













读完本文,让你彻底明白Windows下中文乱码的问题。一劳永逸地解决这个困扰很多同学的问题。
前言
在桌面开发过程中,由于Qt的跨平台特性,以及更加先进的库封装。比起MFC,用着不知道要爽多少。Qt独创的信号槽机制,也大大方便了开发者。可以让开发者把更多的精力放在业务的逻辑上,而不是语言和库的各种细节上。
可是,在使用的过程中,不少朋友在中文Windows系统下,遇到了乱码的问题。着实头痛,网上搜了一圈,有时能解决问题,有时不知道什么原因的情况下又出现了奇怪的问题。同样的问题在cocos2d-x中也会出现。
小伙伴们不要灰心,这个问题连大佬们都头痛。哈哈~~,请看下面的案例。

上面的问题来自《Cocos2d-x实战:C++卷》,大佬也很无奈啊。
今天,让我们来自己剖析一下这个问题。并最终找到一劳永逸的解决方案。
在开始前,我们先来罗列一下遇到的几种情况:
- 完全正常。(人品大爆发啊)
- 直接乱码。(哎,时运不济)
- 编译报错——C4819,C2001、C2143。(这是犯了什么天条了吗?)
- 很小心的使用,可能正常。有时正常,有时编译报错,有时末尾的字是乱码,前面的正常。(这是什么鬼啊)。
细心的小伙伴还总结出了,偶数个中文字符正常,奇数个就不行了。后面再加个英文字符,前面的显示正常,后面一个字符乱码。(我也太难了吧~~~)
一、字符编码
要彻底理解这个问题,我们需要从字符编码说起,小伙伴们稍微有点耐心,这个其实很容易理解。字符编码说白了就是一张对照表。
1.1 ASCII编码
这个编码很容易,就用了一个字节进行编码,只能表示英文字符和标点符号。这里我就不过多赘述了,百度一下,就有很多文章有详细讲解。
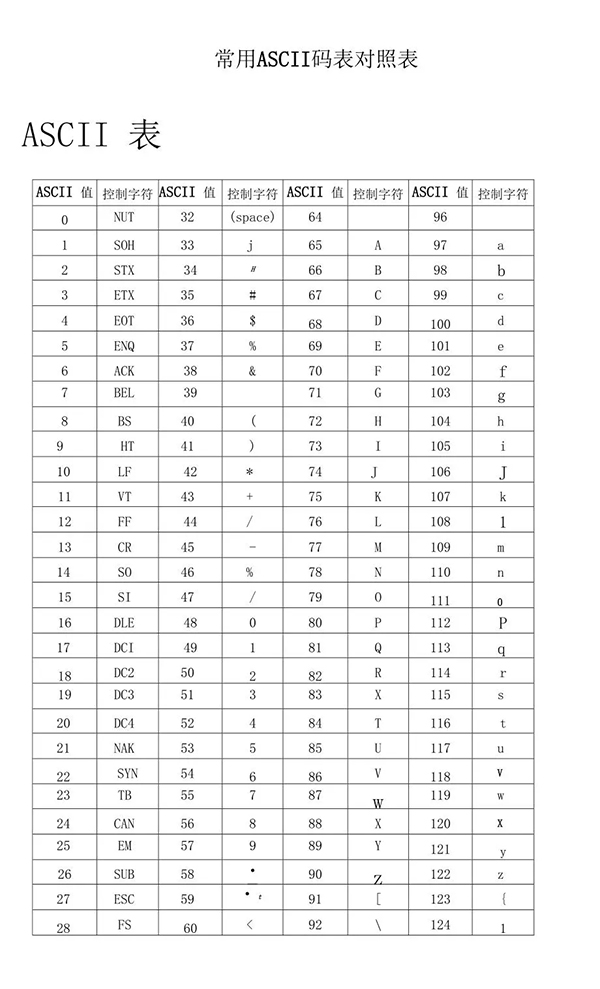
ASCII编码表
1.2 中文编码
计算机刚开始被发明的时候,只有ASCII编码。也就是说只有英文,那我们怎么办呢?没有人帮我们做,那只有自己来了,在1980年,国家标准总局发布了GB2312,其实就是一张中文的编码对照表。这也不是很复杂的东西,因为单个字节只有256种可能,也就是说,最多只能表示256种字符。那么我们就再多用一个字节呗,在GB2312中,中文就用2个字节进行表示。2^16 = 65536,有这么多种可能,编码汉字绰绰有余了。
当然,考虑到兼容ASCII编码,当第一个字符数字小于127时,就表示ASCII字符,用一个字节就够了。当遇到第一个字符大于127时,就要结合第二个字符来决定是哪个中文字符了。
刚开始GB2312把6000多个中文编了进去,后来发现不够用,又增加了20000多个字符(包括繁体字),编码方案名称改为GBK。再后来,又增加了几千个少数民族字符,编码方案名称改为GB18030。到这里,我们就知道GB2312、GBK、GB18030的编码方式是一脉相承的。为了后面叙述的方便,我们统称这种为GBK编码。
1.3 Unicode编码
在中国使用GBK编码方案的同时,其他国家和地区为了使用自己的文字,也纷纷进行对自己的语言文字进行编码。造成的结果就是,不通用!不同语音的操作系统下编辑的文档,在另一台不同语音的计算机中打开就是乱码。
随着全球化的发展,急需一种统一的编码方案,来解决这种混乱的局面。
最终,ISO拿出了Unicode编码,废弃所有地区性的编码方案。重新编码,所有的字符统一采用2个字节进行存储。
GBK编码方案和Unicode编码完全不同,这也是乱码的根源。
二、文件编码
2.1 UTF-8编码
虽然上文中讲到ISO将字符进行了重新编码,并发布了Unicode。每个字符采用2个字节,16位进行编码。对于使用英语的国家来说,原来采用的是ASCII编码,那么所有的文件大小都会变成原来的2倍。这个浪费太大了,于是UTF-8就出现了。
