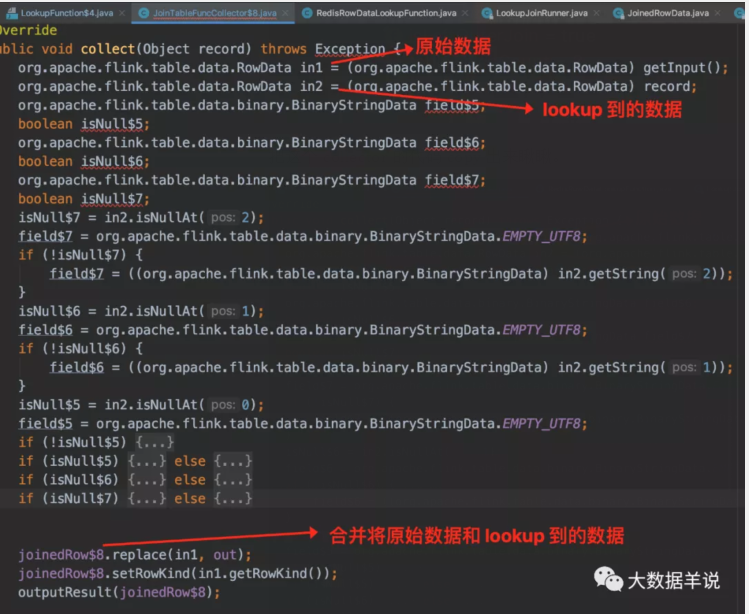
collector
3.3.lookup join 算子实现调用链
是不是感觉一个 lookup join 的调用链贼复杂。
因为 batch lookup join 是完全参考 lookup join 去实现的,所以接下来博主介绍一下整体的调用链关系,这就会方便后续设计 batch lookup join 实现方案的时候去确定具体修改哪一部分代码。
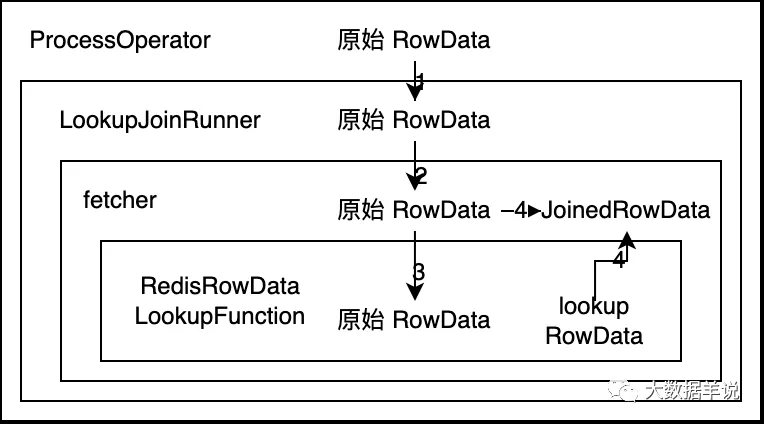
调用链
整体的调用逻辑如下:
- ProcessOpeartor 把 原始 RowData 传给 LookupJoinRunner
- LookupJoinRunner 把 原始 RowData 传给根据 sql 代码生成的 fetcher
- fetcher 中把 原始 RowData 传给 RedisRowDataLookupFunction 然后去 lookup 维表,lookup 到的结果数据为 lookup RowData
- collector 把 原始 RowData 和 lookup RowData 数据合并为 JoinedRowData 然后输出。
3.4.batch lookup join 设计思路
还是一样,先看看设计思路最终的结论,batch lookup join 算子调用链设计如下:
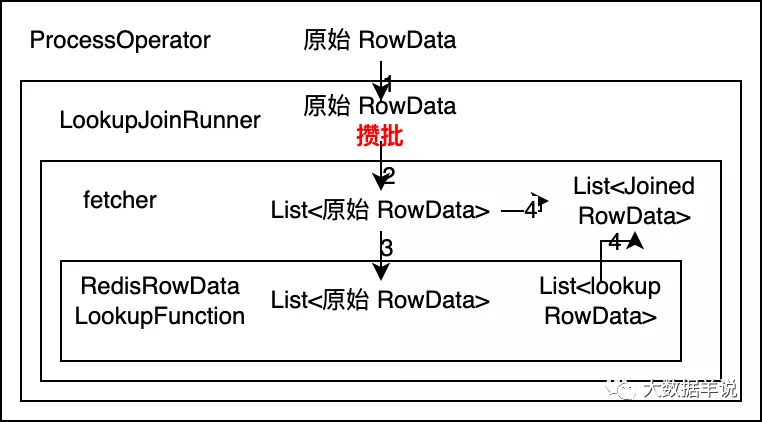
batch lookup 调用链
详细说明一下设计思路:
- 如果想做到批量访问外部存储(Redis)的数据。可以推断出 RedisRowDataLookupFunction 的输入需要是 List<原始 RowData> ,输出需要是 List
。其中输入数据输入到 RedisRowDataLookupFunction 中后,使用 Redis pipeline 去批量访问外部存储,然后把结果 List 输出。 - 由 RedisRowDataLookupFunction 的输出数据为 List
