













传感器融合是自动驾驶汽车的关键技术之一。这是自动驾驶汽车工程师都必须具备的技能。原因很简单:感知无处不在,无时无刻不在使用。
自动驾驶汽车通过4个关键技术工作:感知、定位、规划和控制。
传感器融合是感知模块的一部分。我们希望融合来自视觉传感器的数据,以增加冗余、确定性或利用多个传感器的优势。
传感器数据和融合
在感知步骤中,使用激光雷达、雷达和摄像头的组合来理解环境是很常见的。这3个传感器各有优缺点,使用它们可以帮助您拥有所有优点。

如上图所示:
- 摄像头擅长处理对象分类及理解场景。
- 作为一种飞行时间传感器,激光雷达非常适合估计距离。
- 雷达可以直接测量障碍物的速度。
在本文中,我们将学习融合激光雷达和摄像头,从而利用摄像头的分辨率、理解上下文和对物体进行分类的能力以及激光雷达技术来估计距离并查看3D世界。
摄像头:2d传感器
相机是一种众所周知的传感器,用于输出边界框、车道线位置、交通灯颜色、交通标志和许多其他东西。在任何自动驾驶汽车中,摄像头从来都不是问题。

如何使用这种2D传感器,并将其与3D传感器(如:激光雷达)一起应用于3D世界?
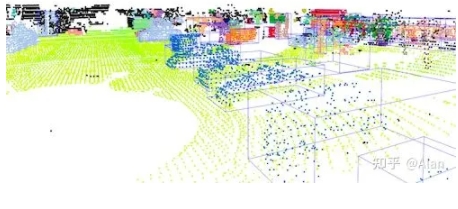
激光雷达:3d传感器
激光雷达代表光检测和测距。它是一个3D传感器,输出一组点云;每个都有一个(X,Y,Z)坐标。可以在3D数据上执行许多应用:包括运行机器学习模型和神经网络。下面是一个输出示例。
如何将此3D传感器与相机等2D传感器配合使用?
今天,我们介绍融合激光雷达和相机之间的数据。
传感器融合算法
传感器融合算法非常多。许多不同的方法都是可能的。“我们想要哪种类型的融合?”至关重要。
如文章所属,有3种方式来对融合算法分类:
- 按抽象级别:“何时”进行融合?when
- 按中心化级别:在“哪里”进行融合?where
- 按竞争级别:融合“什么”?what
“什么”很清楚:我们的目标是竞争和冗余。“在哪里”并不重要,很多解决方案都可以解决。剩下“何时”...
在传感器融合中,有两种可能的过程:
- 早期融合:融合原始数据--像素和点云。
- 后期融合:融合结果--来自激光雷达和相机的边界框。
在本文中,我们将研究这两种方法。
We then check whether or not the point clouds belong to 2D bounding boxes detected with the camera.
This 3-step process looks like this:
我们从早期融合开始。
早期传感器融合:融合原始数据
早期融合是融合来自传感器的原始数据的。因此,一旦插入传感器,该过程就会很快的发生。
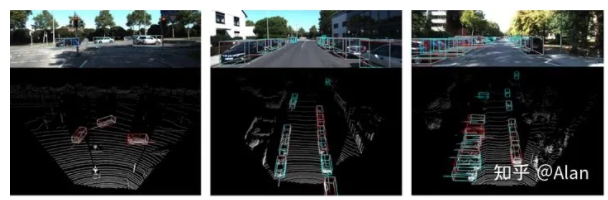
最简单和最常见的方法是将点云(3D)投影到2D图像上。然后检查点云和相机检测到的2D边界框的重合度。
这个3步过程如下所示:
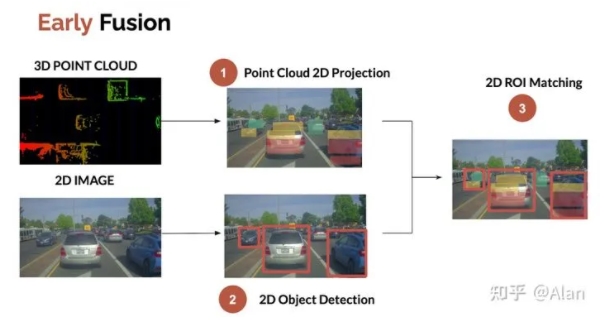
此过程已在此文中归类为低级别传感器融合。
1.点云投影到2D
第一个想法是将激光雷达帧中的3D点云转换为相机帧中的2D投影。为此,需要应用几何原理如下:
(输入点云在激光雷达帧/欧几里得坐标中。)
(1)将每个3D激光雷达点转换为齐次坐标。
输出:激光雷达帧/齐次坐标
(2)应用该转换点的投影方程(平移和旋转)将该点从激光雷达帧转换为相机帧。
输出:相机帧/齐次坐标
(3)最后,将点转换回欧几里得坐标。
输出:相机帧/欧几里得坐标
如果不熟悉投影、旋转和齐次坐标,可以学习立体视觉课程。
这是第1步的结果。