如果用语言描述UTF-8,有些复杂。我们来举个例子,就很容易明白了。
比如,“中”这个字,Unicode编码为:0x4E2D。用二进制写就是(0100-1110-0010-1101),那么用UTF-8,怎么进行表示呢?
1110 0100
1011 1000
1010 1101
我来解释一下,第一个字节,前面的4位中有连续的3个1,表示这个字符需要有3个字节组成。
第二个字节,前面的2位10,表示上接前面的字节,后面的6位是编码。
第三个字节同第二个字节,前面的10和后面的编码。
也就是说,16位的Unicode编码,被分散到3个字节中。
好麻烦啊……的确,遇到中文或其他多字节编码的字符是有点麻烦,但是如果是英文字符,直接就用ASCII编码保存了。直接完全兼容原来的英文文档,他们就是有这么多的优越性,没办法,毕竟计算机技术来自他们那儿。
2.2 ANSI编码
这又是什么编码?细心的小伙伴会发现,你在Windows系统上用记事本编辑完文件,点另存为的时候,右下角默认的编码就是ANSI。这是Windows为了兼容各种不同的编码,而这样做的。
其实,他的做法非常简单,如果遇到小于127的编码,就是ASCII编码,计算机都认识这个编码,对于大于127的编码,也不用管那么多了,按原样保存就行了。
三、一劳永逸地消除乱码
在解决问题前,我们再稍微了解一些背景知识,小伙伴们不要着急啊!
3.1 UTF-8和UTF-8-BOM
UTF-8都够复杂了,还来个UTF-8-BOM??
其实,不必担心,这个也是非常简单的。
让我们先来看个例子:

上图,我们在记事本中写入“中文”,然后,以utf-8保存。
再用notepad++查看存入的内容,以十六进制显示。这样没有问题。
但是,如果再次打开,还会正确显示吗?记事本怎么知道我们是按utf-8存储的呢?如果这个十六进制的串,用GBK解码就是“涓枃”,是不是有点眼熟啊?我们遇到乱码的时候,也经常是这种类似的字符。
现在,记事本工作得好好的,但是他有些时候会不会认错呢?还真会,用记事本新建一个文本文件,输入“联通”,保存,再打开。你是不是看到了微软对联通满满的恶意?哈哈O(∩_∩)O哈哈~
其实,各种软件在处理文本文件的时候,经常会搞错!为了解决这种问题,就引入了utf-8-bom。
做法非常简单,在utf-8文件的开头加入ef bb bf 三个字节,标示这是一个utf-8的文件,告诉软件,你可别认错了。
3.2 编辑器和编译器对文件的处理
在Qt5 + VS的环境中,编辑器对于我们的源文件解析的完全没有问题。
可惜的是VS的编译器却不是像我们想像的进行工作的。
VS的编译器经常认错utf-8文件为ANSI文件,曾经有小伙伴把这个问题,向微软提交了这个bug,得到的回复如下
The compiler when faced with a source file that does not have a BOM the compiler reads ahead a certain distance into the file to see if it can detect any Unicode characters - it specifically looks for UTF-16 and UTF-16BE - if it doesn't find either then it assumes that it has MBCS. I suspect that in this case that in this case it falls back to MBCS and this is what is causing the problem.