推断出 collector 输入数据格式必然是 List<原始 RowData>。由于在 lookup join 中 collector 的逻辑就是将 原始 RowData 和 lookup RowData 合并为 JoinedRowData,将结果输出。因此 collector 这里就是将 List<原始 RowData> 和 List 进行遍历合并,一条一条的输出 JoinedRowData。 - 同样 RedisRowDataLookupFunction 的输入数据是 fetcher 传入的,则推断出 fetcher 输入数据格式必然是 List<原始 RowData>。
- 由于 fetcher 输入是 List<原始 RowData>,则 LookupJoinRunner 输出到 fetcher 的数据也需要是 List<原始 RowData>。但是 ProcessOpeartor 只能传给 LookupJoinRunner 原始 RowData,因此可以得出我们的每攒 30 条数据或者每隔 5s 的逻辑就能确定需要在 LookupJoinRunner 中做了。
思路有了,那么 batch lookup join 涉及到的改动项也就能确认了。
- 新建一个 BatchLookupJoinRunner:实现攒批逻辑(每攒 30 条数据或者每隔 5s),其中攒批的数据放在 ListState 中,以防止丢失,在 table config 中的 is.dim.batch.mode 设置为 true 时使用此 BatchLookupJoinRunner。
- 代码生成的 fetcher:将原来输入的 原始 RowData 改为 List<原始 RowData>。
- 新建一个 RedisRowDataBatchLookupFunction:实现将输入的批量数据 List<原始 RowData> 拿到之后使用 redis pipeline 批量访问外部存储,获取到 List