2.2D对象检测
下一部分是用相机检测物体。这部分不过多描述,像YOLOv4这样的算法可以执行对象检测。有关它的更多信息,可以阅读YOLOv4研究评论。
3.ROI匹配
最后一部分称为感兴趣区域匹配。我们将简单地融合每个边界框内的数据。
输出是什么?
- 对于每个边界框,相机给出分类结果。
- 对于每个激光雷达投影点,都有一个非常准确的距离。
➡️ 因此,我们得到了准确测量和分类的物体。
可能会出现一个问题:我们选择哪一点作为距离?
- 每个点的平均值?
- 中位数?
- 中心点?
- 最近的?
使用2D障碍物检测时,会遇到如下问题。如果我们选择的点属于另一个边界框怎么办?或者属于背景?这是一个棘手的过程。分割方法可能会更好,因为将点与像素精确匹配。
下面是结果的样子,箭头显示融合可能失败的点。

后期传感器融合:融合结果
后期融合是在独立检测后融合结果。
我们可以想到的一种方法是运行独立检测,在两端获得3D边界框,然后融合结果。
另一种方法是运行独立检测,得到两端的2D边界框,然后融合结果。
因此我们有两种可能;在2D或3D中进行融合。
下面是一个2D示例:

在本文中,我将介绍3D过程,因为它更难。相同的原则适用于2D。
过程如下所示:
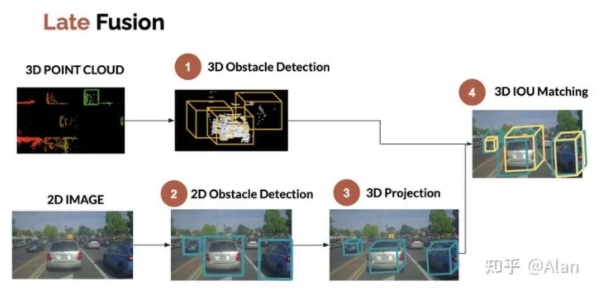
1.3D障碍物检测(激光雷达)
使用激光雷达在3D中寻找障碍物的过程是众所周知的。有两种方法:
朴素的方法,使用无监督的3D机器学习。
深度学习方法,使用RANDLA-NET等算法。
激光雷达课程这两种方法都有讲。
2.3D障碍物检测(相机)
这个过程要困难得多,尤其是在使用单目相机时。在3D中寻找障碍物需要我们准确地知道我们的投影值(内在和外在校准)并使用深度学习。如果我们想获得正确的边界框,了解车辆的大小和方向也至关重要。
本文是关于融合的文章,不介绍检测部分。可以查看文章。
最后,关注一下匹配。
Here's an example coming from the paper 3D Iou-Net (2020) .
3.IOU匹配
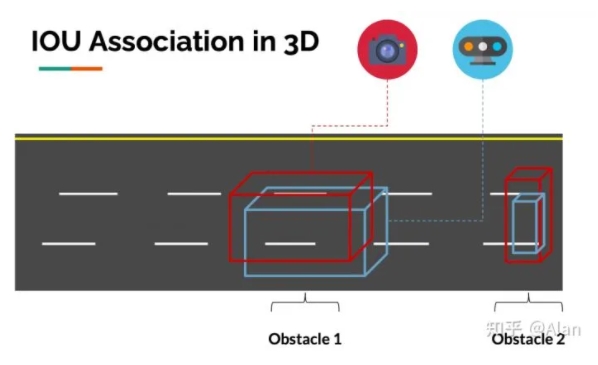
空间中的IOU匹配
匹配背后的过程非常简单:如果来自摄像头和激光雷达的边界框在2D或3D中重叠,我们认为障碍是相同的。
下面是来自论文3D Iou-Net(2020)的示例。
利用这个想法,我们可以将空间中的物体关联起来,从而在不同的传感器之间进行关联。
此过程在文章中归类为中级别传感器融合。
中级传感器融合和高级传感器融合的区别在于高级传感器的融合包括跟踪。
要添加时间跟踪,我们需要一个称为时间关联的类似过程。
时间上的IOU匹配
在障碍物追踪 课程中,讲了一种使用卡尔曼滤波器和匈牙利算法从帧到帧在时间上关联对象的技术。结果使我们能够在帧之间跟踪对象,甚至预测它们的下一个位置。
如下所示:

IOU匹配的原理完全一样:如果从第一帧到第二帧的边界框重叠,我们认为这个障碍物是相同的。
此处,我们跟踪边界框位置并使用IOU(Intersection Over Union)作为指标。我们还可以使用深度卷积特征来确保边界框中的对象是相同的--我们将此过程称为SORT(简单在线实时跟踪),如果使用卷积特征,则称为深度SORT。
由于我们可以在空间和时间中跟踪对象,因此我们还可以在这种方法中使用完全相同的算法进行高级传感器融合。
总结
我们现在已经研究了激光雷达和相机融合的两种方法。
让我们总结一下我们学到的东西:
传感器融合过程是关于融合来自不同传感器的数据,此处是激光雷达和摄像头。
可以有早期或后期融合--早期融合(低级传感器融合)是关于融合原始数据。后期融合是关于融合对象(中级传感器融合)或轨迹(高级传感器融合)
在做早期传感器融合时,要做点云和像素或者框的关联。
在进行后期传感器融合时,我们想要做结果(边界框)之间的关联,因此有诸如匈牙利算法和卡尔曼滤波器之类的算法来解决它。




