翻译过来,就是当编译器遇到不带BOM的utf-8文件,会读入一部分进行判断是否UTF-16和UTF-16BE,如果不是就按照MBCS方式处理。
它根本就不进行utf-8文件的判断啊,Qt默认保存的就是utf-8文件,并且不带bom。然后,被按照MBCS方式识别,在我们的环境中,就是按照ANSI方式来处理。
好家伙,,,这么偷懒啊,造成了我们无穷的麻烦……
之前微软为了这个问题,还出过在文件开头加上#pragma execution_character_set("utf-8")的方式,后来也被废弃了。
到这里,我们明白了,Qt默认保存的utf-8文件(不带bom),被VS的编译器认成了ANSI格式的文件,就是乱码的根源。
3.3 Qt中QString对中文的处理
Qt中有QString字符串类,使用非常方便。
经常我们使用2种常用的方式:
QString str1("中文");
QString str2 = QString::fromLocal8Bit("中文");
需要明确的是第一种方法,也就是QString默认构造函数,接受的是utf-8字节序列。第二种方法,接受的是GBK字节序列。
3.4 解决方案
到这里为止,相信大家对怎么解决中文乱码的方案已经猜出来了。那就是:
在Qt中设置所有保存的文件都是utf-8-bom格式
在需要使用到中文的地方需要使用QString::fromLocal8Bit()方式。
3.5 编译出错的问题
到这里,细心的小伙伴就会意识到,虽然,我们乱码的问题得到了解决,但还是不明白前面4种现象中的后两种是什么情况。这里,我就再给大家解释一下。
char * str = "中文中";
看上面的代码,如果我们保存在utf-8文件中,而编译器把我们的文件认成了ANSI格式的,也就是中文部分安装GBK来解析。我们看“中文中”这三个字的utf-8编码
e4 b8 ad e6 96 87 e4 b8 ad
三个中文字符被编码成了9个字节,在编译器按照GBK编码进行解析,因为GBK编码中,中文字符需要两个字节,就把后面的分号就给吞噬掉了。源文件少了个分号,编译肯定是通不过的。
还剩最后一个问题,如果是
char * str = "中文中 ";
后面多添了一个空格,引号中的utf编码为:
e4 b8 ad e6 96 87 e4 b8 ad 20
刚好是10个字节,所以,编译没有报错,但是在编译器编译的过程中,是按照GBK进行解析的,到解析到最后,遇到ad 20,发现找不到GBK中对应的字符,就把ad 20用3f(?),替代。
QString接收到的字符序列变为:
e4 b8 ad e6 96 87 e4 b8 3f
所以,QString接收到的utf-8序列最后一个字节被改掉了,最后一个字符就显示出了乱码了。
其实,文章的开头提到的第1种没有问题的情况,很有可能,程序比较简单,而中文字符出现的个数刚好是偶数。真是人品大爆发,在发生2次误解的情况下,得到了正确的结果。O(∩_∩)O哈哈~
四、总结
今天,我们介绍了各种字符编码,文件存储编码,VS编译器,以及QString对字符的处理。总算理顺了出现乱码的原因。最终的原因,就是Qt默认保存为utf-8不带bom的文件,而VS编译器对于utf-8文件解析过程中的偷懒,而错认为ANSI编码文件所致。Cocos2d-x中的乱码,相信小伙伴们也已经明白是怎么回事了。

