结果数据给 collector。 - 代码生成的 collector:将原来 lookup join 中的输入 原始 RowData,lookup RowData 改为 List<原始 RowData>,List
,添加遍历循环 List<原始 RowData>,List ,按顺序合并 List 中的每一项 原始 RowData,lookup RowData 输出 JoinedRowData 的逻辑。
3.5.batch lookup join 的最终效果
3.5.1.transformation
可以看到 is.dim.batch.mode 设置为 true 时,transformation 如下。transformation 中的重点处理逻辑就是 BatchLookupJoinRunner
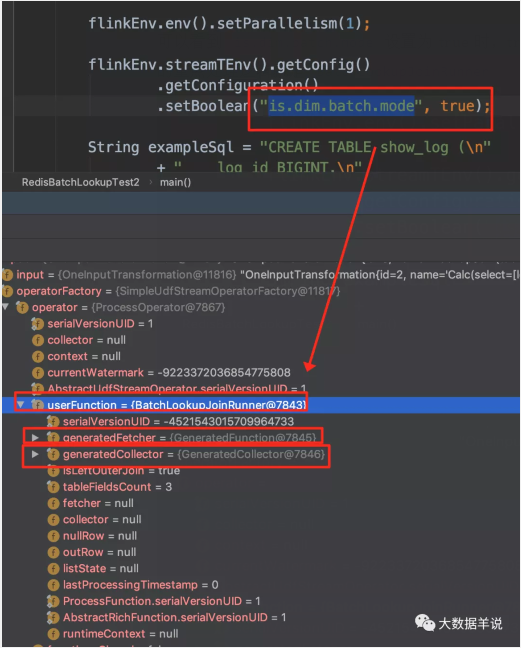
batch transformation
3.5.2.BatchLookupJoinRunner
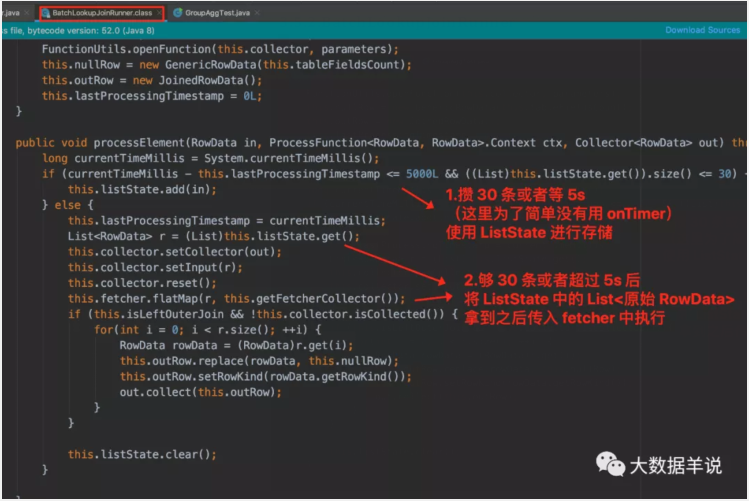
BatchLookupJoinRunner
3.5.3.fetchersql 生成的 fetcher 代码如下:
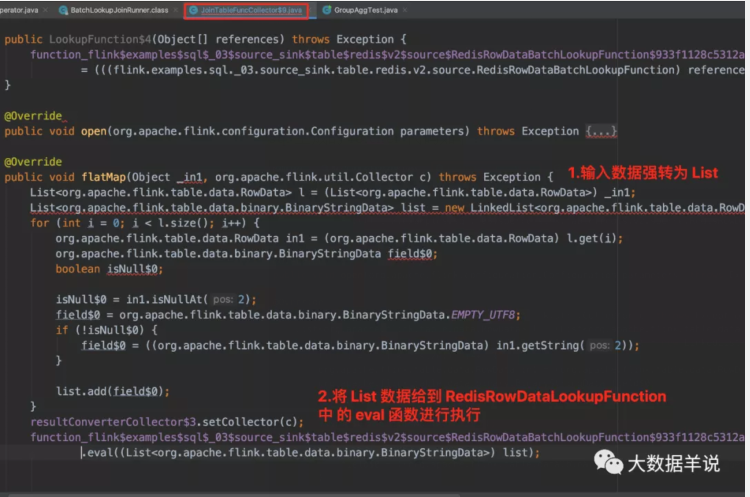
fetcher
3.5.4.RedisRowDataBatchLookupFunction
RedisRowDataBatchLookupFunction 拿到输入的 List 数据,调用 Redis pipeline 批量访问外部存储。
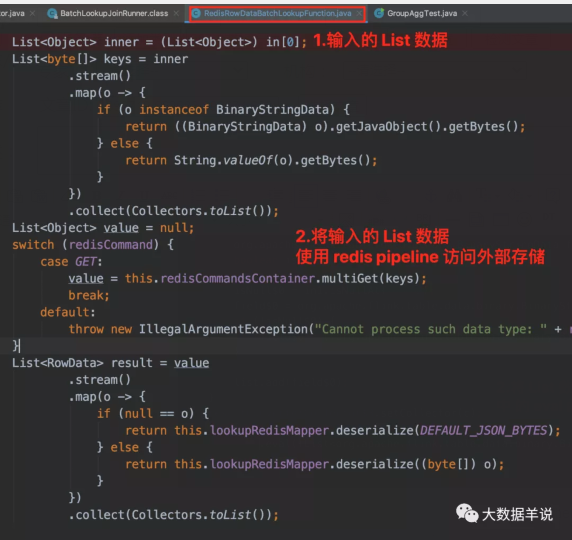
RedisRowDataBatchLookupFunction
3.5.5.collectorsql 生成的 collector 代码如下:
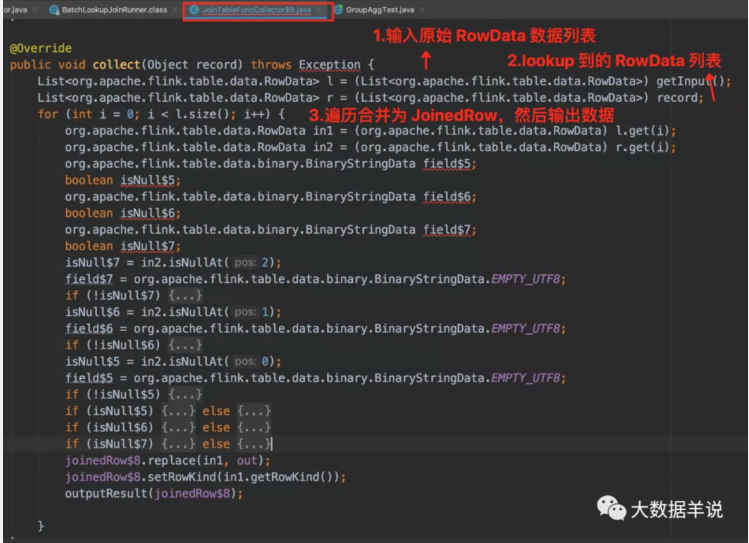
collector
3.6.待改进项
目前上述方案实现的不足之处如下:
- batch 的执行逻辑与 sql 原始的语义不一致。因为从 sql 上看是完全没有这种 batch lookup join 的语义的。
- 其中每 5s博主简单实现了下,完全基于数据驱动的每 5s 攒一批,不是基于 onTimer 驱动的。可能会出现来了一条数据之后,5 min 内都没有来数据,则数据就不输出了。
- 没有考虑实现代码的抽象,以实现功能为主,所以很多基于源码的改动都是直接 copy 出来了另一个方法实现。
4.xdm 怎么使用这个功能?
git clone https://github.com/yangyichao-mango/flink/tree/release-1.13.2
在 clone 下来的项目的中,重新把下面两个模块 install (mvn clean install) 到本地仓库中。
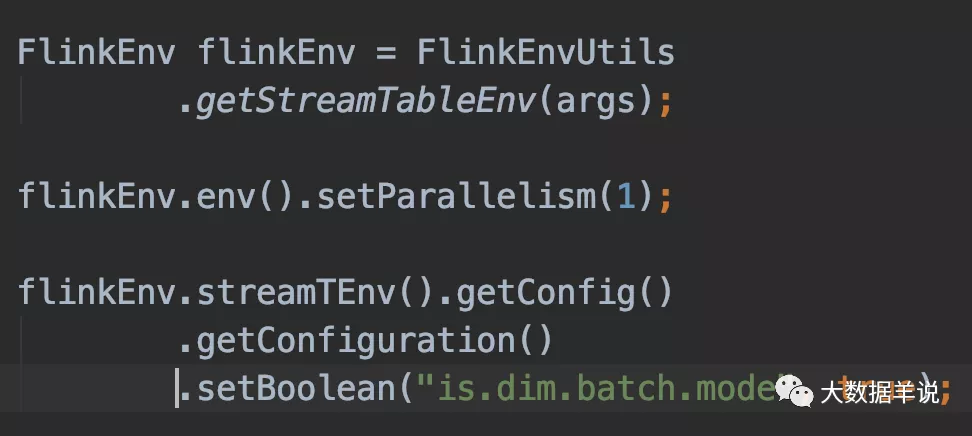
然后在你的项目中引用两个 blink 包即可使用。使用方法就是只需要把 table config 的 is.dim.batch.mode 设置为 true,代码还按照 lookup join 的方式写即可。
5.总结与展望
本文主要介绍了 flink sql batch lookup join 的使用方式,并介绍了其实现思路以及效果,主要内容如下:
直接来一个实战案例:博主以曝光用户日志流关联用户画像(年龄、性别)维表为例介绍 batch lookup join 具有的基本能力(怎么配置参数,怎么写 sql,最终效果咋样)。
batch lookup join:主要介绍 batch lookup join 的功能是从 flink transformation 出发,确定要 batch lookup join 涉及改动的地方以及其实现思路、原理。也会教给大家一些改动源码来实现自己想要的一些功能的思路。
总结及展望:目前的 batch lookup join 实现其实不符合 sql 的原始语义,后续大家可以按照 sql 标准自己做一些实现























